This is the multi-page printable view of this section. Click here to print.
AgileTV CDN Solutions
- 1: Components
- 1.1: AgileTV CDN Director (esb3024)
- 1.1.1: Getting Started
- 1.1.2: Installation
- 1.1.2.1: Installing a 1.22 release
- 1.1.2.1.1: Configuration changes between 1.20 and 1.22
- 1.1.2.2: Installing a 1.20 release
- 1.1.2.2.1: Configuration changes between 1.18 and 1.20
- 1.1.2.3: Installing a 1.18 release
- 1.1.2.3.1: Configuration changes between 1.16 and 1.18
- 1.1.2.4: Installing a 1.16 release
- 1.1.2.4.1: Configuration changes between 1.14 and 1.16
- 1.1.2.5: Installing a 1.14 release
- 1.1.2.6: Installing a 1.12 release
- 1.1.2.7: Installing release 1.10.x
- 1.1.2.8: Installing release 1.8.0
- 1.1.2.9: Installing release 1.6.0
- 1.1.3: Firewall
- 1.1.4: API Overview
- 1.1.5: Configuration
- 1.1.5.1: WebUI Configuration
- 1.1.5.2: OLD WebUI Configuration
- 1.1.5.3: Confd and Confcli
- 1.1.5.4: Session Groups and Classification
- 1.1.5.5: Accounts
- 1.1.5.6: Data streams
- 1.1.5.7: Selection Input Configurations
- 1.1.5.8: Advanced features
- 1.1.5.8.1: Content popularity
- 1.1.5.8.2: Consistent Hashing
- 1.1.5.8.3: Security token verification
- 1.1.5.8.4: Subnets API
- 1.1.5.8.5: Lua Features
- 1.1.5.8.5.1: Built-in Lua Functions
- 1.1.5.8.5.2: Global Lua Tables
- 1.1.5.8.5.3: Request Translation Function
- 1.1.5.8.5.4: Session Translation Function
- 1.1.5.8.5.5: Host Request Translation Function
- 1.1.5.8.5.6: Response Translation Function
- 1.1.5.8.5.7: Sending HTTP requests from translation functions
- 1.1.5.9: Trusted proxies
- 1.1.5.10: Confd Auto Upgrade Tool
- 1.1.6: Operations
- 1.1.6.1: Services
- 1.1.6.2: Geographic Databases
- 1.1.7: Convoy Bridge
- 1.1.8: Monitoring
- 1.1.8.1: Access logging
- 1.1.8.2: System troubleshooting
- 1.1.8.3: Scraping data with Prometheus
- 1.1.8.4: Visualizing data with Grafana
- 1.1.8.4.1: Managing Grafana
- 1.1.8.4.2: Grafana Dashboards
- 1.1.8.5: Alarms and Alerting
- 1.1.8.6: Monitoring multiple routers
- 1.1.8.7: Routing Rule Evaluation Metrics
- 1.1.8.8: Metrics
- 1.1.8.8.1: Internal Metrics
- 1.1.9: Releases
- 1.1.9.1: Release esb3024-1.22.1
- 1.1.9.2: Release esb3024-1.22.0
- 1.1.9.3: Release esb3024-1.20.1
- 1.1.9.4: Release esb3024-1.18.0
- 1.1.9.5: Release esb3024-1.16.0
- 1.1.9.6: Release esb3024-1.14.2
- 1.1.9.7: Release esb3024-1.14.0
- 1.1.9.8: Release esb3024-1.12.1
- 1.1.9.9: Release esb3024-1.12.0
- 1.1.9.10: Release esb3024-1.10.2
- 1.1.9.11: Release esb3024-1.10.1
- 1.1.9.12: Release esb3024-1.10.0
- 1.1.9.13: Release esb3024-1.8.0
- 1.1.9.14: Release esb3024-1.6.0
- 1.1.9.15: Release esb3024-1.4.0
- 1.1.9.16: Release acd-router-1.2.3
- 1.1.9.17: Release acd-router-1.2.0
- 1.1.9.18: Release acd-router-1.0.0
- 1.1.10: Glossary
- 1.2: AgileTV Account Aggregator (esb3032)
- 1.2.1: Getting Started
- 1.2.2: Releases
- 1.2.2.1: Release esb3032-0.2.0
- 1.2.2.2: Release esb3032-1.0.0
- 1.2.2.3: Release esb3032-1.2.1
- 1.2.2.4: Release esb3032-1.4.0
- 1.3: AgileTV CDN Manager (esb3027)
- 1.3.1: Getting Started
- 1.3.2: System Requirements Guide
- 1.3.3: Architecture Guide
- 1.3.4: Installation Guide
- 1.3.4.1: Overview
- 1.3.4.2: Requirements
- 1.3.4.3: Quick Start Guide
- 1.3.4.4: Installation Guide
- 1.3.4.5: Upgrade Guide
- 1.3.4.6: Post Installation Guide
- 1.3.5: Configuration Guide
- 1.3.6: Networking
- 1.3.7: Storage Guide
- 1.3.8: Metrics and Monitoring
- 1.3.9: Operations Guide
- 1.3.10: Releases
- 1.3.10.1: Release esb3027-1.4.1
- 1.3.10.2: Release esb3027-1.4.0
- 1.3.10.3: Release esb3027-1.2.1
- 1.3.10.4: Release esb3027-1.2.0
- 1.3.10.5: Release esb3027-1.0.0
- 1.3.11: API Guides
- 1.3.11.1: Healthcheck API
- 1.3.11.2: Authentication API
- 1.3.11.3: Router API
- 1.3.11.4: Selection Input API
- 1.3.11.5: Operator UI API
- 1.3.12: Use Cases
- 1.3.12.1: Custom Deployments
- 1.3.13: Common Issues
- 1.3.14: Troubleshooting Guide
- 1.3.15: Glossary
- 1.4: AgileTV Cache (esb2001,esb3004)
- 1.5: BGP Sniffer (esb3013)
- 1.6: AgileTV Convoy Manager (classic) (esb3006)
- 1.7: Orbit CDN Request Router (esb3008)
- 2: Introduction
- 3: Solutions
- 3.1: Cache hardware metrics: monitoring and routing
- 3.2: Private CDN Offload Routing with DNS
- 3.3: Token blocking
- 3.4: Monitor ACD with Prometheus, Grafana and Alert Manager
- 4: Use Cases
- 4.1: Route on GeoIP/ASN
- 4.2: Route on Subnet
- 4.3: Route on Content Type
- 4.4: Route on Content Popularity
- 4.5: Route on Selection Input
- 4.6: Adapt to multi-CDN
- 4.7: How to use ACD router for EDNS routing
- 4.8: How to use ESB3024 Router with Orbit Request Router
- 4.9: How to use ESB3024 Router with CoreDNS
- 4.10: How to use the Director as a replacement for Orbit Request Router
- 4.11: Use In-Stream Sessions
- 5: Ready for Production?
- 5.1: Setup for Redundancy
- 5.2: HTTPS Certificates
1 - Components
1.1 - AgileTV CDN Director (esb3024)
1.1.1 - Getting Started
The Director serves as a versatile network service designed to redirect incoming HTTP(s) requests to the optimal host or Content Delivery Network (CDN) by evaluating various request properties through a set of rules. Although requests can be generic, the primary focus centers around audio-video content delivery. The rule engine allows users to construct routing configurations using predefined blocks, providing for the creation of intricate routing logic. This modular approach allows the users to tailor and streamline the content delivery process to meet their specific needs. The Director’s flexible rule engine takes into account factors such as geographical location, server load, content type, and other metadata from external sources to intelligently route incoming requests. It supports dynamic adjustments to seamlessly adapt to changing network conditions, ensuring efficient and reliable content delivery. The Director improves the overall user experience by delivering content from the most suitable and responsive sources, thereby reducing latency and enhancing performance.
Requirements
Hardware
The Director is designed to be installed and operated on commodity hardware, ensuring accessibility for a broad range of users. The minimum hardware specifications are as follows:
- CPU: x86-64 AMD or Intel with at least 2 cores.
- Memory: At least 2 GB free at runtime.
Operating System Compatibility
The Director is officially supported on Red Hat Enterprise Linux 8 or 9 or any
compatible operating system. In order to run the service, a minimum CPU
architecture of x86-64-v2 is required. This can be determined by running the
following command. If supported, it will be listed as “(supported)” in the
output.
/usr/lib64/ld-linux-x86-64.so.2 --help | grep x86-64-v2
External Internet access is necessary during the installation process for the installer to download and install additional dependencies. This ensures a seamless setup and optimal functionality of the Director on Red Hat Enterprise Linux 8 or 9. It’s worth noting that, due to the unique workings of the DNF package manager in Red Hat Enterprise Linux with rolling package streams, an air-gapped installation process is not available.
Firewall Recommendations
See Firewall.
Installation
See Installation.
Operations
See Operations.
Configuration Process
Once the router is operational, it requires a valid configuration before it can route incoming requests.
There are currently three methods available for configuring the router, each catering to different levels of complexity. The first is a Web UI, suitable for the most common use-cases, providing an intuitive interface for configuration. The second involves utilizing a confd REST service, complemented by an optional command line tool, confcli, suitable for all but the most advanced scenarios. The third method involves leveraging an internal REST API, ideal for the most intricate cases where using confd proves to be less flexible. It’s essential to note that as the configuration method advances through these levels, both flexibility and complexity increase, providing users with tailored options based on their specific needs and expertise.
API Key Management
Regardless of the method used to configure the system, a unique API key is
crucial for safeguarding the router’s configuration and preventing unauthorized
access to the API. This key must be supplied when interacting with the API.
During the router software installation, an automatically generated API key is
created and can be located on the installed system at
/opt/edgeware/acd/router/cache/rest-api-key.json. The structure of this file
is as follows:
{"api_key": "abc123"}
When accessing the internal configuration API, the key must be included in the
X-API-key header of the request, as shown below:
curl -v -k -H "X-API-Key: abc123" https://<router-host.example>:5001/v2/configuration
Modification to the authentication key and behavior can be done through the
/v2/rest_api_key endpoint. To change the key, a PUT request with a JSON body
of the same structure can be sent to the endpoint:
curl -v -k -X PUT -T new-key.json -H "X-API-Key: abc123" \
-H "Content-Type: application/json" https://<router-host.example>:5001/v2/rest_api_key
Additionally, key authentication can be disabled completely by sending a DELETE
request to the endpoint:
curl -v -k -X DELETE -H "X-API-Key: abc123" \
https://<router-host.example>:5001/v2/rest_api_key
In the event of a lost or forgotten authentication key, it can always be
retrieved at /opt/edgeware/acd/router/cache/rest-api-key.json on the
machine running the router. It is critical to emphasize that the API key should
remain private to prevent unauthorized access to the internal API, as it grants
full access to the router’s configuration.
Configuration Basics
Upon completing the installation process and configuring the API keys, the subsequent section will provide guidance on configuring the router to route all incoming requests to a single host. For straightforward CDN Offload use cases, there is a web based user interface described here.
For further details on configuring the router using confd and confcli, please consult the Confd documentation.
The initial step involves defining the target host group. In this illustration,
a singular group named all will be established, comprising two hosts.
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: host
Adding a 'host' element
hostGroup : {
name (default: ): all
type (default: host):
httpPort (default: 80):
httpsPort (default: 443):
hosts : [
host : {
name (default: ): host1.example.com
hostname (default: ): host1.example.com
ipv6_address (default: ):
}
Add another 'host' element to array 'hosts'? [y/N]: y
host : {
name (default: ): host2.example.com
hostname (default: ): host2.example.com
ipv6_address (default: ):
}
Add another 'host' element to array 'hosts'? [y/N]: n
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: n
]
Generated config:
{
"hostGroups": [
{
"name": "all",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "host1.example.com",
"hostname": "host1.example.com",
"ipv6_address": ""
},
{
"name": "host2.example.com",
"hostname": "host2.example.com",
"ipv6_address": ""
}
]
}
]
}
Merge and apply the config? [y/n]:
After defining the host group, the next step is to establish a rule that directs
incoming requests to the designated host. In this example, a sole rule named
random will be generated, ensuring that all incoming requests are consistently
routed to the previously defined host.
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: random
Adding a 'random' element
rule : {
name (default: ): random
type (default: random):
targets : [
target (default: ): host1.example.com
Add another 'target' element to array 'targets'? [y/N]: y
target (default: ): host2.example.com
Add another 'target' element to array 'targets'? [y/N]: n
]
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "random",
"type": "random",
"targets": [
"host1.example.com",
"host2.example.com"
]
}
]
}
Merge and apply the config? [y/n]:
The last essential step involves instructing the router on which rule should
serve as the entry point into the routing tree. In this example, we designate
the rule random as the entrypoint for the routing process.
$ confcli services.routing.entrypoint random
services.routing.entrypoint = 'random'
Once this configuration is defined, all incoming requests will initiate their
traversal through the routing rules, starting with the rule named random. This
rule is designed to consistently match for every incoming request, effectively load
balancing evenly between host1.example.com and host2.example.com on port 80
or 443, depending on whether the initial request was made using HTTP or HTTPS.
Integration with Convoy
The router is equipped with the capability to synchronize specific configuration metadata with a separate Convoy installation through the integrated convoy-bridge service. However, this service necessitates additional setup and configuration, and you can find comprehensive details on the process here..
Additional Resources
Additional documentation resources are included with the Director and can be
accessed at the following directory: /opt/edgeware/acd/documentation/. This
directory contains supplementary materials to provide users with comprehensive
information and guidance for optimizing their experience with the Director.
Ready for Production
Once the Director software is completely installed and configured, there are a few additional considerations before moving to a full production environment. See the section Ready for Production for additional information.
1.1.2 - Installation
1.1.2.1 - Installing a 1.22 release
To install ESB3024 Router, you first need to copy the installation ISO image to
the target node where the router will be run. Due to the way the installer
operates, it is necessary that the host is reachable by ssh from itself for
the user account that will perform the installation, and that this user has
sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has ssh access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.Ensure that
sshpassis installed.If the installer is run by the root user, this step is not necessary.
sshpassis installed by typing this:sudo dnf install -y sshpass
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.22.1.iso /mnt/acdRun the installer script.
/mnt/acd/installerIf it is not running as root, the installer will ask both for the “SSH password” and the “BECOME password”. The “SSH password” is the password that the user running the installer uses to log in to the local machine, and the “BECOME password” is the password for the user to gain
sudoaccess. They are usually the same.
Upgrading From an Earlier ESB3024 Router Release
The following steps can be taken to upgrade the router from a 1.10 or later release to 1.22.1. If upgrading from an earlier release it is recommended to first upgrade to 1.10.1 and then to upgrade to 1.22.1.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.22.1.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerPlease note that the installer will install new container images, but it will not remove the old ones. The old images can be removed manually after the upgrade is complete.
Migrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the previous versions is not directly compatible with 1.22, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
The
acd-confd-migrationtool will automatically apply any necessary schema migrations. Further details about this tool can be found at Confd Auto Upgrade Tool.The tool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.
The example below shows how to upgrade from 1.20.1. If upgrading from 1.18.0,
--from 1.20.1should be replaced with--from 1.18.0.The command line required to run the tool is different depending on which esb3024 release it is run on. On 1.22.1 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/acd-confd-migration:1.22.1 \ --in - --from 1.20.1 --to 1.22.1 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.1.1 - Configuration changes between 1.20 and 1.22
Confd configuration changes
Below are the changes to the confd configuration between versions 1.20 and 1.22 listed.
Removed services.routing.settings.usageLog.enabled
The services.routing.settings.usageLog.enabled setting has been removed. The
usage log is always enabled and this setting is no longer necessary.
Replaced forwardHostHeader with headersToForward
The services.routing.hostGroups.<name>.forwardHostHeader setting has been
replaced with services.routing.hostGroups.<name>.headersToForward, which is a
list of headers to forward to the origin server.
See CDNs and Hosts for more information.
Added selectionInputFetchBase
The integration.manager.selectionInputFetchBase setting has been added. It is
used to configure the base URL for fetching initial selection input from the
manager. See Selection Input Configurations for more information.
Added the requestHeader classifier
A new classifier, requestHeader, has been added. See Session
Classification for more
information.
Added patternSource to the subnet classifier
The subnet classifier has been extended with a new setting, patternSource.
See Session Classification for more
information.
1.1.2.2 - Installing a 1.20 release
To install ESB3024 Router, you first need to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice it is recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.20.1.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrading From an Earlier ESB3024 Router Release
The following steps can be taken to upgrade the router from a 1.10 or later release to 1.20.1. If upgrading from an earlier release it is recommended to first upgrade to 1.10.1 and then to upgrade to 1.20.1.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.20.1.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerPlease note that the installer will install new container images, but it will not remove the old ones. The old images can be removed manually after the upgrade is complete.
Migrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the previous versions is not directly compatible with 1.20, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
The
acd-confd-migrationtool will automatically apply any necessary schema migrations. Further details about this tool can be found at Confd Auto Upgrade Tool.The tool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.
The example below shows how to upgrade from 1.10.2. If upgrading from 1.14.0,
--from 1.10.2should be replaced with--from 1.14.0.The command line required to run the tool is different depending on which esb3024 release it is run on. On 1.20.1 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/acd-confd-migration:1.20.1 \ --in - --from 1.10.2 --to 1.20.1 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.2.1 - Configuration changes between 1.18 and 1.20
Confd configuration changes
Below are the changes to the confd configuration between versions 1.18 and 1.20 listed.
Added Kafka bootstrap server settings
The integration.kafka section has been added. It only contains
bootstrapServers, which is a list of Kafka bootstrap servers that the router
may connect to. The Kafka settings are described in the Data streams
section.
Added data streams settings
The services.routing.dataStreams section has been added. It contains
configuration for incoming and outgoing data streams in the incoming and
outgoing sections. See Data streams
for more information.
Added allowAnyRedirectType setting
A new setting, services.routing.hostGroups.<name>.allowAnyRedirectType, has
been added. It makes the Director interpret any 3xx response from a redirecting
as a redirect. See
CDNs and Hosts for more
information.
1.1.2.3 - Installing a 1.18 release
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice it is recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.18.0.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrading From an Earlier ESB3024 Router Release
The following steps can be taken to upgrade the router from a 1.10 or later release to 1.18.0. If upgrading from an earlier release it is recommended to first upgrade to 1.10.1 and then to upgrade to 1.18.0.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.18.0.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerPlease note that the installer will install new container images, but it will not remove the old ones. The old images can be removed manually after the upgrade is complete.
Migrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the previous versions is not directly compatible with 1.18, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
The
acd-confd-migrationtool will automatically apply any necessary schema migrations. Further details about this tool can be found at Confd Auto Upgrade Tool.The tool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.
The example below shows how to upgrade from 1.10.2. If upgrading from 1.14.0,
--from 1.10.2should be replaced with--from 1.14.0.The command line required to run the tool is different depending on which esb3024 release it is run on. On 1.18.0 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/acd-confd-migration:1.18.0 \ --in - --from 1.10.2 --to 1.18.0 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.3.1 - Configuration changes between 1.16 and 1.18
Confd Configuration Changes
Below are the changes to the confd configuration between versions 1.16 and 1.18 listed.
Added Content Popularity Settings
The services.routing.settings.contentPopularity section has got the following
new settings.
popularityListMaxSizescoreBasedtimeBased
The new settings are described in the content popularity section.
1.1.2.4 - Installing a 1.16 release
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice it is recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.16.0.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade from and earlier ESB3024 Router release
The following steps can be taken to upgrade the router from a 1.10 or later release to 1.16.0. If upgrading from an earlier release it is recommended to first upgrade to 1.10.1 and then to upgrade to 1.16.0.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.16.0.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the previous versions is not directly compatible with 1.16, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
The
acd-confd-migrationtool will automatically apply any necessary schema migrations. Further details about this tool can be found at Confd Auto Upgrade Tool.The tool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.
The example below shows how to upgrade from 1.10.2. If upgrading from 1.14.0,
--from 1.10.2should be replaced with--from 1.14.0.The command line required to run the tool is different depending on which esb3024 release it is run on. On 1.16.0 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/acd-confd-migration:1.16.0 \ --in - --from 1.10.2 --to 1.16.0 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.4.1 - Configuration changes between 1.14 and 1.16
Confd configuration changes
Below are the changes to the confd configuration between versions 1.14 and 1.16 listed.
Added region GeoIP classifier
Classifiers of type geoip now have a region property.
Added integration.routing.gui configuration
There is now an integration.routing.gui section which will be used by the
GUI.
Added services.routing.accounts configuration
The services.routing.accounts list has been added to the configuration.
1.1.2.5 - Installing a 1.14 release
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice it is recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.14.0.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade from and earlier ESB3024 Router release
The following steps can be used to upgrade the router from a 1.10 or 1.12 release to 1.14.0. If upgrading from an earlier release it is recommended to first upgrade to 1.10.1 in multiple steps; for instance when upgrading from release 1.8.0 to 1.14.0, it is recommended to first upgrade to 1.10.1 and then to 1.14.0.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.14.0.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the previous versions is not directly compatible with 1.14, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
The
acd-confd-migrationtool will automatically apply any necessary schema migrations. Further details about this tool can be found at Confd Auto Upgrade Tool.The tool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.
The example below shows how to upgrade from 1.10.2. If upgrading from 1.12.0,
--from 1.10.2should be replaced with--from 1.12.0.The command line required to run the tool is different depending on which esb3024 release it is run on. On 1.14.0 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/acd-confd-migration:1.14.0 \ --in - --from 1.10.2 --to 1.14.0 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.5.1 - Configuration changes between 1.12.1 and 1.14
Confd configuration changes
Below are the changes to the confd configuration between versions 1.12.1 and 1.14.x listed.
Renamed services.routing.settings.allowedProxies
The configuration setting services.routing.settings.allowedProxies has been
renamed to services.routing.settings.trustedProxies.
Added services.routing.tuning.general.restApiMaxBodySize
This parameter configures the maximum body size for the REST API. It mainly applies to the configuration, which sometimes has a large payload size.
1.1.2.6 - Installing a 1.12 release
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice its recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.12.1.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade from ESB3024 Router release 1.10
The following steps can be used to upgrade the router from a 1.10 release to 1.12.0 or 1.12.1. If upgrading from an earlier release it is recommended to perform the upgrade in multiple steps; for instance when upgrading from release 1.8.0 to 1.12.1, it is recommended to first upgrade to 1.10.1 or 1.10.2 and then to 1.12.1.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.12.1.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in the 1.10 versions is not directly compatible with 1.12, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
To help with migrating the configuration, a new tool has been included in the 1.12.0 release, which will automatically apply any necessary schema migrations. Further details about this tool can be found here. Confd Auto Upgrade.
The
confd-auto-upgradetool takes as input the old configuration file, either by reading the file directly, or by reading from standard input, applies any necessary migrations between the two specified versions, and outputs a new configuration to standard output which is suitable for being applied to the upgraded system. While the tool has the ability to migrate between multiple versions at a time, the earliest supported version is 1.10.1.The example below shows how to upgrade from 1.10.2. If upgrading from 1.10.1,
--from 1.10.2should be replaced with--from 1.10.1.The command line required to run the tool is different if it is run on esb3024-1.12.0 or esb3024-1.12.1. On 1.12.1 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/auto-upgrade-esb3024-1.12.1-master:20240702T151205Z-f1b53a98f \ --in - --from 1.10.2 --to 1.12.1 \ | tee config_upgraded.jsonOn esb3024-1.12.0 it is run like this:
cat config_backup.json | \ podman run -i --rm \ images.edgeware.tv/auto-upgrade-esb3024-1.12.0:20240619T154952Z-2b72f7400 \ --in - --from 1.10.2 --to 1.12.0 \ | tee config_upgraded.jsonAfter running the above command, apply the new configuration to
confdby runningcat config_upgraded.json | confcli -i.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.6.1 - Configuration changes between 1.10.2 and 1.12
Confd configuration changes
Below are the major changes to the confd configuration between versions 1.10.2 and 1.12.0/1.12.1. Note that there are no configuration changes between versions 1.12.0 and 1.12.1, so the differences apply to both.
Added services.routing.translationFunctions.hostRequest
A new translation function has been added which will allow custom Lua code to modify requests to backend hosts before they are sent.
Added services.routing.translationFunctions.session
A new translation function has been added which will allow custom Lua code to be executed after the router has made the routing decision but before generating the redirect URL.
An example use case would be for enabling instream sessions, which can be done by
setting this value to return set_session_type('instream').
Removed services.routing.settins.managedSessions configuration
This configuration is no longger used.
Added services.routing.tuning.general.maxActiveManagedSessions tuning parameter.
This parameter configures the maximum number of active managed sessions.
1.1.2.7 - Installing release 1.10.x
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice its recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0This disables SELinux, but does not make the change persistent across reboots. To do that, edit the
/etc/selinux/configfile and set theSELINUXproperty todisabled.It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.10.1.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade from ESB3024 Router release 1.8.0
The following steps can be used to upgrade the router from release 1.8.0 to 1.10.x. If upgrading from an earlier release it is recommended to perform the upgrade in multiple steps; for instance when upgrading from release 1.6.0 to 1.10.x, it is recommended to first upgrade to 1.8.0 and then to 1.10.x.
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new release of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.10.1.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in version 1.8.0 is not directly compatible with 1.10.x, and may need to be converted. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
To determine if the configuration needs to be converted,
confclican be run like below. If it prints error messages, the configuration needs to be converted. If no error messages are printed, the configuration is valid and no further updates are necessary.confcli | head -n5 [2024-04-02 14:48:37,155] [ERROR] Missing configuration key /integration [2024-04-02 14:48:37,162] [ERROR] Missing configuration key /services/routing/settings/qoeTracking [2024-04-02 14:48:37,222] [ERROR] Missing configuration key /services/routing/hostGroups/convoy-rr/hosts/convoy-rr-1/healthChecks [2024-04-02 14:48:37,222] [ERROR] Missing configuration key /services/routing/hostGroups/convoy-rr/hosts/convoy-rr-2/healthChecks [2024-04-02 14:48:37,242] [ERROR] Missing configuration key /services/routing/hostGroups/e-dns/hosts/linton-dns-1/healthChecks { "integration": { "convoy": { "bridge": { "accounts": {If error messages are printed, the configuration needs to be converted. If the configuration was saved in the file
config_backup.json, the conversion can be done by typing this at the command line:sed -E -e '/"hosts":/,/]/ s/([[:space:]]+)("hostname":.*)/\1\2\n\1"healthChecks": [],/' -e '/"apiKey":/ d' config_backup.json | \ curl -s -X PUT -T - -H 'Content-Type: application/json' http://localhost:5000/config/__active/systemctl restart acd-confdThis adds empty
healthCheckssections to all hosts and removes theapiKeyconfiguration. After that,acd-confdis restarted. See Configuration changes between 1.8.0 and 1.10.x for more details about the configuration changes.Migrating configuration to esb3024-1.10.2
When upgrading to version 1.10.2, an extra step is required to migrate the consistent hashing configuration. This step is necessary both when upgrading from an earlier 1.10 release and when upgrading from older versions. It is only needed if consistent hashing was configured in the previous version.
To determine if consistent hashing was configured, execute the following command:
confcli | head -n2 [2024-05-31 09:43:55,932] [ERROR] Missing configuration key /services/routing/rules/constantine/hashAlgorithm { "integration": {If an error message about a missing configuration key appears, the configuration must be migrated. If no such error message appears, this step should be skipped.
To migrate the configuration, execute the following command at the command line:
curl -s http://localhost:5000/config/__active/ | \ sed -E 's/(.*)("type":.*"consistentHashing")(,?)/\1\2,\n\1"hashAlgorithm": "MD5"\3/' | \ curl -s -X PUT -T - -H 'Content-Type: application/json' http://localhost:5000/config/__active/This command will read the current configuration, add the
hashAlgorithmconfiguration key, and write back the updated configuration.Remove the Account Monitor container
Older versions of the router installed the Account Monitor tool. This was removed in release 1.8.0, but if it is still present and unused, it can be removed by typing:
podman rm account-monitorRemove the
confd-transformer.luafileAfter installing or upgrading to 1.10.x, ensure that the
confd-transformer.luascript located in/opt/edgeware/acd/router/lib/standard_luadirectory is removed.This file contains deprecated Lua language definitions which will override newer versions of those functions already present in the ACD Router’s Lua Standard Library. When upgrading beyond 1.10.2, the installer will automatically remove this file, however for this particular release, it requires manual intervention.
rm -f /opt/edgeware/acd/router/lib/standard_lua/confd-transformer.luaAfter removing this file, it will be necessary to restart the router to flush the definitions from the router’s memory:
systemctl restart acd-router
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.7.1 - Configuration changes between 1.8.0 and 1.10.x
Confd configuration changes
Below are the major changes to the confd configuration between version 1.8.0 and 1.10.x listed.
Added integration.convoy section
An integration.convoy section has been added to the configuration. It is
currently used for configuring the Convoy Bridge
service.
Removed services.routing.apiKey configuration
The services.routing.apiKey configuration key has been removed. This was an
obsolete way of giving the configuration access to the router. The key has to be
removed from the configuration when upgrading, otherwise the configuration will
not be accepted.
Added services.routing.settings.qoeTracking
A services.routing.settings.qoeTracking section has been added to the
configuration.
Added healthChecks sections to the hosts
The hosts in the hostGroup entries have been extended with a healthChecks
key, which is a list of functions that determine if a host is in good health.
For example, a redirecting host might look like this after the configuration has been updated:
{
"services": {
"routing": {
"hostGroups": [
{
"name": "convoy-rr",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"forwardHostHeader": true,
"hosts": [
{
"name": "convoy-rr-1",
"hostname": "convoy-rr-1",
"ipv6_address": "",
"healthChecks": [
"health_check('convoy-rr-1')"
]
}
]
}
],
Added hashAlgorithm to the consistentHashing rule
In esb3024-1.10.2 the consistentHashing routing rule has been extended with a
hashAlgorithm key, which can have the values MD5, SDBM and Murmur. The
default value is MD5.
1.1.2.8 - Installing release 1.8.0
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice its recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.8.0.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new version of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.2.0.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.The confd configuration used in version 1.6.0 is not directly compatible with 1.8.0, and may need to have a few minor manual updates in order to be valid. If this is not done, the configuration will not be valid and it will not be possible to make configuration changes.
To determine if the configuration needs to be manually updated,
confclican be run like below. If it prints error messages, the configuration needs to be updated. If no error messages are printed, the configuration is valid and no further updates are necessary.confcli services.routing | head [2024-02-01 19:05:10,769] [ERROR] Missing configuration key /services/routing/hostGroups/convoy-rr/forwardHostHeader [2024-02-01 19:05:10,779] [ERROR] Missing configuration key /services/routing/hostGroups/e-dns/forwardHostHeader [2024-02-01 19:05:10,861] [ERROR] 'forwardHostHeader'If error messages are printed, a
forwardHostHeaderconfiguration needs to be added to thehostGroupsconfiguration. This can be done by running this at the command line:curl -s http://localhost:5000/config/__active/ | \ sed -E 's/([[:space:]]+)"type": "(host|redirecting|dns)"(,?)/\1"type": "\2",\n\1"forwardHostHeader": false\3/' | \ curl -s -X PUT -T - -H 'Content-Type: application/json' http://localhost:5000/config/__active/This reads the active configuration from the router, adds the “forwardHostHeader” configuration to all host groups, and then sends the updated configuration back to the router.
See Configuration changes between 1.6.0 and 1.8.0 for more details about the configuration changes.
Remove the Account Monitor container
Previous versions of the router installed the Account Monitor tool. This is no longer included, but since the previous version installed, there will be a stopped Account Monitor container. If it is not used, the container can be removed by typing:
podman rm account-monitor
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.8.1 - Configuration changes between 1.6.0 and 1.8.0
Confd configuration changes
Below are some of the configuration changes between version 1.4.0 and 1.6.0 listed. The list only contains the changes that might affect already existing configuration, enirely new items are not listed. Normally nothing needs to be done about this since they will be upgraded automatically, but they are listed here for reference.
Added enabled to contentPopularity
An enabled key has been added to
services.routing.settings.contentPopularity. After the key has been added, the
configuration looks like this:
{
"services": {
"routing": {
"settings": {
"contentPopularity": {
"enabled": true,
"algorithm": "score_based",
"sessionGroupNames": []
},
...
Added selectionInputItemLimit to tuning
A selectionInputItemLimit key has been added to
services.routing.tuning.general. After the key has been added, the
configuration looks like this:
{
"services": {
"routing": {
"tuning": {
"general": {
...
"selectionInputItemLimit": 10000,
...
Added forwardHostHeader to hostGroups
All three hostGroup types (host, redirecting and dns) have been extended
with a forwardHostHeader key. For example, a redirecting host might look like
this after the change:
{
"services": {
"routing": {
"hostGroups": [
{
"name": "convoy-rr",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"forwardHostHeader": true,
"hosts": [
{
"name": "convoy-rr-1",
"hostname": "convoy-rr-1",
"ipv6_address": ""
}
]
}
],
...
REST API configuration changes
The following items have been added to the REST API configuration. They will not need to be manually updated, the router will add the new keys with default values. Note that this is not a complete list of all changes, it only contains the changes that will be automatically added when upgrading the router.
If the router is configured via confd and confcli, these changes will be
applied by them. This section is only relevant if the router is configured via
the v2/configuration API.
- Added the
session_translation_functionkey. - Added the
tuning.selection_input_item_limitkey.
1.1.2.9 - Installing release 1.6.0
To install ESB3024 Router, one first needs to copy the installation ISO image
to the target node where the router will be run. Due to the way the
installer operates, it is necessary that the host is reachable by
password-less SSH from itself for the user account that will perform the
installation, and that this user has sudo access.
Prerequisites:
Ensure that the current user has
sudoaccess.sudo -lIf the above command fails, you may need to add the user to the
/etc/sudoersfile.Ensure that the installer has password-less SSH access to
localhost.If using the
rootuser, thePermitRootLoginproperty of the/etc/ssh/sshd_configfile must be set to ‘yes’.The local host key must also be included in the
.ssh/authorized_keysfile of the user running the installer. That can be done by issuing the following as the intended user:mkdir -m 0700 -p ~/.ssh ssh-keyscan localhost >> ~/.ssh/authorized_keysNote! The
ssh-keyscanutility will result in the key fingerprint being output on the console. As a security best-practice its recommended to verify that this host-key matches the machine’s true SSH host key. As an alternative, to thisssh-keyscanapproach, establishing an SSH connection to localhost and accepting the host key will have the same result.Disable SELinux.
The Security-Enhanced Linux Project (SELinux) is designed to add an additional layer of security to the operating system by enforcing a set of rules on processes. Unfortunately out of the box the default configuration is not compatible with the way the installer operates. Before proceeding with the installation, it is recommended to disable SELinux. It can be re-enabled after the installation completes, if desired, but will require manual configuration. Refer to the Red Hat Customer Portal for details.
To check if SELinux is enabled:
getenforceThis will result in one of 3 states, “Enforcing”, “Permissive” or “Disabled”. If the state is “Enforcing” use the following to disable SELinux. Either “Permissive” or “Disabled” is required to continue.
setenforce 0It is recommended to reboot the computer after changing SELinux modes, but the changes should take effect immediately.
Assuming the installation ISO image is in the current working directory,
the following steps need to be executed either by root user or with sudo.
Mount the installation ISO image under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-esb3024-1.8.0.iso /mnt/acdRun the installer script.
/mnt/acd/installer
Upgrade
The upgrade procedure for the router is performed by taking a backup of the configuration, installing the new version of the router, and applying the saved configuration.
With the router running, save a backup of the configuration.
The exact procedure to accomplish this depends on the current method of configuration, e.g. if
confdis used, then the configuration should be extracted fromconfd, but if the REST API is used directly, then the configuration must be saved by fetching the current configuration snapshot using the REST API.Extracting the configuration using
confdis the recommend approach where available.confcli | tee config_backup.jsonTo extract the configuration from the REST API, the following may be used instead. Depending on the version of the router used, an API-Key may be required to fetch from the REST API.
curl --insecure https://localhost:5001/v2/configuration \ | tee config_backup.jsonIf the API Key is required, it can be found in the file
/opt/edgeware/acd/router/cache/rest-api-key.jsonand can be passed to the API by setting the value of theX-API-Keyheader.curl --insecure -H "X-API-Key: 1234abcd" \ https://localhost:5001/v2/configuration \ | tee config_backup.jsonMount the new installation ISO under
/mnt/acd.Note: The mount-point may be any accessible path, but
/mnt/acdwill be used throughout this document.mkdir -p /mnt/acd mount esb3024-acd-router-1.2.0.iso /mnt/acdStop the router and all associated services.
Before upgrading the router it needs to be stopped, which can be done by typing this:
systemctl stop 'acd-*'Run the installer script.
/mnt/acd/installerMigrate the configuration.
Note that this step only applies if the router is configured using
confd. If it is configured using the REST API, this step is not necessary.See Configuration changes between 1.4.0 and 1.6.0 for instructions on how to migrate the configuration to release 1.6.0.
Troubleshooting
If there is a problem running the installer, additional debug information can
be output by adding -v or -vv or -vvv to the installer command, the
more “v” characters, the more detailed output.
1.1.2.9.1 - Configuration changes between 1.4.0 and 1.6.0
confd configuration
The confd configuration used in version 1.4.0 is not directly compatible with
1.6.0, and will need to have a few minor updates in order to be valid. If this
is not done, the configuration will not be valid and it will not be possible to
make configuration changes. Running confcli will cause error messages and an
empty default configuration to be printed.
$ confcli services.routing.
[2023-12-12 16:08:07,120] [ERROR] Missing configuration key /services/routing/translationFunctions
[2023-12-12 16:08:07,122] [ERROR] Missing configuration key /services/routing/settings/instream/dashManifestRewrite/sessionGroupNames
[2023-12-12 16:08:07,122] [ERROR] Missing configuration key /services/routing/settings/instream/hlsManifestRewrite/sessionGroupNames
[2023-12-12 16:08:07,123] [ERROR] Missing configuration key /services/routing/settings/managedSessions
[2023-12-12 16:08:07,123] [ERROR] Missing configuration key /services/routing/tuning/target/recentDurationMilliseconds
{
"routing": {
"apiKey": "",
"settings": {
"allowedProxies": [],
"contentPopularity": {
"algorithm": "score_based",
"sessionGroupNames": []
},
"extendedContentIdentifier": {
...
The first thing that needs to be done is to rename the keys sessionGroupIds to
sessionGroupNames. If the configuration was backed up to the file
config_backup.json before upgrading, the keys can be renamed and the
updated configuration can be applied by typing this:
sed 's/"sessionGroupIds"/"sessionGroupNames"/' config_backup.json | confcli -i
[2023-12-19 12:33:17,725] [ERROR] Missing configuration key /services/routing/translationFunctions
[2023-12-19 12:33:17,726] [ERROR] Missing configuration key /services/routing/settings/instream/dashManifestRewrite/sessionGroupNames
[2023-12-19 12:33:17,727] [ERROR] Missing configuration key /services/routing/settings/instream/hlsManifestRewrite/sessionGroupNames
[2023-12-19 12:33:17,727] [ERROR] Missing configuration key /services/routing/settings/managedSessions
[2023-12-19 12:33:17,727] [ERROR] Missing configuration key /services/routing/tuning/target/recentDurationMilliseconds
The configuration has not yet been converted, so the error messages are still
printed. The configuration will be converted when the acd-confd service is
restarted.
systemctl restart acd-confd
This concludes the conversion of the configuration and the router is ready to be used.
Configuration changes
Below are all configuration changes between version 1.4.0 and 1.6.0 listed. Normally nothing needs to be done about this since they will be upgraded automatically, but they are listed here for reference.
Added translationFunctions block
services.routing.translationFunctions has been added. It can be added as a
map with two empty strings as values, to make the top of the configuration look
like this:
{
"services": {
"routing": {
"translationFunctions": {
"request": "",
"response": ""
},
...
Renamed sessionGroupIds to sessionGroupNames
The keys
services.routing.settings.instream.dashManifestRewrite.sessionGroupIds and
services.routing.settings.instream.hlsManifestRewrite.sessionGroupIds have
been renamed to
services.routing.settings.instream.dashManifestRewrite.sessionGroupNames and
services.routing.settings.instream.hlsManifestRewrite.sessionGroupNames
respectively. Any session group IDs need to be manually converted to session
group names.
After the conversion, the head of the configuration file might look like this:
{
"services": {
"routing": {
"apiKey": "",
"settings": {
"allowedProxies": [],
"contentPopularity": {
"algorithm": "score_based",
"sessionGroupNames": []
},
"extendedContentIdentifier": {
"enabled": false,
"includedQueryParams": []
},
"instream": {
"dashManifestRewrite": {
"enabled": false,
"sessionGroupNames": []
},
"hlsManifestRewrite": {
"enabled": false,
"sessionGroupNames": []
},
"reversedFilenameComparison": false
},
...
Added managedSessions block
A services.routing.settings.managedSessions block has been added. After
adding the block, the configuration might look like this:
{
"services": {
"routing": {
"apiKey": "",
"settings": {
"allowedProxies": [],
"contentPopularity": {
"algorithm": "score_based",
"sessionGroupNames": []
},
...
"managedSessions": {
"fraction": 0.0,
"maxActive": 100000,
"sessionTypes": []
},
"usageLog": {
"enabled": false,
"logInterval": 3600000
}
},
...
Added recentDurationMilliseconds
A services.routing.tuning.target.recentDurationMilliseconds key has been added
to the configuration file, with a default value of 500. After adding the key,
the configuration might look like this:
{
"services": {
"routing": {
"apiKey": "",
...
"tuning": {
"target": {
...
"recentDurationMilliseconds": 500,
...
Storing the updated configuration
After all these changes have been done to the configuration file, it can be
applied to the router using confcli.
confcli will still display error messages because the stored configuration is
not valid. They will not be displayed anymore after the valid configuration has
been applied.
$ confcli -i < updated_config.json
[2023-12-12 18:52:05,500] [ERROR] Missing configuration key /services/routing/translationFunctions
[2023-12-12 18:52:05,502] [ERROR] Missing configuration key /services/routing/settings/instream/dashManifestRewrite/sessionGroupNames
[2023-12-12 18:52:05,502] [ERROR] Missing configuration key /services/routing/settings/instream/hlsManifestRewrite/sessionGroupNames
[2023-12-12 18:52:05,503] [ERROR] Missing configuration key /services/routing/settings/managedSessions
[2023-12-12 18:52:05,511] [ERROR] Missing configuration key /services/routing/tuning/target/recentDurationMilliseconds
Raw configuration
The following changes have been made to the raw configuration. If the router is
configured via confd and confcli, these changes will be applied by them.
This section is only relevant if the router is configured via the
v2/configuration API.
Simple changes
The following keys were added or removed. They will not need to be manually updated, the router will add the new keys with default values.
- Removed the
tuning.repeated_session_start_threshold_secondskey. - Removed the
lua_pathskey. - Added the
tuning.target_recent_duration_millisecondskey.
EDNS proxy changes
If the router has been configured to use an EDNS server, the following has to be changed for the configuration to work.
The hosts.proxy_address key has been renamed to hosts.proxy_url and now
accepts a port that is used when connecting to the proxy.
The cdns.http_port and cdns.https_port keys now configure the port that is
used for connecting to the EDNS server, before they configured the port that is
used for connecting to the proxy.
1.1.3 - Firewall
For security reasons, the ESB3024 Installer does not automatically configure the local firewall to allow incoming traffic. It is the responsibility of the operations person to ensure that the system is protected from external access by placing it behind a suitable firewall solution. The following table describes the set of ports required for operation of the router.
| Application | Port | Protocol | Direction | Source | Description |
|---|---|---|---|---|---|
| Prometheus Alert Manager | 9093 | TCP | IN | internal | Monitoring Services |
| Confd | 5000 | TCP | IN | internal | Configuration Services |
| Router | 80 | TCP | IN | public | Incoming HTTP Requests |
| Router | 443 | TCP | IN | public | Incoming HTTPS Requests |
| Router | 5001 | TCP | IN | localhost | Access to router’s REST API |
| Router | 8000 | TCP | IN | localhost | Internal monitoring port |
| EDNS-Proxy | 8888 | TCP | IN | localhost | Proxy EDNS Requests |
| Grafana | 3000 | TCP | IN | internal | Monitoring Services |
| Grafana-Loki | 3100 | TCP | IN | internal | Log monitoring daemon |
| Prometheus | 9090 | TCP | IN | internal | Monitoring Service |
The “Direction” column represents the direction in which the connection is established.
IN- The connection is originated from an outside serverOUT- The connection is established from the host to an external server.
Once a connection is established through the firewall, bidirectional traffic must be allowed using the established connection.
For the “Source” column, the following terms are used.
internal- Any host or network which is allowed to monitor or operate the system.public- Any host or subnet that can access the router. This includes any customer network that will be making routing requests.localhost- Access can be limited to local connections only.any- All traffic from any source or to any destination.
Additional Ports
Convoy Bridge Integration
The optional convoy-bridge service needs the ability to access the Convoy MariaDB service, which by default runs on port 3306 on all of the Convoy Management servers. To allow this integration to run, port 3306/tcp must be allowed from the router to the configured Convoy Management node.
1.1.4 - API Overview
ESB3024 Router provides two different types of API:s:
- A content request API that is used by video clients to ask for content, normally using port 80 for HTTP and port 443 for HTTPS.
- A few REST API:s used by administrators to configure and monitor the router installation, using port 5001 over HTTPS by default.
The content API won’t be described further in this document, since it’s a simple HTTP interface serving content as regular files or redirect responses.
Raw configuration – /v2/configuration
Used to check and update the raw configuration of ESB3024 Router. Note that this API is considered an implementation detail and is not documented further.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
PUT | application/json | Success | 204 No Content | <N/A> |
PUT | application/json | Failure | 400 Bad Request | application/json1 |
Validate Configuration – /v2/validate_configuration
Used to determine if a JSON payload is correctly formatted without actually applying its configuration. A successful return status does not guarantee that the applied configuration will work, it only validates the JSON structure.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
PUT | application/json | Success | 204 No Content | <N/A> |
PUT | application/json | Failure | 400 Bad Request | application/json1 |
Example request
When an expected field is missing from the payload, the validation will show which one and return an appropriate error message in its payload:
$ curl -i -X PUT \
-d '{"routing": {"log_level": 3}}' \
-H "Content-Type: application/json" \
https://router.example:5001/v2/validate_configuration
HTTP/1.1 400 Bad Request
Access-Control-Allow-Origin: *
Content-Length: 132
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
"Configuration validation: Configuration parsing failed. \
Exception: [json.exception.out_of_range.403] (/routing) key 'id' not found"
Selection Input
The selection input API is used to inject user-defined data into the routing engine, making the data available for making routing decisions. Any JSON structures can be stored in the selection input.
One use case for selection input is to provide data on cache availability. For
example, if {"edge-streamer-2-online": true} is sent to the selection
input API, the routing condition eq('edge-streamer-2-online', true) can
be used to ensure that no traffic gets routed to the streamer if it’s offline.
/v3/selection_input
The /v3/selection_input API supports the GET, POST, PUT, and DELETE
methods.
PUTreplaces the data at the specified path with the provided data. If the path does not exist, it will be created.POSTis only used for appending data to arrays. The last element in the path must be an array. If the path does not exist, it will be created, with the last segment as an array.GETrequests fetch the current selection input data at the given path.DELETErequests remove the data at the given path.
Example PUT request
$ curl -i -X PUT \
-d '{"bitrate": 13000, "capacity": 50000}' \
-H "Content-Type: application/json" \
https://router.example.com:5001/v3/selection_input/hosts/host1
HTTP/1.1 201 Created
Access-Control-Allow-Headers: Content-Type, Authorization
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example.com-5fc78d
Example POST request
$ curl -i -X POST \
-d '"server1"' \
-H "Content-Type: application/json" \
https://router.example.com:5001/v3/selection_input/modules/allowed_servers
HTTP/1.1 201 Created
Access-Control-Allow-Headers: Content-Type, Authorization
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example.com-5fc78d
Example GET request
$ curl -i https://router.example.com:5001/v3/selection_input
HTTP/1.1 200 OK
Access-Control-Allow-Headers: Content-Type, Authorization
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Access-Control-Allow-Origin: *
Content-Length: 156
Content-Type: application/json
X-Service-Identity: router.example.com-5fc78d
{
"hosts": {
"host1": {
"bitrate": 13000,
"capacity": 50000
}
},
"modules": {
"allowed_servers": [
"server1"
]
}
}
Example DELETE request
$ curl -i -X DELETE \
https://router.example.com:5001/v3/selection_input/modules/allowed_servers
HTTP/1.1 204 No Content
Access-Control-Allow-Headers: Content-Type, Authorization
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example.com-5fc78d
/v1/selection_input
The /v1/selection_input API is retained only for backward compatibility with
legacy integrations.
When performing GET or DELETE requests, specific selection input values can
be accessed or deleted by including a path to the request. Note that not
specifying a path will select all selection input values. PUT requests do not
support supplying paths, the path to the element to be modified is deduced by
the keys in the provided JSON object.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
PUT | application/json | Success | 204 No Content | <N/A> |
PUT | application/json | Failure | 400 Bad Request | application/json |
GET | <N/A> | Success | 200 OK | application/json |
DELETE | <N/A> | Success | 204 No Content | <N/A> |
DELETE | <N/A> | Failure | 404 Not Found | <N/A> |
Example successful request (PUT)
$ curl -i -X PUT \
-d '{"host1_bitrate": 13000, "host1_capacity": 50000}' \
-H "Content-Type: application/json" \
https://router.example.com:5001/v1/selection_input
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example.com-5fc78d
Example unsuccessful request (PUT)
$ curl -i -X PUT \
-d '{"cdn-status": {"session-count": 12345, "load-percent" 98}}' \
-H "Content-Type: application/json" \
https://router.example.com:5001/v1/selection_input
HTTP/1.1 400 Bad Request
Access-Control-Allow-Origin: *
Content-Length: 169
Content-Type: application/json
X-Service-Identity: router.example.com-5fc78d
{
"error": "[json.exception.parse_error.101] parse error at line 1, column 57: \
syntax error while parsing object separator - \
unexpected number literal; expected ':'"
}
Example successful request (GET)
curl -i https://router.example.com:5001/v1/selection_input
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 129
Content-Type: application/json
X-Service-Identity: router.example.com-5fc78d
{
"host1_bitrate": 13000,
"host1_capacity": 50000
}
Example successful specific value request (GET)
curl -i https://router.example.com:5001/v1/selection_input/path/to/value
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 129
Content-Type: application/json
X-Service-Identity: router.example.com-5fc78d
1
Example successful request (DELETE)
curl -i -X DELETE https://router.example.com:5001/v1/selection_input
HTTP/1.1 204 OK
Access-Control-Allow-Origin: *
Content-Length: 129
X-Service-Identity: router.example.com-5fc78d
Example successful specific value request (DELETE)
curl -i -X DELETE https://router.example.com:5001/v1/selection_input/value/to/delete
HTTP/1.1 204 OK
Access-Control-Allow-Origin: *
Content-Length: 129
X-Service-Identity: router.example.com-5fc78d
Example unsuccessful request (DELETE)
curl -i -X DELETE https://router.example.com:5001/v1/selection_input/non/existent/value
HTTP/1.1 404 Not Found
Access-Control-Allow-Origin: *
Content-Length: 129
X-Service-Identity: router.example.com-5fc78d
Subnets – /v1/subnets
An API for managing named subnets that can be used for routing and block lists. See Subnets for more details.
PUT requests inject key value pairs with the form {<subnet>: <value>}, where
<subnet> is a valid CIDR string, into ACD, e.g.:
$ curl -i -X PUT \
-d '{"255.255.255.255/24": "area1", "1.2.3.4/24": "area2"}' \
-H "Content-Type: application/json" \
https://router.example:5001/v1/subnets
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
GET requests are used to fetch injected subnets, e.g.:
# Fetch all injected subnets
$ curl -i https://router.example:5001/v1/subnets
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 411
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"1.2.3.4/16": "area2",
"1.2.3.4/24": "area1",
"1.2.3.4/8": "area3",
"255.255.255.255/16": "area2",
"255.255.255.255/24": "area1",
"255.255.255.255/8": "area3",
"2a02:2e02:9bc0::/16": "area8",
"2a02:2e02:9bc0::/32": "area7",
"2a02:2e02:9bc0::/48": "area6",
"2a02:2e02:9de0::/44": "combined_area",
"2a02:2e02:ada0::/44": "combined_area",
"5.5.0.4/8": "area5",
"90.90.1.3/16": "area4"
}
DELETE requests are used to delete injected subnets, e.g.:
# Delete all injected subnets
$ curl -i https://router.example:5001/v1/subnets -X DELETE
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
Both GET and DELETE requests can be specified with the paths /byKey/ and
/byValue/ to filter which subnets to GET or DELETE.
# Fetch subnet with the CIDR string 1.2.3.4/8 if it exists
$ curl -i https://router.example:5001/v1/subnets/byKey/1.2.3.4/8
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 26
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"1.2.3.4/8": "area3"
}
# Fetch all subnets whose CIDR string begins with the IP 1.2.3.4
$ curl -i https://router.example:5001/v1/subnets/byKey/1.2.3.4
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 76
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"1.2.3.4/16": "area2",
"1.2.3.4/24": "area1",
"1.2.3.4/8": "area3"
}
# Fetch all subnets whose value equals 'area1'
$ curl -i https://router.example:5001/v1/subnets/byValue/area1
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 60
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"1.2.3.4/24": "area1",
"255.255.255.255/24": "area1"
}
# Delete subnet with the CIDR string 1.2.3.4/8 if it exists
$ curl -i https://router.example:5001/v1/subnets/byKey/1.2.3.4/8
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
# Delete all subnets whose CIDR string begins with the IP 1.2.3.4
$ curl -i https://router.example:5001/v1/subnets/byKey/1.2.3.4
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
# Delete all subnets whose value equals 'area1'
$ curl -i https://router.example:5001/v1/subnets/byValue/area1
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
PUT | application/json | Success | 204 No Content | <N/A> |
PUT | application/json | Failure | 400 Bad Request | application/json |
GET | <N/A> | Success | 200 OK | application/json |
GET | <N/A> | Failure | 400 Bad Request | application/json |
DELETE | <N/A> | Success | 204 No Content | application/json |
DELETE | <N/A> | Failure | 400 Bad Request | application/json |
Subrunner Resource Usage – /v1/usage
Used to monitor the load on subrunners, the processes performing those tasks that are possible to run in parallel.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
Example request
$ curl -i https://router.example:5001/v1/usage
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 1234
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"total_usage": {
"content": {
"lru": 0,
"newest": "-",
"oldest": "-",
"total": 0
},
"sessions": 0,
"subrunner_usage": {
[...]
}
},
"usage_per_subrunner": [
{
"subrunner_usage": {
[...]
}
},
[...]
]
}
Metrics – /m1/v1/metrics
An interface intended to be scraped by Prometheus. It is possible to scrape it manually to see current values, but doing so will reset some counters and cause actual Prometheus data to become faulty.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | text/plain |
Example request
$ curl -i https://router.example:5001/m1/v1/metrics
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 1234
Content-Type: text/plain
X-Service-Identity: router.example-5fc78d
# TYPE num_configuration_changes counter
num_configuration_changes 12
# TYPE num_log_errors_total counter
num_log_errors_total 0
# TYPE num_log_warnings_total counter
num_log_warnings_total{category=""} 123
# TYPE num_log_warnings_total counter
num_log_warnings_total{category="cdn"} 0
# TYPE num_log_warnings_total counter
num_log_warnings_total{category="content"} 0
# TYPE num_log_warnings_total counter
num_log_warnings_total{category="generic"} 10
# TYPE num_log_warnings_total counter
num_log_warnings_total{category="repeated_session"} 0
# TYPE num_ssl_errors_total counter
[...]
Node Visit Counters – /v1/node_visits
Used to gather statistics about the number of visits to each node in the routing tree. The returned value is a JSON object containing node ID names and their corresponding counter values.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
See Routing Rule Evaluation Metrics for more details.
Example request
$ curl -i https://router.example:5001/v1/node_visits
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 73
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"cache1.tv": "99900",
"offload": "100"
"routingtable": "100000"
}
Node Visit Graph – /v1/node_visits_graph
Creates a GraphML representation of the node visitation data that can be rendered into an image to make it easier to understand the data.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/xml |
See Routing Rule Evaluation Metrics for more details.
Example request
> curl -i -k https://router.example:5001/v1/node_visits_graph
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 731
Content-Type: application/xml
X-Service-Identity: router.example-5fc78d
<?xml version="1.0"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd">
<key id="visits" for="node" attr.name="visits" attr.type="string" />
<graph id="G" edgedefault="directed">
<node id="routingtable">
<data key="visits">100000</data>
</node>
<node id="cache1.tv">
<data key="visits">99900</data>
</node>
<node id="offload">
<data key="visits">100</data>
</node>
<edge id="e0" source="routingtable" target="cache1.tv" />
<edge id="e1" source="routingtable" target="offload" />
</graph>
</graphml>
Session list - /v1/sessions
Used to monitor the load on subrunners, the processes performing those tasks that are possible to run in parallel.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
Example request
$ curl -k -i https://router.example:5001/v1/sessions
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 12345
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"sessions": [
{
"age_seconds": 103,
"cdn": "edgeware",
"cdn_is_redirecting": false,
"client_ip": "1.2.3.4",
"host": "cdn.example:80",
"id": "router.example-5fc78d-00000001",
"idle_seconds": 103,
"last_request_time": "2022-12-02T14:05:05Z",
"latest_request_path": "/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
"no_of_requests": 1,
"requested_bytes": 0,
"requests_redirected": 0,
"requests_served": 0,
"session_groups": [
"all"
],
"session_groups_generation": 2,
"session_path": "/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
"start_time": "2022-12-02T14:05:05Z",
"type": "instream",
"user_agent": "libmpv"
},
[...]
]
}
Session details - /v1/sessions/<id: str>
Used to get details about a specific session from the above session list. The
id part of the URL corresponds to the id field in one of the
returned session entries in the above response.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
GET | <N/A> | Failure | 404 Not Found | application/json |
Example request
$ curl -k -i https://router.example:5001/v1/sessions/router.example-5fc78d-00000001
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 763
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"age_seconds": 183,
"cdn": "edgeware",
"cdn_is_redirecting": false,
"client_ip": "1.2.3.4",
"host": "cdn.example:80",
"id": "router.example-5fc78d-00000001",
"idle_seconds": 183,
"last_request_time": "2022-12-02T14:05:05Z",
"latest_request_path": "/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
"no_of_requests": 1,
"requested_bytes": 0,
"requests_redirected": 0,
"requests_served": 0,
"session_groups": [
"all"
],
"session_groups_generation": 2,
"session_path": "/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
"start_time": "2022-12-02T14:05:05Z",
"type": "instream",
"user_agent": "libmpv"
}
Content List - /v1/content
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
Example request
$ curl -k -i https://router.example:5001/v1/content
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 572
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"content": [
[
"/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
{
"cached_count": 0,
"content_requested": false,
"content_set": false,
"expiration_time": "2022-12-02T14:05:05Z",
"key": "/__cl/s:storage1/__c/v/f/0/5/v_sintel3v_f05a05f07d352e891d79863131ef4df7/__op/hls-default/__f/index.m3u8",
"listeners": 0,
"manifest": "",
"request_count": 4,
"state": "HLS:MANIFEST-PENDING",
"wait_count": 0
}
]
]
}
Lua scripts – /v1/lua/<path str>.lua
Used to upload, retrieve and delete custom named Lua scripts on the router.
Global functions in uploaded scripts automatically become available to Lua code
in the configuration (which effectively may be viewed as hooks). Upload a
script by PUTing a application/x-lua to the endpoint, and retrieve it by
GETing the endpoint without payload.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
PUT | application/x-lua | Success | 204 No Content | <N/A> |
PUT | application/x-lua | Failure | 400 Bad Request | application/json |
GET | <N/A> | Success | 200 OK | application/x-lua |
GET | <N/A> | Failure | 404 Not Found | application/json |
DELETE | <N/A> | Success | 204 No Content | <N/A> |
DELETE | <N/A> | Failure | 400 Bad Request | application/json |
DELETE | <N/A> | Failure | 404 Not Found | application/json |
Example request (PUT)
Save a Lua script under the name advanced_functions/f1.lua:
$ curl -i -X PUT \
-d 'function fun1() return 1 end' \
-H "Content-Type: application/x-lua" \
https://router.example:5001/v1/lua/advanced_functions/f1.lua
HTTP/1.1 204 Successfully saved Lua file
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
Example request (PUT, from file)
Upload an entire Lua file under the name advanced_functions/f1.lua:
First put your code in a file.
$ cat f1.lua
function fun1()
return 1
end
Then upload it using the --data-binary flag to preserve newlines
$ curl -i -X PUT \
--data-binary @f1.lua \
-H "Content-Type: application/x-lua" \
https://router.example:5001/v1/lua/advanced_functions/f1.lua
HTTP/1.1 204 Successfully saved Lua file
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
Example request (GET)
Request the Lua script named advanced_functions/f1.lua using a GET request:
$ curl -i https://router.example:5001/v1/lua/advanced_functions/f1.lua
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 28
Content-Type: application/x-lua
X-Service-Identity: router.example-5fc78d
function fun1() return 1 end
Example request (DELETE)
Delete the Lua script named advanced_functions/f1.lua using a DELETE request:
$ curl -i -X DELETE \
https://router.example:5001/v1/lua/advanced_functions/f1.lua
HTTP/1.1 204 Successfully removed Lua file
Access-Control-Allow-Origin: *
Content-Length: 0
X-Service-Identity: router.example-5fc78d
List Lua scripts – /v1/lua
Used to list previously uploaded custom Lua scripts on the router, retrieving their respective paths and file checksums.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
GET | <N/A> | Success | 200 OK | application/json |
Example request
$ curl -k -i https://router.example:5001/v1/lua
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 108
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
[
{
"file_checksum": "d41d8cd98f00b204e9800998ecf8427e",
"path": "advanced_functions/f1.lua"
}
]
Debug a Lua expression – /v1/lua/debug
Used to debug an arbitrary Lua expression on the router in a “sandbox” (with no visible side effects to the state of the router), and inspect the result.
The Lua expression in the body is evaluated inside an isolated copy of the
internal Lua environment including selection input. The stdout field of the
resulting JSON body is populated with a concatenation of every string provided
as argument to the Lua print() function during the course of evaluation.
Upon a successful evaluation, as indicated by the success flag,
return.value and return.lua_type_name capture the resulting Lua value.
Otherwise, if valuation was aborted (e.g. due to a Lua exception), error_msg
reflects any error description arising from the Lua environment.
| REQUEST Method | Content-Type | RESPONSE Result | Status Code | Content-Type |
|---|---|---|---|---|
POST | application/x-lua | Success | 200 OK | application/json |
Example successful request
$ curl -i -X POST \
-d 'fun1()' \
-H "Content-Type: application/x-lua" \
https://router.example:5001/v1/lua/debug
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 123
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"error_msg": "",
"return": {
"lua_type_name": "number",
"value": 1.0
},
"stdout": "",
"success": true
}
Example unsuccessful request
(attempt to invoke unknown function)
$ curl -i -X POST \
-d 'fun5()' \
-H "Content-Type: application/x-lua" \
https://router.example:5001/v1/lua/debug
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Content-Length: 123
Content-Type: application/json
X-Service-Identity: router.example-5fc78d
{
"error_msg": "[string \"function f0() ...\"]:2: attempt to call global 'fun5' (a nil value)",
"return": {
"lua_type_name": "",
"value": null
},
"stdout": "",
"success": false
}
Footnotes
1.1.5 - Configuration
1.1.5.1 - WebUI Configuration
The web-based user interface can be used to configure many common use cases for the CDN Director.
Normally the GUI is accessible from the CDN Manager at an address like
https://cdn-manager/gui/. After navigating to the UI, a login screen will be
presented:

Enter your credentials and log in.
Once logged in, the middle of the screen will present a few sections. Depending on your user’s permissions and licensed features, different options will be made available.
In the general case, two options will be presented:
- CDN Director
- Configuration Panel
At the top right corner is a user menu with an option to log out.
The left-hand side of the page shows a collapsible menu with a few icons:
 filters the menu options
filters the menu options used to return to the landing page
used to return to the landing page link to the
Director Routing rule configuration view
link to the
Director Routing rule configuration view link
to the Director configuration panel view
link
to the Director configuration panel view
CDN Director Routing
This view provides a graphical tree-based model for configuring how the Director should classify and route incoming content requests.
Menu Options
After navigating to the CDN Director Routing page, the left side will show a list of routing rule block types and host group variants. The user can drag and drop items from this list onto the main canvas in order to design a routing solution.
The Search component input field at the top can be used to search and filter
among the available components. Clicking the question mark next to a component
shows a description popup.

Title Bar
Above the main canvas is the title bar. On the left side is the name of the currently selected routing configuration and its creation date:

To the right are a series of buttons, from left to right:

Creates a grouping rectangle on the canvas. Any routing rules placed on this rectangle can be moved around together, making it easier to construct logical units. This is only a visual and practical effect, it doesn’t in any way change the generated configuration.

Opens a popup menu on the right-hand side of the canvas where various configuration options can be changed. A list of CDN Director instances to apply the configuration to can be found and modified here, as well as the general look and feel of the GUI.

Opens a display of the configuration JSON generated from the graphical representation and allows for editing the text directly. Any changes made will automatically be loaded into the graphical representation.
Automatically arranges all the blocks in the canvas, hopefully making it less messy. Routing decision flow begins from the top left and moves rightwards.

Pushes the currently active configuration onto all the configured CDN Director instances. Changes take effect immediately assuming they do not contain any errors and the GUI will display a dialog with the update results.

Saves the configuration to the listed CDN Director targets, with a name provided by the user. Previously saved configurations can be accessed by clicking the house icon next to the configuration title at the middle top of the canvas.
Note that merely saving a configuration does not make it take effect, it is just for making backups or alternative configurations.
To make a configuration take effect, you have to
Publishit.
Saved Configurations
Clicking the  icon in the title bar
navigates to the saved configurations section.
icon in the title bar
navigates to the saved configurations section.
The upper part of this section is a template list allowing the user to either start a new configuration from scratch by selecting “New configuration” or start from a skeleton configuration by selecting one of the available template tiles.
The lower part contains all stored configurations. First in the list is always the currently published configuration, followed by any user-created configurations that have been saved.
Each entry in the list contain information about its name, who created it and when it was last saved. Next to each saved configuration is a trash can button used to delete it.
Configuration Options
Clicking the icon opens a
panel with configuration options and settings on the right-hand side of the
screen. This panel has the two tabs Configurations and Style.
Configuration
The configuration tab allows the user to manage the CDN Director instances that are to be configured by the GUI.
Whenever a user pushes either Publish or Save version, the configuration
will be sent to routers configured in this list.
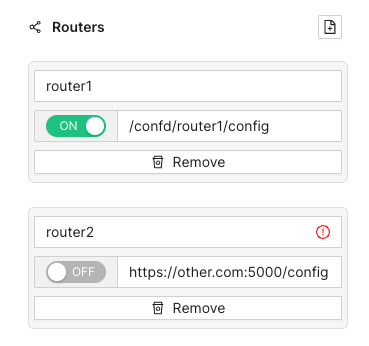
Each entry has a name, an address and a radio button to disable publication to specific instances that are e.g. taken out for maintenance. Turning a Director off won’t affect the current running status of that instance, it will only disable pushing any new configuration to it.
As seen above, the address can be either a full URL with scheme, hostname, port
and path such as http://router1.example.com:5000/config or a relative path
used e.g. to push configurations through an CDN Manager node:
/confd/router1/config.
Style Options
This pane contains various settings for the look and feel of the routing configuration view. The user can change line width and stroke type as well as colors associated with different node types.
Arrange Button
This button will automatically arrange the routing nodes in the canvas, trying to make the connections easier to follow.
Imagine a user has designed the routing flow organically, placing components anywhere on the screen as their need arose. This can make it difficult to get an overview.
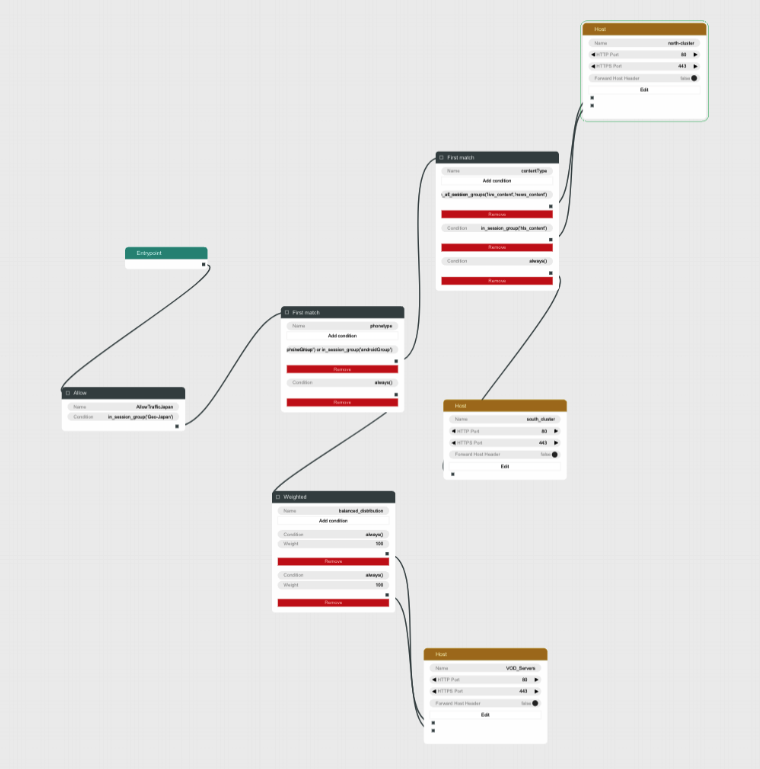
Clicking the Arrange button makes the GUI suggest a more structured
arrangement:
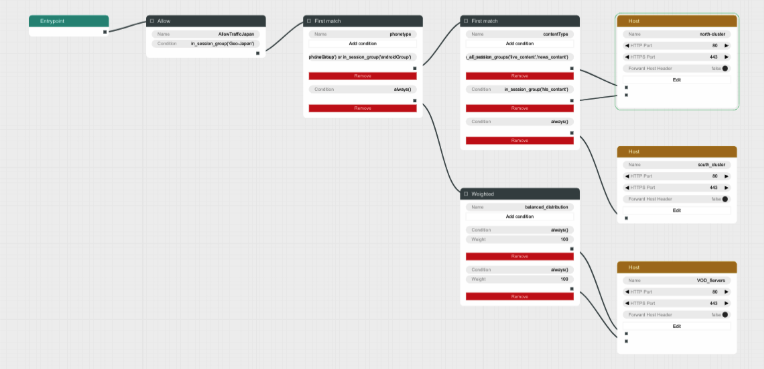
Save Version Button
Sometimes it can be useful to save a copy of a configuration, either because you need to try an entirely different design, or because you want to store a working setup before tweaking it to make sure you can revert to a working state in case anything goes wrong.
Clicking the Save version button opens a dialog box allowing you to pick a
name and save the currently displayed configuration to all the linked CDN
Director instances without activating it.
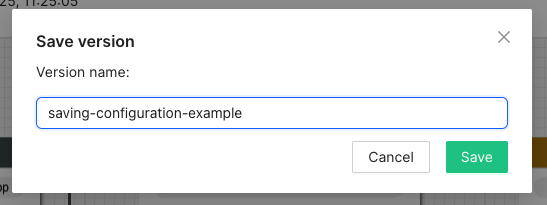

Going back to the saved configurations list, the new entry has appeared:
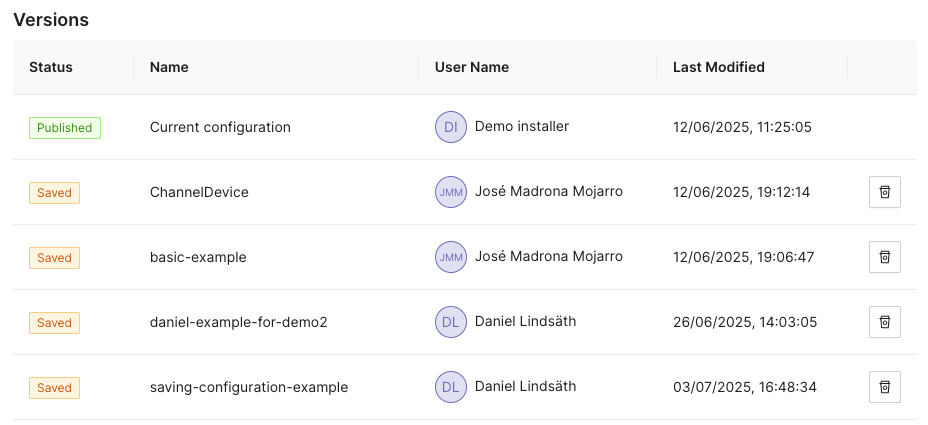
Publish Button
Clicking the Publish button sends the currently displayed configuration to be
sent to all enabled CDN Director instances. If it contains a complete and valid
configuration the Directors will then apply any changes.
A dialog box will display the publish status for each configured Director:

Configuration Panel
The configuration panel view allows for configuring routing-adjacent features, such as blocked/allowed referral addresses, blocked/allowed user agent strings or CDN host capacity values.
At the moment there are two supported configurations: Blocked tokens and blocked referrers.
Tokens
Selecting Tokens allows the user to observe and edit a list of currently
blocked tokens:
Several actions are available at this point:

Add a new token string to be blocked, along with a corresponding time-to-live (TTL) value in seconds.
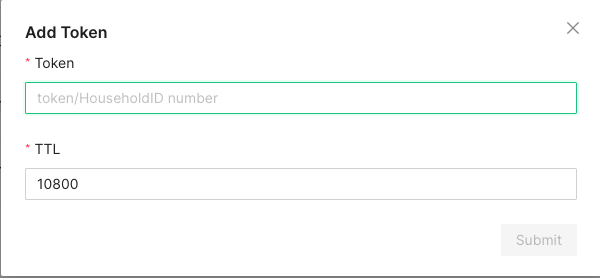
A newly added token will automatically be removed after TTL seconds, to avoid filling up the database with outdated or stale values.

In order to avoid performance hits when there are many tokens, nothing is shown in this list until a search string is entered manually by the operator. This is because a token is added to the list every time a valid token request is made and the database can grow to millions of entries.
At least three characters must be entered for searching to begin. A maximum of 100 results are shown. Write more specific search strings to filter out irrelevant token entries.
Note that token-reuse blocking depends on there being a Routing node, e.g. a
Denyblock, with a suitable condition function that performs the token extraction and blocking.
Referrers
This section allows for blocking specific referrer addresses. Unlike the token list, this table will display entries immediately since it is not anticipated to contain nearly as many entries.
Like with the token list, at most 100 entries are shown at a time. Use the search box to find the relevant referrers if the list is full.

Clicking the button will open a window to add a new referrer string to the block list. Clicking the ‘X’ closes the window without adding a new entry.

The search box filters which already-added referrer strings are displayed in the list. At least three characters must be written for filtering to begin, and regardless of how many matching results there are, only 100 will be displayed in the list so it is recommended to be as specific as necessary when searching.

Clicking the trash can next to a referrer removes it from the list of blocked referrers.
Example Routing Configuration
The following text will describe how to set up a simple routing system that has an internal CDN with two streaming servers and one external CDN.
The internal CDN is meant for serving live TV with low latency as well as VOD traffic provided there is enough capacity left without overloading the servers and affect live traffic latency.
In order to demonstrate the Director’s traffic filtering capability the setup will also send any mobile traffic from outside of Stockholm, Sweden to the external CDN.
Finally, a load balancing node is added to split the remaining incoming requests equally between the two internal hosts.
In summary, the configuration will:
- Route off-net traffic from mobile phones to the external CDN.
- Route Live traffic to the external CDN if the internal CDN is overloaded.
- Route any remaining traffic to the internal CDN.
Step-by-Step Walkthrough
When creating a new configuration the only thing that exists is an Entrypoint
node. This node is used to indicate where the routing engine should begin
traversing the routing tree for a new incoming request.
Begin by dragging a Split node onto the canvas and connect it to the
Entrypoint.
A Split node splits the incoming traffic into two separate streams based on
a condition. The default condition is a function called always() that
evaulates as true for any request. This is not very useful for this example,
replace it by clicking on the Condition input field in the node.
This brings us to a dialog box where we can simply replace the condition with
another string or go to a graphical representation of the condition to help
guide us through the steps to getting the Split node to do what we need.
Graphical Condition Builder
Clicking the Graphical View button opens up the graphical representation which
currently shows two condition nodes connected together, one representing the
default condition always() previously mentioned, and one called Condition Output which is a target placeholder for the end result of the entire graph.
Output from one condition node is connected to the input of another node until
the entire chain ends up with the Condition Output node.

On the left-hand side is a menu with the items Session Groups, Conditions
and Classifiers. The Conditions section contains different condition
components whose outputs can be connected to either other condition nodes or
the Condition Output.
Delete the Always node and replace it with one from the Conditions menu,
specifically In Session Group, and connect its output to Condition Output.
The new condition node takes a Session Group as its input. Drag one of those
from the menu onto the canvas and connect its output to the input labeled
“Session Group”. Give the Session Group node the name “mobile-off-net” since
it is going to contain requests from mobile units outside of the main network.
The Session Group takes a number of classifiers as inputs. Open the
Classifiers section of the menu and drag a Geo IP and a User Agent node
onto the canvas and connect their outputs to the Session Group. Note that
when one classifier is connected, the connection label is updated with its name
and a new empty connection slot is added.
Fill in the two classifier nodes with appropriate values:
Give the Geo IP node the name “off-net”, set Continent to “Europe”,
Country to “Sweden” and City to “Stockholm”. Finally, change the Inverted
toggle to true since we want this condition to match any traffic that comes
from anywhere but Stockholm.
The User Agent node is meant to match mobile devices, but for simplicity’s
sake this classifier is limited to Apple devices for this example. Set the name
to “mobile”, make sure Pattern Type is “stringMatch” and set the pattern to
“apple”. The asterisks will match against any strings at the beginning and end
of the user agent string, and “apple” is case insensitive.
The resulting graph should look like this:
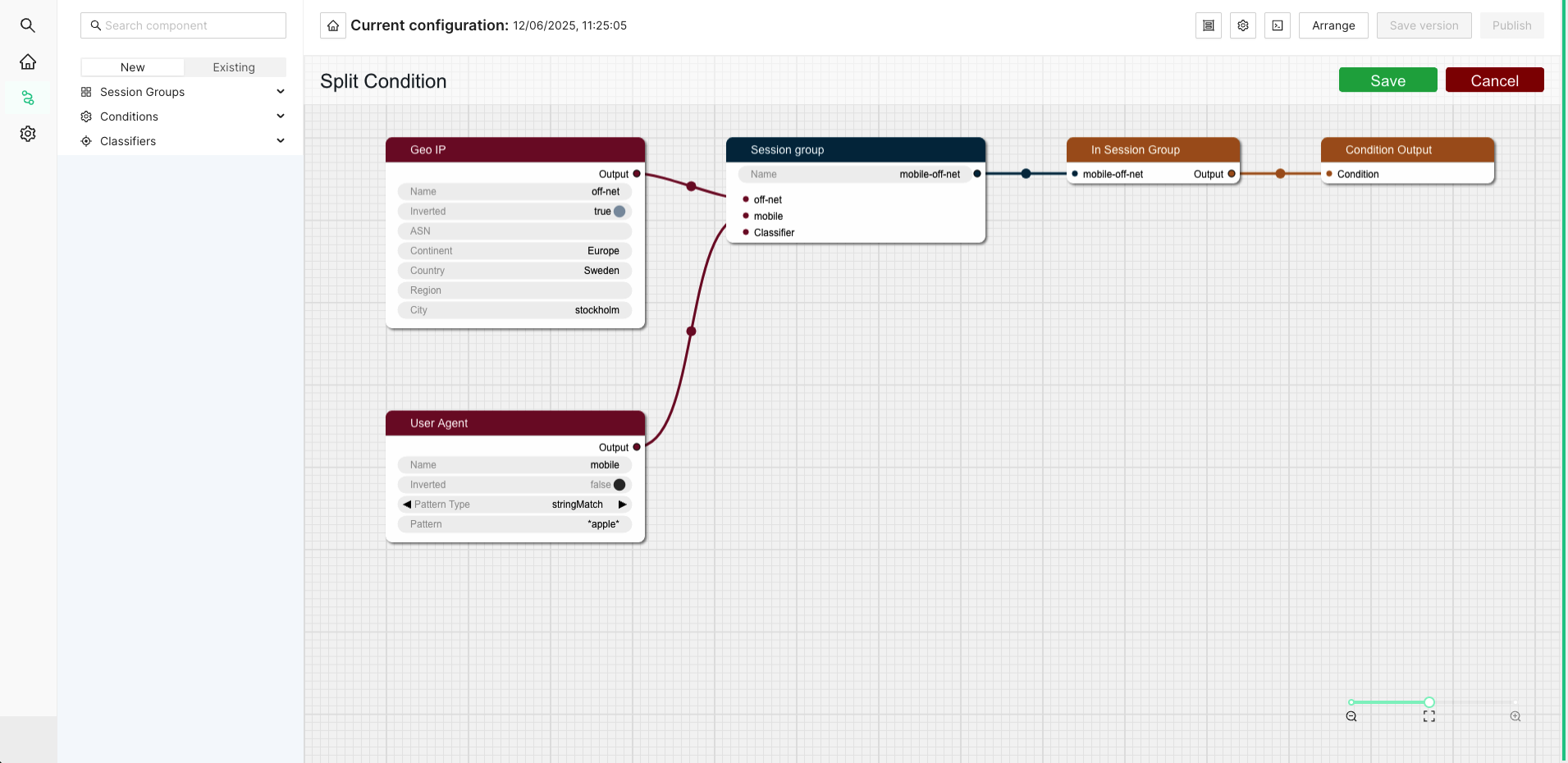
Click Save to return to the routing tree configuration view. Note that
"always()" has been replaced with "in_session_group('mobile-off-net')".
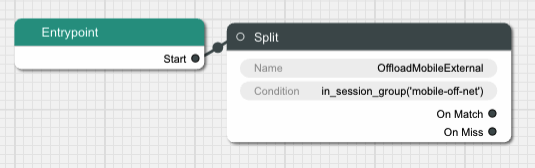
It is time to add a node for the external CDN. Open up the Hosts section in
the left-hand side menu if it is closed. Then drag a Host node onto the
canvas and name it “OffloadCDN”.
This creates a host group which contains hosts which belong together and share common settings such as ports.
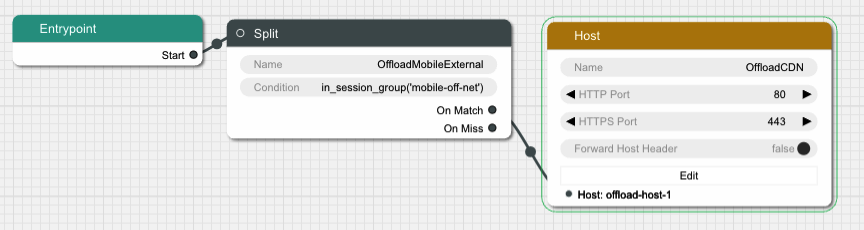
Click the Edit button to open a dialog where the actual hosts can be added to
the host group by clicking the icon with a new document on it. Add a host with
the name “offload-host-1” and address “offload-1.example.com”. The IPv6 address field can be left empty.
Click Save to return to the canvas view and connect the Split node’s
onMatch slot to the newly created host. Now any request that matches the
condition we added to the Split node will be sent to the external host.
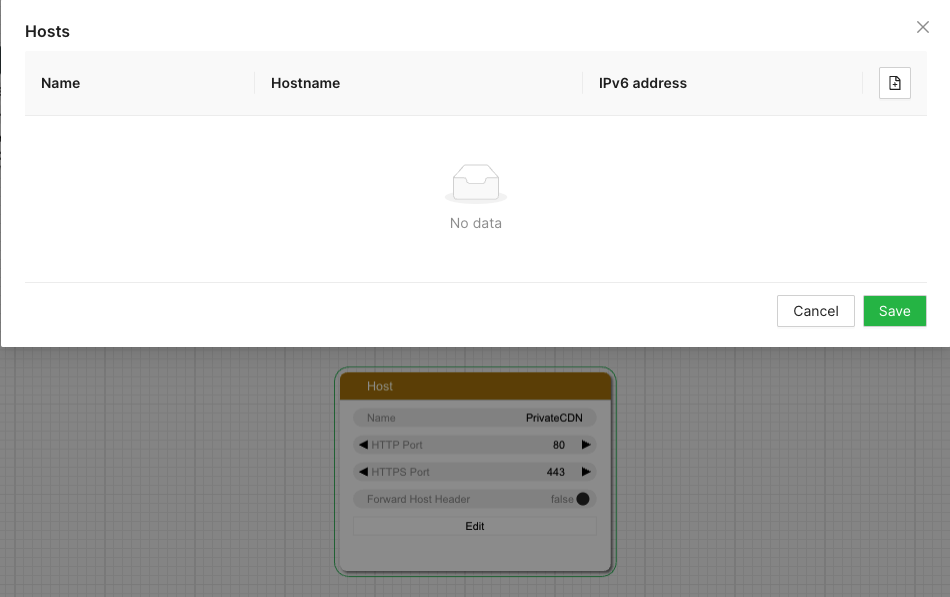
The next step is to add an offload in case the internal CDN is overloaded. Add
another Split node, call it “LiveOffload” and connect it to the previous
Split node’s onMiss slot. We will use a Selection Input
value named "live_bandwidth_left" to determine whether or not the internal CDN
is overloaded.
Click the Condition field and bring up the graphical view. Remove the
default Always node and replace it with a Less Than node. Set its Selection Input string to “live_bandwidth_left” and the Value to 100 in order to send
traffic to the offload CDN whenever the internal CDN reports less than 100
capacity left.
Save the condition and connect the Split node’s onMatch output to the
“offload-host-1” Host.
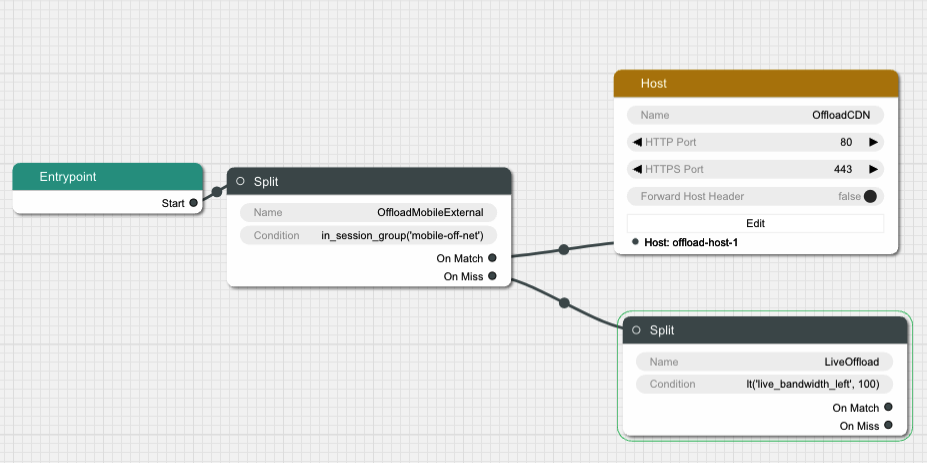
In order to balance the incoming Live traffic between the two internal CDN nodes
we create a Random node, which simply splits the traffic equally among its
targets.
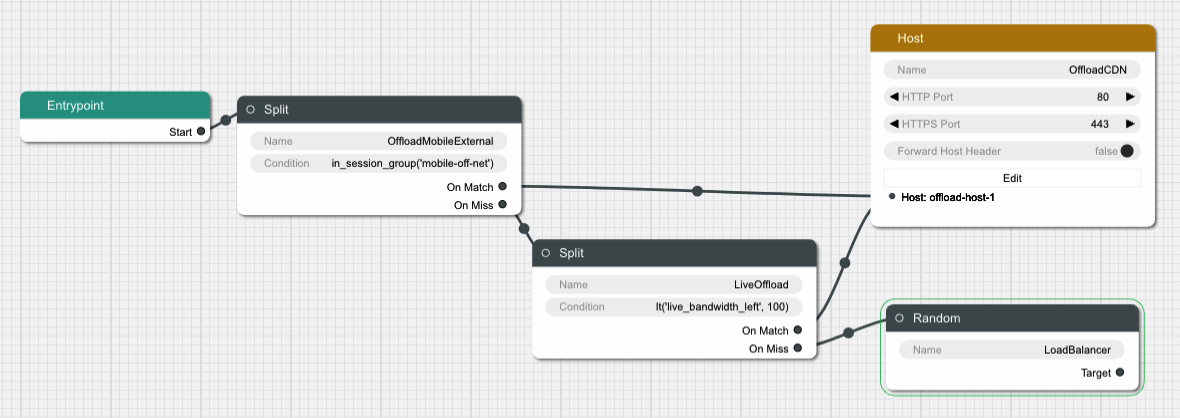
Finally we create another Host node and give it two hosts called
“private-host-1” and “private-host-2”. Connect the Random node to the two
hosts and the routing configuration is finished.
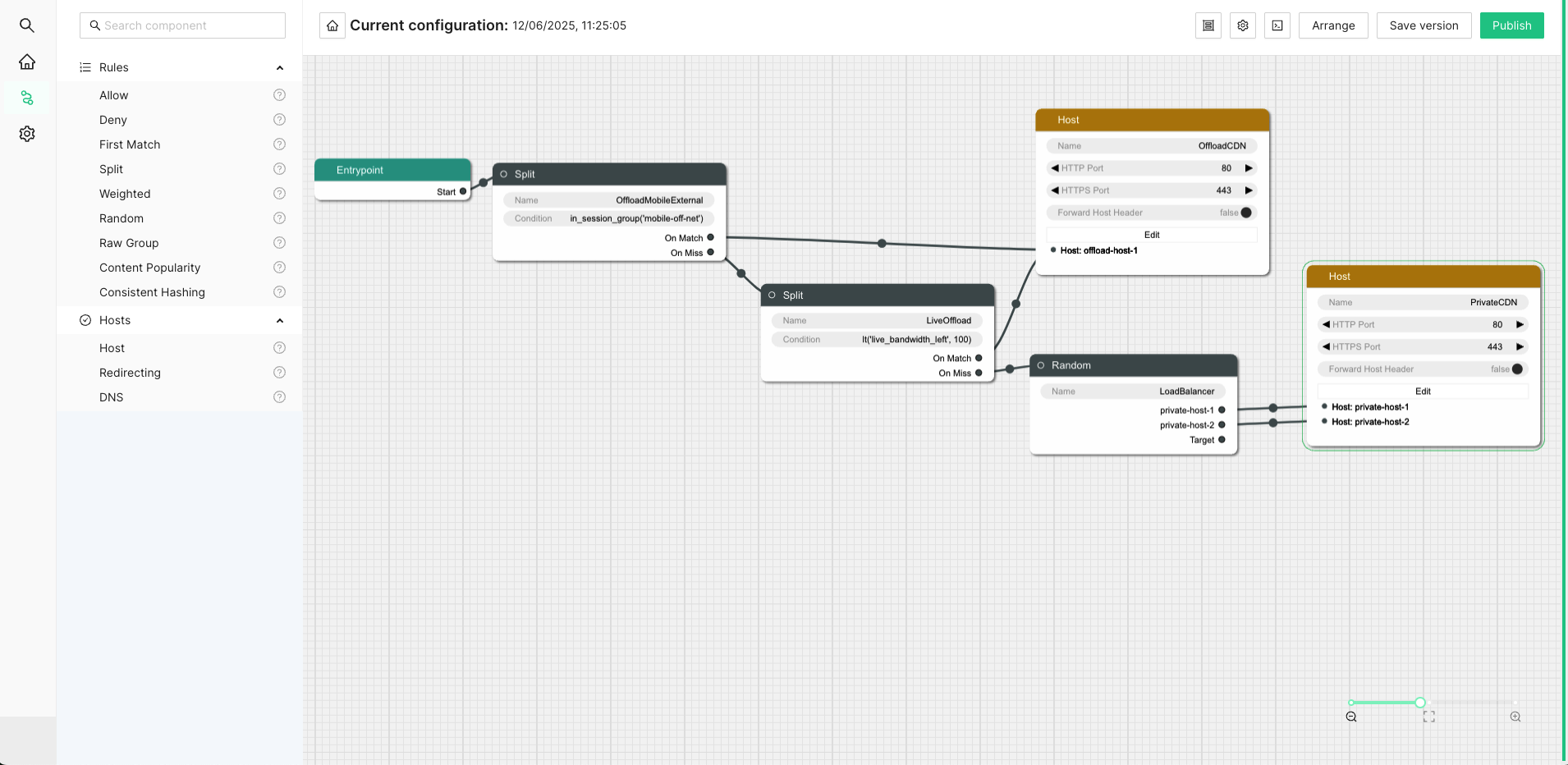
1.1.5.2 - OLD WebUI Configuration
The web based user interface is installed as a separate component and can be used to configure many common use cases. After navigating to the UI, a login screen will be presented.

Enter your credentials and log in. In the top left corner is a menu to select what section of the configuration to change. The configuration that will be active on the router is added in the Routing Workflow view. However, basic elements such as classification rules and routing targets, etc must be added first. Hence the following main steps are required to produce a proper configuration:
- Create classifiers serving as basic elements to create session groups.
- Create session groups which, using the classifiers, tag requests/clients for later use in the routing logic. of the incoming traffic.
- Define offload rules.
- Define rules to control behavior of internal traffic.
- Define backup rules to be used if the routing targets in the above step are unavailable.
- Finally, create the desired routing workflow using the elements defined in the previous steps.
A simplified concrete example of the above steps could be:
- Create two classifiers “smartphone” and “off-net”.
- Create a session group “mobile off-net”.
- Offload off-net traffic from mobile phones to a public CDN.
- Route other traffic to a private CDN.
- If the private CDN has an outage, use the public CDN for all traffic.
Hence, to start with, define the classifiers you will need. Those are based on information in the incoming request, optionally in combination with GeoIP databases or subnet information configured via the Subnet API. Here we show how to set up a GeoIP classifier. Note that the Director ships with a compatible snapshot of the GeoIP database, but for a production system a licensed and updated database is required.
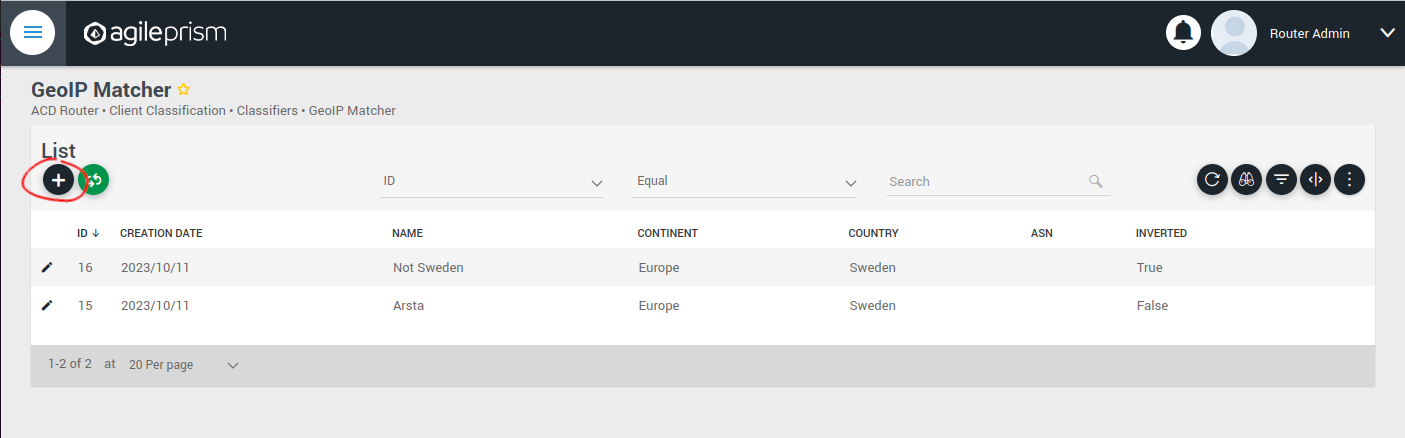
Click the plus sign indicated in the picture above to create a new GeoIP classifier. You will be presented with the following view:
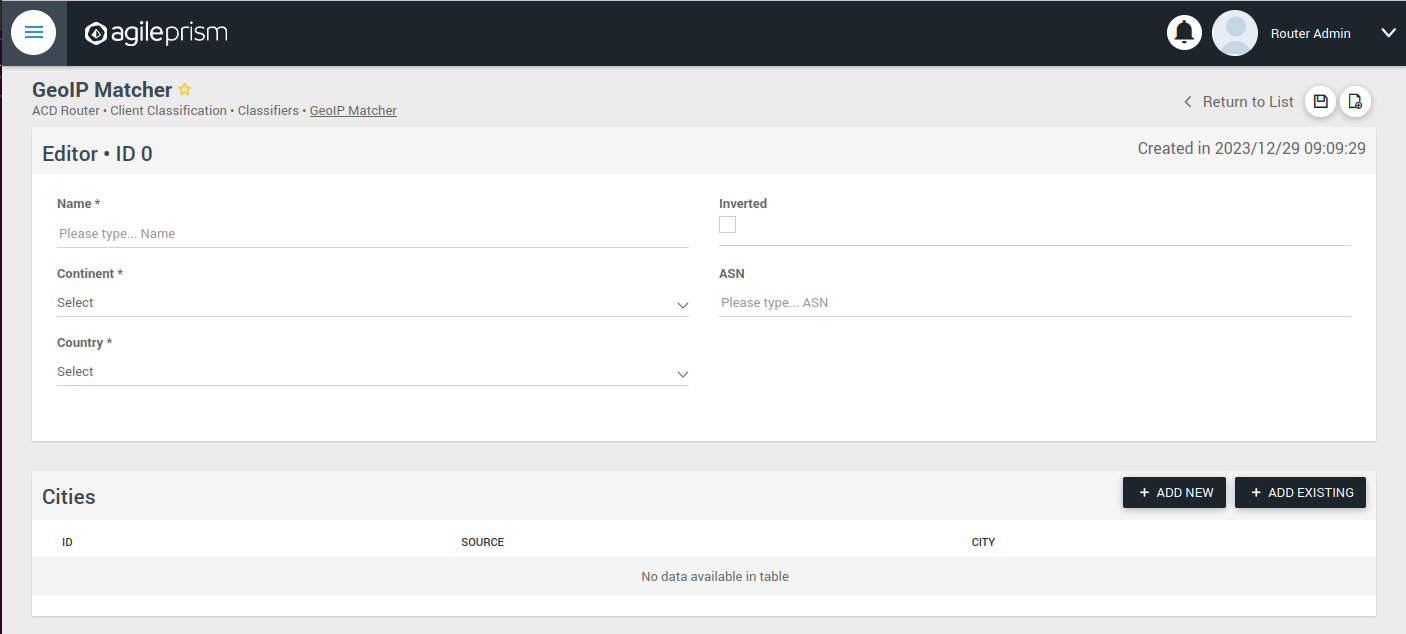
Here you can enter the geographical data on which to match, or check the “Inverted” check box to match anything except the entered geographical data.
The other kinds of classifiers are configured in a similar way.
After having added all the classifiers you need, it is time to create the session groups. Those are named filters that group incoming requests, typically video playback sessions in a video streaming CDN, and are defined with the help of the classifiers. For example, a session group “off-net mobile devices” could be composed of the classifiers “off-net traffic” and “mobile devices”.
Open the Session Groups view from the menu and hit the plus sign to add a new session group.

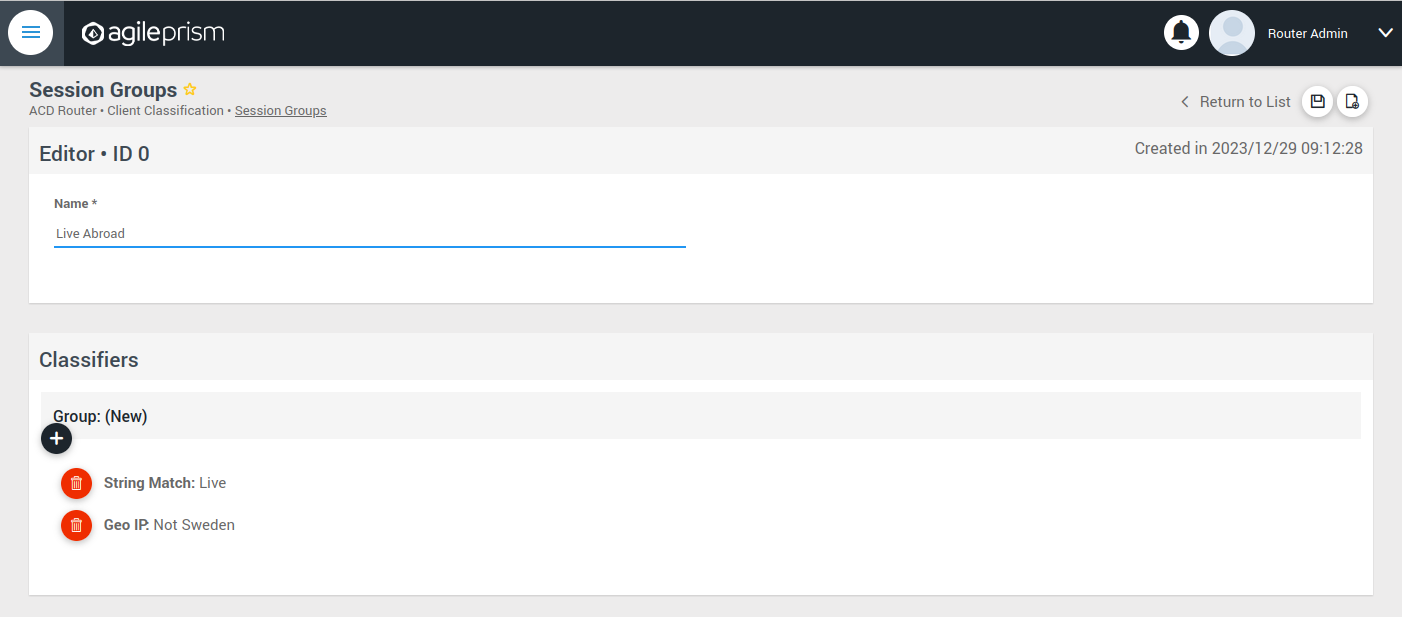
Define the new sessions groups by combining the previously created classifiers. It is often convenient to define an “All” session group that matches any incoming request.
Next go the “CDN Offload” view:
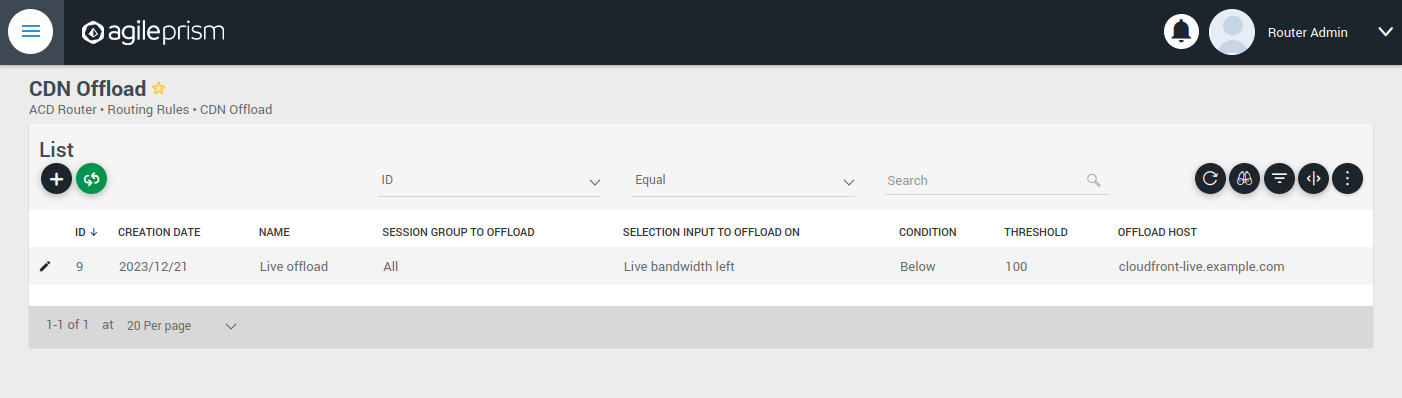
Here you define conditions for CDN offload. Each row defines a rule for offloading a specified session group. The rule makes use of the Selection Input API. This is an integration API that provides a way to supply additional data for use in the routing decision. Common examples are current bitrates or availability status. The selection input variables to use must be defined in the “Selection Input Types” view in the “Administration” section of the menu:

Reach out to the solution engineers from AgileTV in order to perform this integration in the best way. If no external data is required, such that the offload rule can be based solely based on session groups, this is not necessary and the condition field can be set to “Always” or “Disabled”.
When clicking the plus sign to add a new CDN Offload rule, the following view is presented:
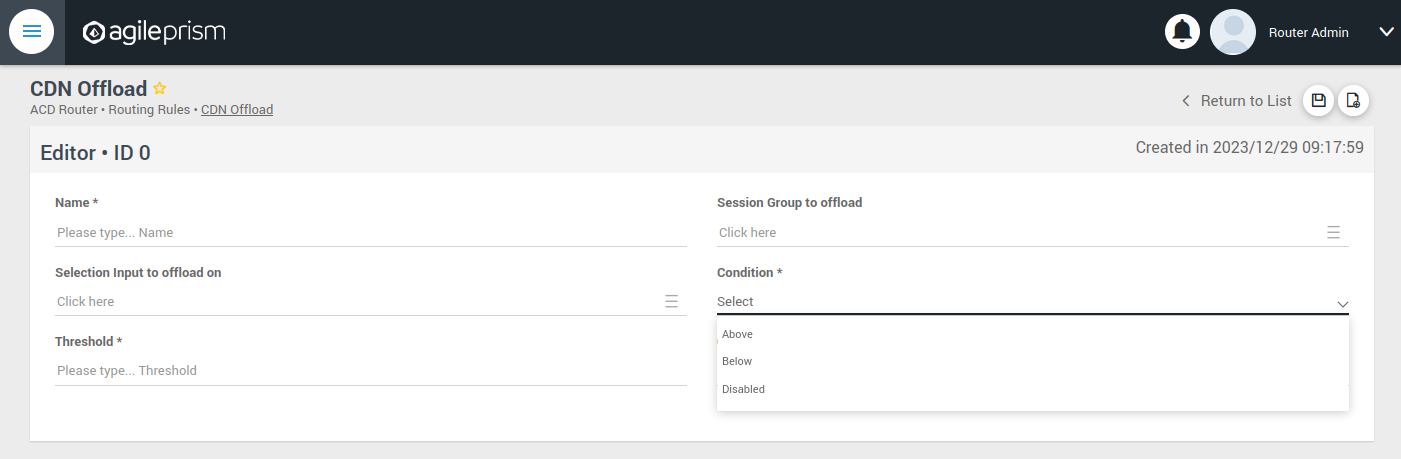
The selection input rule is phrased in terms of a variable being above or below a threshold, but also a state such as “available” taking values 0 or 1 can be supported by for instance checking if “available” is below 1.
Moving on, if an incoming request is not offloaded, it will be handled by the Primary CDN section of the routing configuration.
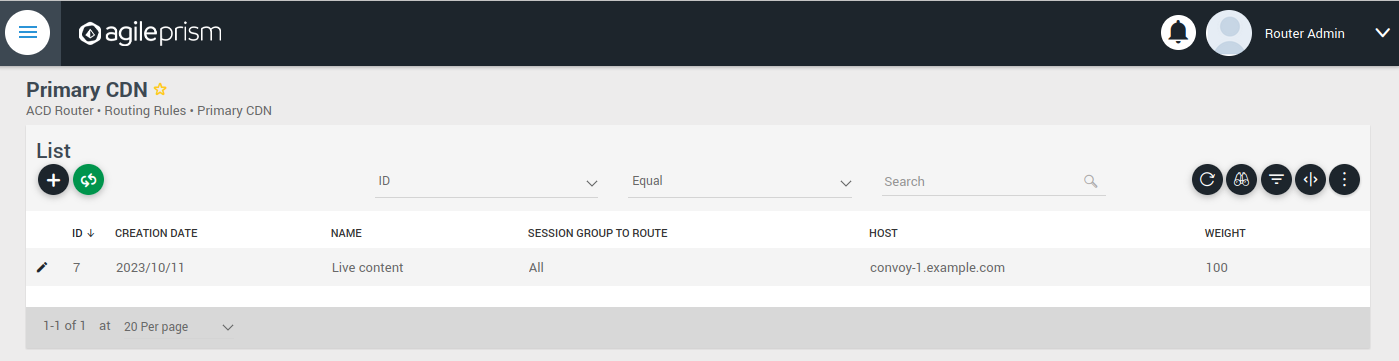
Add all hosts in your primary CDN, together with a weight. A row in this table will be selected by random weighted load balancing. If each weight is the same, each row will be selected with the same probability. Another example would be three rows with weights 100, 100 and 200 which would randomly balance 50% of the load on the last row and the remaining load on the first two rows, i.e. 25% on each of the first and second row. If a Primary CDN host is unavailable, that host will not take part in the random selection.
If all hosts are unavailable, as a final resort the routing evaluation will go to the final Backup CDN step:
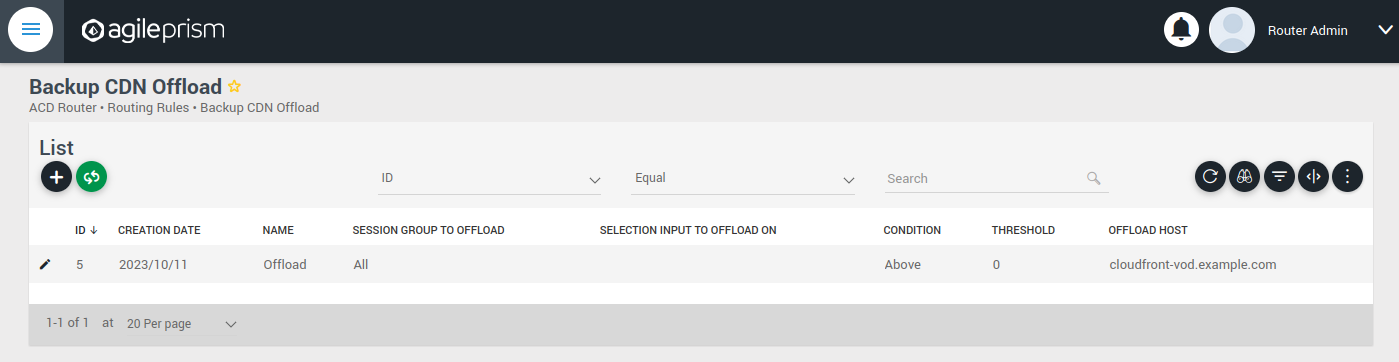
Here you can define what to do when all else fail. If not all requests are covered, for example with an “All” session group, then the request will fail with 403 Forbidden.
Now you have defined the basic elements and it is time to define the routing workflow. Select “Routing Workflow” from the menu, as pictured below. Here you can combine the elements previously created to achieve the desired routing behavior.
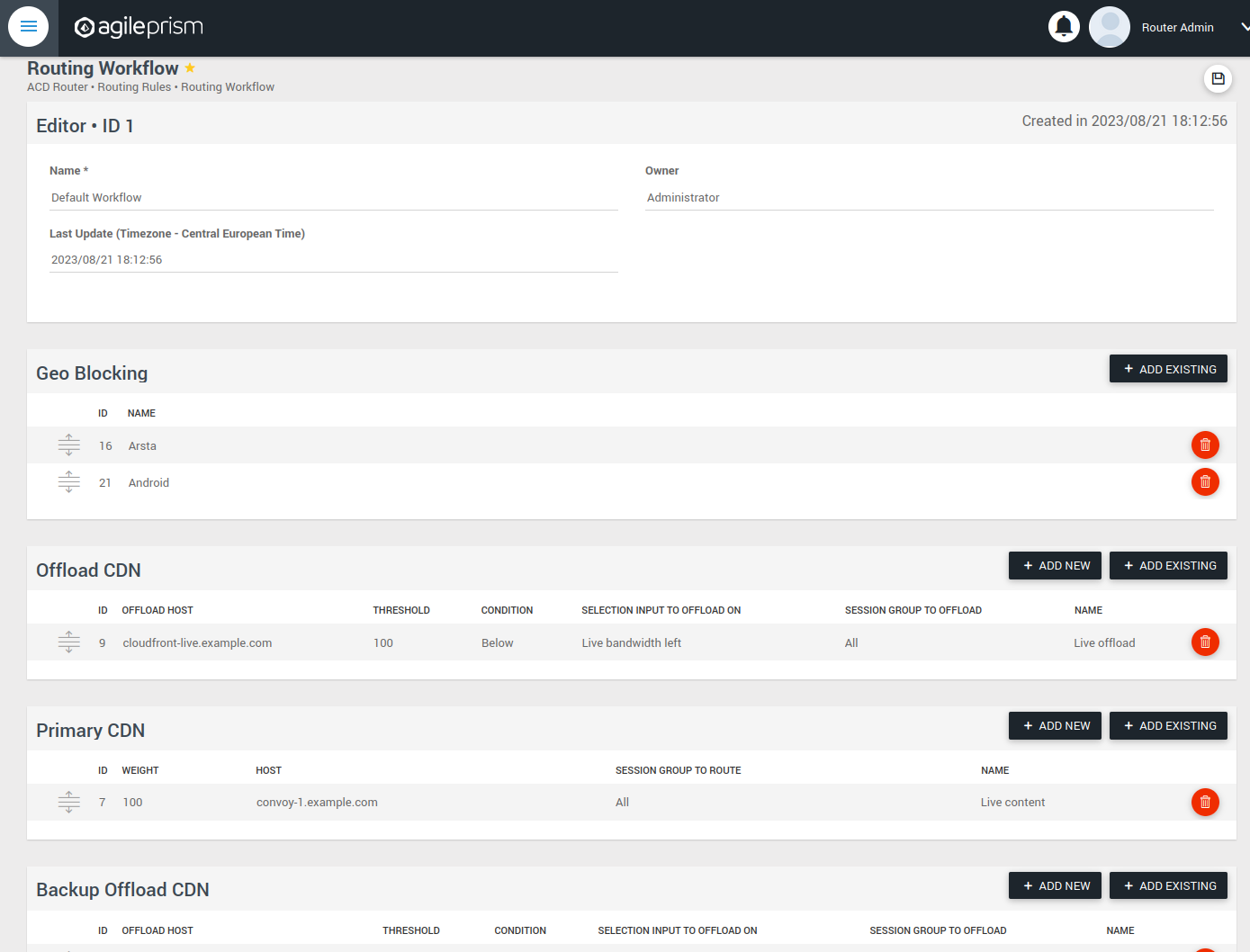
When everything seems correct, open the “Publish Routing” view from the menu:
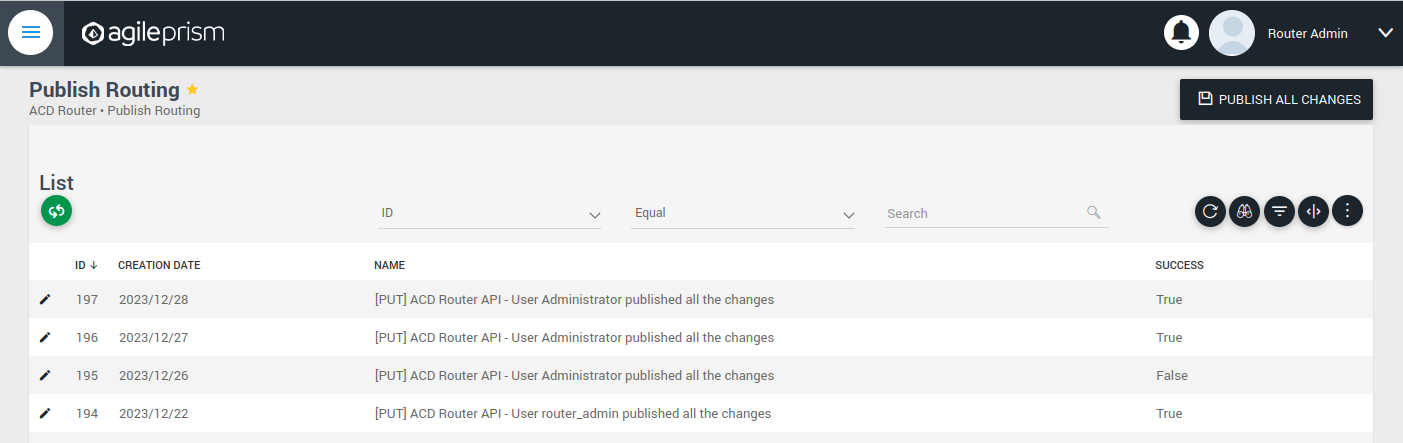
Hit “Publish All Changes” and verify that you get a successful result.
1.1.5.3 - Confd and Confcli
confcli to set up routing rulesConfiguration of a complex routing tree can be difficult. The command line
interface tool called confcli has been developed to make it simpler. It
combines building blocks, representing simple routing decisions, into complex
routing trees capable of satisfying almost any routing requirements.
These blocks are translated into an ESB3024 Router configuration which is automatically sent to the router, overwriting existing routing rules, CDN list and host list.
Installation and Usage
The confcli tools are installed alongside ESB3024 Router, on the same host,
and the confcli command line tool itself is made available on the host machine.
Simply type confcli in a shell on the host to see the current routing
configuration:
$ confcli
{
"services": {
"routing": {
"settings": {
"trustedProxies": [],
"contentPopularity": {
"algorithm": "score_based",
"sessionGroupNames": []
},
"extendedContentIdentifier": {
"enabled": false,
"includedQueryParams": []
},
"instream": {
"dashManifestRewrite": {
"enabled": false,
"sessionGroupNames": []
},
"hlsManifestRewrite": {
"enabled": false,
"sessionGroupNames": []
},
"reversedFilenameComparison": false
},
"usageLog": {
"enabled": false,
"logInterval": 3600000
}
},
"tuning": {
"content": {
"cacheSizeFullManifests": 1000,
"cacheSizeLightManifests": 10000,
"lightCacheTimeMilliseconds": 86400000,
"liveCacheTimeMilliseconds": 100,
"vodCacheTimeMilliseconds": 10000
},
"general": {
"accessLog": false,
"coutFlushRateMilliseconds": 1000,
"cpuLoadWindowSize": 10,
"eagerCdnSwitching": false,
"httpPipeliningEnable": false,
"logLevel": 3,
"maxConnectionsPerHost": 5,
"overloadThreshold": 32,
"readyThreshold": 8,
"redirectingCdnManifestDownloadRetries": 2,
"repeatedSessionStartThresholdSeconds": 30,
"selectionInputMetricsTimeoutSeconds": 30
},
"session": {
"idleDeactivateTimeoutMilliseconds": 20000,
"idleDeleteTimeoutMilliseconds": 1800000
},
"target": {
"responseTimeoutSeconds": 5,
"retryConnectTimeoutSeconds": 2,
"retryResponseTimeoutSeconds": 2,
"connectTimeoutSeconds": 5,
"maxIdleTimeSeconds": 30,
"requestAttempts": 3
}
},
"sessionGroups": [],
"classifiers": [],
"hostGroups": [],
"rules": [],
"entrypoint": "",
"applyConfig": true
}
}
}
The CLI tool can be used to modify, add and delete values by providing it with
the “path” to the object to change. The path is constructed by joining the field
names leading up to the value with a period between each name, e.g. the path to
the entrypoint is services.routing.entrypoint since entrypoint is nested
under the routing object, which in turn is under the services root object.
Lists use an index number in place of a field name, where 0 indicates the very
first element in the list, 1 the second element and so on.
If the list contains objects which have a field with the name name, the
index number can be replaced by the unique name of the object of interest.
Tab completion is supported by confcli. Pressing tab once will complete as far as possible, and pressing tab twice will list all available alternatives at the path constructed so far.
Display the values at a specific path:
$ confcli services.routing.hostGroups
{
"hostGroups": [
{
"name": "internal",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "rr1",
"hostname": "rr1.example.com",
"ipv6_address": ""
}
]
},
{
"name": "external",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "offload-streamer1",
"hostname": "streamer1.example.com",
"ipv6_address": ""
},
{
"name": "offload-streamer2",
"hostname": "streamer2.example.com",
"ipv6_address": ""
}
]
}
]
}
Display the values in a specific list index:
$ confcli services.routing.hostGroups.1
{
"1": {
"name": "external",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "offload-streamer1",
"hostname": "streamer1.example.com",
"ipv6_address": ""
},
{
"name": "offload-streamer2",
"hostname": "streamer2.example.com",
"ipv6_address": ""
}
]
}
}
Display the values in a specific list index using the object’s name:
$ confcli services.routing.hostGroups.1.hosts.offload-streamer2
{
"offload-streamer2": {
"name": "offload-streamer2",
"hostname": "streamer2.example.com",
"ipv6_address": ""
}
}
Modify a single value:
confcli services.routing.hostGroups.1.hosts.offload-streamer2.hostname new-streamer.example.com
services.routing.hostGroups.1.hosts.offload-streamer2.hostname = 'new-streamer.example.com'
Delete an entry:
$ confcli services.routing.sessionGroups.Apple.classifiers.
{
"classifiers": [
"Apple",
""
]
}
$ confcli services.routing.sessionGroups.Apple.classifiers.1 -d
http://localhost:5000/config/__active/services/routing/sessionGroups/Apple/classifiers/1 reset to default/deleted
$ confcli services.routing.sessionGroups.Apple.classifiers.
{
"classifiers": [
"Apple"
]
}
Adding new values in objects and lists is done using a wizard by invoking
confcli with a path and the -w argument. This will be shown extensively in
the examples further down in this document rather than here.
If you have a JSON file with a previously generated confcli configuration
output it can be applied to a system by typing confcli -i <file path>.
CDNs and Hosts
Configuration using confcli has no real concept of CDNs, instead it has groups of hosts that share some common settings such as HTTP(S) port and whether they return a redirection URL, serve content directly or perform a DNS lookup. Of these three variants, the two former share the same parameters, while the DNS variant is slightly different.
Note that by default, the Director expects redirecting CDNs to redirect with
response code 302. If the CDN returns a redirection URL with another HTTP
response code, the field allowAnyRedirectType must be set to true in the
hostGroup configuration. Then any 3xx response code will result in a 302
response code being sent to the client.
If any of the request headers need to be forwarded to the CDN, they can be
listed in the headersToForward field. This is useful if the CDN needs to
know about the original Host header or any custom headers added by the
client or an upstream proxy.
Each host belongs to a host group and may itself be an entire CDN using a single public hostname or a single streamer server, all depending on the needs of the user.
Host Health
When creating a host in the confd configuration, you have the option to define a list of health check functions. Each health check function must return true for a host to be selected. This means that the host will only be considered available if all the defined health check functions evaluate to true. If any of the health check functions return false, the host will be considered unavailable and will not be selected for routing. All health check functions are detailed in the section Built-in Lua functions.
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: redirecting
Adding a 'redirecting' element
hostGroup : {
name (default: ): edgeware
type (default: redirecting): ⏎
httpPort (default: 80): ⏎
httpsPort (default: 443): ⏎
headersToForward <A list of HTTP headers to forward to the CDN. (default: [])>: [
headersToForward (default: ): ⏎
Add another 'headersToForward' element to array 'headersToForward'? [y/N]: ⏎
]
allowAnyRedirectType (default: False): ⏎
hosts : [
host : {
name (default: ): rr1
hostname (default: ): convoy-rr1.example.com
ipv6_address (default: ): ⏎
healthChecks : [
healthCheck (default: always()): health_check()
Add another 'healthCheck' element to array 'healthChecks'? [y/N]: n
]
}
Add another 'host' element to array 'hosts'? [y/N]: y
host : {
name (default: ): rr2
hostname (default: ): convoy-rr2.example.com
ipv6_address (default: ): ⏎
healthChecks : [
healthCheck (default: always()): ⏎
Add another 'healthCheck' element to array 'healthChecks'? [y/N]: n
]
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "edgeware",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"headersToForward": [],
"allowAnyRedirectType": false,
"hosts": [
{
"name": "rr1",
"hostname": "convoy-rr1.example.com",
"ipv6_address": "",
"healthChecks": [
"health_check()"
]
},
{
"name": "rr2",
"hostname": "convoy-rr2.example.com",
"ipv6_address": "",
"healthChecks": [
"always()"
]
}
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: dns
Adding a 'dns' element
hostGroup : {
name (default: ): external-dns
type (default: dns): ⏎
hosts : [
host : {
name (default: ): dns-host
hostname (default: ): dns.example.com
ipv6_address (default: ): ⏎
healthChecks : [
healthCheck (default: always()): ⏎
Add another 'healthCheck' element to array 'healthChecks'? [y/N]: n
]
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "external-dns",
"type": "dns",
"hosts": [
{
"name": "dns-host",
"hostname": "dns.example.com",
"ipv6_address": "",
"healthChecks": [
"always()"
]
}
]
}
]
}
Merge and apply the config? [y/n]: y
Rule Blocks
The routing configuration using confcli is done using a combination of logical
building blocks, or rules. Each block evaluates the incoming request in some way
and sends it on to one or more sub-blocks. If the block is of the host type
described above, the client is sent to that host and the evaluation is done.
Existing Blocks
Currently supported blocks are:
allow: Incoming requests, for which a given rule function matches, are immediately sent to the providedonMatchtarget.consistentHashing: Splits incoming requests randomly between preferred hosts, determined by the proprietary consistent hashing algorithm. The amount of hosts to split between is controlled by thespreadFactor.contentPopularity: Splits incoming requests into two sub-blocks depending on how popular the requested content is.deny: Incoming requests, for which a given rule function matches, are immediately denied, and all non-matching requests are sent to theonMisstarget.firstMatch: Incoming requests are matched by an ordered series of rules, where the request will be handled by the first rule for which the condition evaluates to true.random: Splits incoming requests randomly and equally between a list of target sub-blocks. Useful for simple load balancing.split: Splits incoming requests between two sub-blocks depending on how the request is evaluated by a provided function. Can be used for sending clients to different hosts depending on e.g. geographical location or client hardware type.weighted: Randomly splits incoming requests between a list of target sub-blocks, weighted according to each target’s associated weight rule. A higher weight means a higher portion of requests will be routed to a sub-block. Rules can be used to decide whether or not to pick a target.rawGroup: Contains a raw ESB3024 Router configuration routing tree node, to be inserted as is in the generated configuration. This is only meant to be used in the rare cases when it’s impossible to construct the required routing behavior in any other way.rawHost: A host reference for use as endpoints in rawGroup trees.
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: allow
Adding a 'allow' element
rule : {
name (default: ): allow
type (default: allow): ⏎
condition (default: ): customFunction()
onMatch (default: ): rr1
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "content",
"type": "contentPopularity",
"condition": "customFunction()",
"onMatch": "rr1"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: consistentHashing
Adding a 'consistentHashing' element
rule : {
name (default: ): consistentHashingRule
type (default: consistentHashing):
spreadFactor (default: 1): 2
hashAlgorithm (default: MD5):
targets : [
target : {
target (default: ): rr1
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): rr2
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): rr3
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: n
]
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "consistentHashingRule",
"type": "consistentHashing",
"spreadFactor": 2,
"hashAlgorithm": "MD5",
"targets": [
{
"target": "rr1",
"enabled": true
},
{
"target": "rr2",
"enabled": true
},
{
"target": "rr3",
"enabled": true
}
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: contentPopularity
Adding a 'contentPopularity' element
rule : {
name (default: ): content
type (default: contentPopularity): ⏎
contentPopularityCutoff (default: 10): 20
onPopular (default: ): rr1
onUnpopular (default: ): rr2
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "content",
"type": "contentPopularity",
"contentPopularityCutoff": 20.0,
"onPopular": "rr1",
"onUnpopular": "rr2"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: deny
Adding a 'deny' element
rule : {
name (default: ): deny
type (default: deny): ⏎
condition (default: ): customFunction()
onMiss (default: ): rr1
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "content",
"type": "contentPopularity",
"condition": "customFunction()",
"onMiss": "rr1"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: firstMatch
Adding a 'firstMatch' element
rule : {
name (default: ): firstMatch
type (default: firstMatch): ⏎
targets : [
target : {
onMatch (default: ): rr1
rule (default: ): customFunction()
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): rr2
rule (default: ): otherCustomFunction()
}
Add another 'target' element to array 'targets'? [y/N]: n
]
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "firstMatch",
"type": "firstMatch",
"targets": [
{
"onMatch": "rr1",
"condition": "customFunction()"
},
{
"onMatch": "rr2",
"condition": "otherCustomFunction()"
}
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: random
Adding a 'random' element
rule : {
name (default: ): random
type (default: random): ⏎
targets : [
target (default: ): rr1
Add another 'target' element to array 'targets'? [y/N]: y
target (default: ): rr2
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "random",
"type": "random",
"targets": [
"rr1",
"rr2"
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): split
type (default: split): ⏎
condition (default: ): custom_function()
onMatch (default: ): rr2
onMiss (default: ): rr1
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "split",
"type": "split",
"condition": "custom_function()",
"onMatch": "rr2",
"onMiss": "rr1"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.rules. -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: weighted
Adding a 'weighted' element
rule : {
name (default: ): weight
type (default: weighted): ⏎
targets : [
target : {
target (default: ): rr1
weight (default: 100): ⏎
condition (default: always()): always()
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): rr2
weight (default: 100): si('rr2-input-weight')
condition (default: always()): gt('rr2-bandwidth', 1000000)
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): rr2
weight (default: 100): custom_func()
condition (default: always()): always()
}
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "weight",
"type": "weighted",
"targets": [
{
"target": "rr1",
"weight": "100",
"condition": "always()"
},
{
"target": "rr2",
"weight": "si('rr2-input-weight')",
"condition": "gt('rr2-bandwith', 1000000)"
},
{
"target": "rr2",
"weight": "custom_func()",
"condition": "always()"
}
]
}
]
}
Merge and apply the config? [y/n]: y
>> First add a raw host block that refers to a regular host
$ confcli services.routing.rules. -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: rawHost
Adding a 'rawHost' element
rule : {
name (default: ): raw-host
type (default: rawHost): ⏎
hostId (default: ): rr1
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "raw-host",
"type": "rawHost",
"hostId": "rr1"
}
]
}
Merge and apply the config? [y/n]: y
>> And then add a rule using the host node
$ confcli services.routing.rules. -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: rawGroup
Adding a 'rawGroup' element
rule : {
name (default: ): raw-node
type (default: rawGroup): ⏎
memberOrder (default: sequential): ⏎
members : [
member : {
target (default: ): raw-host
weightFunction (default: ): return 1
}
Add another 'member' element to array 'members'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "raw-node",
"type": "rawGroup",
"memberOrder": "sequential",
"members": [
{
"target": "raw-host",
"weightFunction": "return 1"
}
]
}
]
}
Merge and apply the config? [y/n]: y
Rule Language
Some blocks, such as the split and firstMatch types, have a rule field that
contains a small function in a very simple programming language. This field is
used to filter any incoming client requests in order to determine how to rule
block should react.
In the case of a split block, the rule is evaluated and if it is true the
client is sent to the onMatch part of the block, otherwise it is sent to the
onMiss part for further evaluation.
In the case of a firstMatch block, the rule for each target will be evaluated
top to bottom in order until either a rule evaluates to true or the list is
exhausted. If a rule evaluates to true, the client will be sent to the onMatch
part of the block, otherwise the next target in the list will be tried. If all
targets have been exhausted, then the entire rule evaluation will fail, and the
routing tree will be restarted with the firstMatch block effectively removed.
Example of Boolean Functions
Let’s say we have an ESB3024 Router set up with a session group that matches Apple
devices (named “Apple”). To route all Apple devices to a specific streamer one
would simply create a split block with the following rule:
in_session_group('Apple')
In order to make more complex rules it’s possible to combine several checks like
this in the same rule. Let’s extend the hypothetical ESB3024 Router above with a
configured subnet with all IP addresses in Europe (named “Europe”). To make a
rule that accepts any clients using an Apple device and living outside of
Europe, but only as long as the reported load on the streamer (as indicated by
the selection input variable
“europe_load_mbps”) is less than 1000 megabits per second one could make an
offload block with the following rule (without linebreaks):
in_session_group('Apple')
and not in_subnet('Europe')
and lt('europe_load_mbps', 1000)
In this example in_session_group('Apple') will be true if the client belongs
to the session group named ‘Apple’. The function call in_subnet('Europe') is
true if the client’s IP belongs to the subnet named ‘Europe’, but the word not
in front of it reverses the value so the entire section ends up being false if
the client is in Europe. Finally lt('europe_load_mbps', 1000) is true if
there is a selection input variable named “europe_load_mbps” and its value is
less than 1000.
Since the three parts are conjoined with the and keyword they must all
be true for the entire rule to match. If the keyword or had been used
instead it would have been enough for any of the parts to be true for the
rule to match.
Example of Numeric Functions
A hypothetical CDN has two streamers with different capacity; Host_1 has
roughly twice the capacity of Host_2. A simple random load balancing would put
undue stress on the second host since it will receive as much traffic as the
more capable Host_1.
This can be solved by using a weighted random distribution rule block with
suitable rules for the two hosts:
{
"targets": [
{
"target": "Host_1",
"condition": "always()",
"weight": "100"
}
{
"target": "Host_2",
"condition": "always()",
"weight": "50"
},
]
}
resulting in Host_1 receiving twice as many requests as Host_2 as its
weight function is double that of Host_2.
If the CDN is capable of reporting the free capacity of the hosts, for example by writing to a selection input variable for each host, it’s easy to write a more intelligent load balancing rule by making the weights correspond to the amount of capacity left on each host:
{
"targets": [
{
"target": "Host_1",
"condition": "always()",
"weight": "si('free_capacity_host_1')"
}
{
"target": "Host_2",
"condition": "always()",
"weight": "si('free_capacity_host_2')"
},
]
}
It is also possible to write custom Lua functions that return suitable weights, perhaps taking the host as an argument:
{
"targets": [
{
"target": "Host_1",
"condition": "always()",
"weight": "intelligent_weight_function('Host_1')"
}
{
"target": "Host_2",
"condition": "always()",
"weight": "intelligent_weight_function('Host_1')"
},
]
}
These different weight rules can of course be combined in the same rule block, with one target having a hard coded number, another using a dynamically updated selection input variable and yet another having a custom-built function.
Due to limitations in the random number generator used to distribute requests, it’s better to use somewhat large values, around 100–1000 or so, than to use small values near 0.
Built-In Functions
The following built-in functions are available when writing rules:
in_session_group(str name): True if session belongs to session group<name>in_all_session_groups(str sg_name, ...): True if session belongs to all specified session groupsin_any_session_group(str sg_name, ...): True if session belongs to any specified session groupin_subnet(str subnet_name): True if client IP belongs to the named subnetgt(str si_var, number value): True if selection_inputs[si_var] > valuegt(str si_var1, str si_var2): True if selection_inputs[si_var1] > selection_inputs[si_var2]ge(str si_var, number value): True if selection_inputs[si_var] >= valuege(str si_var1, str si_var2): True if selection_inputs[si_var1] >= selection_inputs[si_var2]lt(str si_var, number value): True if selection_inputs[si_var] < valuelt(str si_var1, str si_var2): True if selection_inputs[si_var1] < selection_inputs[si_var2]le(str si_var, number value): True if selection_inputs[si_var] <= valuele(str si_var1, str si_var2): True if selection_inputs[si_var1] <= selection_inputs[si_var2]eq(str si_var, number value): True if selection_inputs[si_var] == valueeq(str si_var1, str si_var2): True if selection_inputs[si_var1] == selection_inputs[si_var2]neq(str si_var, number value): True if selection_inputs[si_var] != valueneq(str si_var1, str si_var2): True if selection_inputs[si_var1] != selection_inputs[si_var2]si(str si_var): Returns the value of selection_inputs[si_var] if it is defined and non-negative, otherwise it returns 0.always(): Returns true, useful when creating weighted rule blocks.never(): Returns false, opposite ofalways().
These functions, as well as custom functions written in Lua and uploaded to the ESB3024 Router, can be combined to make suitably precise rules.
Combining Multiple Boolean Functions
In order to make the rule language easy to work with, it is fairly restricted
and simple. One restriction is that it’s only possible to chain multiple
function results together using either and or or, but not a
combination of both conjunctions.
Statements joined with and or or keywords are evaluated one by one,
starting with the left-most statement and moving right. As soon as the end
result of the entire expression is certain, the evaluation ends. This means that
evaluation ends with the first false statement for and expressions since a
single false component means the entire expression must also be false. It
also means that evaluation ends with the first true statement for or
expressions since only one component must be true for the entire statement to
be true as well. This is known as short-circuit or lazy evaluation.
Custom Functions
It is possible to write extremely complex Lua functions that take many parameters or calculations into consideration when evaluating an incoming client request. By writing such functions and making sure that they return only non-negative integer values and uploading them to the router they can be used from the rule language. Simply call them like any of the built-in functions listed above, using strings and numbers as arguments if necessary, and their result will be used to determine the routing path to use.
Formal Syntax
The full syntax of the language can be described in just a few lines of BNF grammar:
<rule> := <weight_rule> | <match_rule> | <value_rule>
<weight_rule> := "if" <compound_predicate> "then" <weight> "else" <weight>
<match_rule> := <compound_predicate>
<value_rule> := <weight>
<compound_predicate> := <logical_predicate> |
<logical_predicate> ["and" <logical_predicate> ...] |
<logical_predicate> ["or" <logical_predicate> ...] |
<logical_predicate> := ["not"] <predicate>
<predicate> := <function_name> "(" ")" |
<function_name> "(" <argument> ["," <argument> ...] ")"
<function_name> := <letter> [<function_name_tail> ...]
<function_name_tail> := empty | <letter> | <digit> | "_"
<argument> := <string> | <number>
<weight> := integer | <predicate>
<number> := float | integer
<string> := "'" [<letter> | <digit> | <symbol> ...] "'"
Building a Routing Configuration
This example sets up an entire routing configuration for a system with a ESB3008 Request Router, two streamers and the Apple devices outside of Europe example used earlier in this document. Any clients not matching the criteria will be sent to an offload CDN with two streamers in a simple uniformly randomized load balancing setup.
Set up Session Group
First make a classifier and a session group that uses it:
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: userAgent
Adding a 'userAgent' element
classifier : {
name (default: ): Apple
type (default: userAgent): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *apple*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "Apple",
"type": "userAgent",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*apple*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): Apple
classifiers : [
classifier (default: ): Apple
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "Apple",
"classifiers": [
"Apple"
]
}
]
}
Merge and apply the config? [y/n]: y
Set up Hosts
Create two host groups and add a Request Router to the first and two streamers to the second, which will be used for offload:
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: redirecting
Adding a 'redirecting' element
hostGroup : {
name (default: ): internal
type (default: redirecting): ⏎
httpPort (default: 80): ⏎
httpsPort (default: 443): ⏎
headersToForward <A list of HTTP headers to forward to the CDN. (default: [])>: [
headersToForward (default: ): ⏎
Add another 'headersToForward' element to array 'headersToForward'? [y/N]: ⏎
]
allowAnyRedirectType (default: False): ⏎
hosts : [
host : {
name (default: ): rr1
hostname (default: ): rr1.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: y
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: host
Adding a 'host' element
hostGroup : {
name (default: ): external
type (default: host): ⏎
httpPort (default: 80): ⏎
httpsPort (default: 443): ⏎
hosts : [
host : {
name (default: ): offload-streamer1
hostname (default: ): streamer1.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: y
host : {
name (default: ): offload-streamer2
hostname (default: ): streamer2.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "internal",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"headersToForward": [],
"allowAnyRedirectType": false,
"hosts": [
{
"name": "rr1",
"hostname": "rr1.example.com",
"ipv6_address": ""
}
]
},
{
"name": "external",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "offload-streamer1",
"hostname": "streamer1.example.com",
"ipv6_address": ""
},
{
"name": "offload-streamer2",
"hostname": "streamer2.example.com",
"ipv6_address": ""
}
]
}
]
}
Merge and apply the config? [y/n]: y
Create Load Balancing and Offload Block
Add both offload streamers as targets in a randomgroup block:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: random
Adding a 'random' element
rule : {
name (default: ): balancer
type (default: random): ⏎
targets : [
target (default: ): offload-streamer1
Add another 'target' element to array 'targets'? [y/N]: y
target (default: ): offload-streamer2
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "balancer",
"type": "random",
"targets": [
"offload-streamer1",
"offload-streamer2"
]
}
]
}
Merge and apply the config? [y/n]: y
Then create a split block with the request router and the load balanced CDN as targets:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): offload
type (default: split): ⏎
rule (default: ): in_session_group('Apple') and not in_subnet('Europe') and lt('europe_load_mbps', 1000)
onMatch (default: ): rr1
onMiss (default: ): balancer
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "offload",
"type": "split",
"condition": "in_session_group('Apple') and not in_subnet('Europe') and lt('europe_load_mbps', 1000)",
"onMatch": "rr1",
"onMiss": "balancer"
}
]
}
Merge and apply the config? [y/n]: y
The last step required is to set the entrypoint of the routing tree so the router knows where to start evaluating:
$ confcli services.routing.entrypoint offload
services.routing.entrypoint = 'offload'
Evaluate
Now that all the rules have been set up properly and the router has been reconfigured. The translated configuration can be read from the router’s configuration API:
$ curl -k https://router-host:5001/v2/configuration 2> /dev/null | jq .routing
{
"id": "offload",
"member_order": "sequential",
"members": [
{
"host_id": "rr1",
"id": "offload.rr1",
"weight_function": "return ((in_session_group('Apple') ~= 0) and
(in_subnet('Europe') == 0) and
(lt('europe_load_mbps', 1000) ~= 0) and 1) or 0 "
},
{
"id": "offload.balancer",
"member_order": "weighted",
"members": [
{
"host_id": "offload-streamer1",
"id": "offload.balancer.offload-streamer1",
"weight_function": "return 100"
},
{
"host_id": "offload-streamer2",
"id": "offload.balancer.offload-streamer2",
"weight_function": "return 100"
}
],
"weight_function": "return 1"
}
],
"weight_function": "return 100"
}
Note that the configuration language code has been translated into its Lua equivalent.
1.1.5.4 - Session Groups and Classification
ESB3024 Router provides a flexible classification engine, allowing the assignment of clients into session groups that can then be used to base routing decisions on.
Session Classification
In order to perform routing it is necessary to classify incoming sessions according to the relevant parameters. This is done through session groups and their associated classifiers.
There are different ways of classifying a request:
Anonymous IP: Classifies clients using an anonymous IP database. See Geographic Databases for information about the database.ASN IDs: Checks to see if a client’s IP belongs to any of the specified ASN IDs. See Geographic Databases for information about the ASN database.Content URL path: Matches the given pattern against the path part of the URL requested by the client. The match can be either a case-insensitive wildcard match or a regular expression match.Content URL query parameters: Matches the given pattern against the query parameters of the URL requested by the client. The query parameters are passed as a single string. The match can be either a case-insensitive wildcard match or a regular expression match.GeoIP: Based on the geographic location of the client, supporting wildcard matching. See Route on GeoIP/ASN for more details. The possible values to match with are any combinations of:- Continent
- Country
- Region
- Cities
- ASN
Host name: Matches the given pattern against the name of the host that the request was sent to. The match can be either a case-insensitive wildcard match or a regular expression match.IP ranges: Classifies a client based on whether its IP address belongs to any of the listed IP ranges or not.Random: Randomly classifies clients according to a given probability. The classifier is deterministic, meaning that a session will always get the same classification, even if evaluated multiple times.Regular expression matcher: Matches the given pattern against a configurable source. The match is case-insensitive and supports regular expressions. The following sources are available:content_url_path: The path part of the URL requested by the client.content_url_query_params: The query parameters of the URL requested by the client. The query parameters are passed as a single string.hostname: The name of the host that the request was sent to.user_agent: The user agent string in the HTTP request from the client.
Request Header: Classifies clients based on the value of a specified HTTP header in the request from the client.String matcher: Matches the given pattern against a configurable source. The match is case-insensitive and supports wildcards (’*’). The following sources are available:content_url_path: The path part of the URL requested by the client.content_url_query_params: The query parameters of the URL requested by the client. The query parameters are passed as a single string.hostname: The name of the host that the request was sent to.user_agent: The user agent string in the HTTP request from the client.
Subnet: Tests if a client’s IP belongs to a named subnet, see Subnets for more details.User agent: Matches the given pattern against the user agent string in the HTTP request from the client. The match can be either a case-insensitive wildcard match or a regular expression match.
A session group may have more than one classifier. If it does, all the classifiers must match the incoming client request for it to belong to the session group. It is also possible for a request to belong to multiple session groups, or to none.
To send certain clients to a specific host you first need to create a suitable
classifier using confcli in wizard mode. The wizard will guide you through the
process of creating a new entry, asking you what value to input for each field
and helping you by telling you what inputs are allowed for restricted fields
such as the string comparison source mentioned above:
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: anonymousIp
Adding a 'anonymousIp' element
classifier : {
name (default: ): anon_ip_matcher
type (default: anonymousIp):
inverted (default: False):
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "anon_ip_matcher",
"type": "anonymousIp",
"inverted": false
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: asnIds
Adding a 'asnIds' element
classifier : {
name (default: ): asn_matcher
type (default: asnIds): ⏎
inverted (default: False): ⏎
asnIds <The list of ASN IDs to accept. (default: [])>: [
asnId: 1
Add another 'asnId' element to array 'asnIds'? [y/N]: y
asnId: 2
Add another 'asnId' element to array 'asnIds'? [y/N]: y
asnId: 3
Add another 'asnId' element to array 'asnIds'? [y/N]: ⏎
]
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "asn_matcher",
"type": "asnIds",
"inverted": false,
"asnIds": [
1,
2,
3
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlPath
Adding a 'contentUrlPath' element
classifier : {
name (default: ): vod_matcher
type (default: contentUrlPath): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *vod*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "vod_matcher",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*vod*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlQueryParameters
Adding a 'contentUrlQueryParameters' element
classifier : {
name (default: ): bitrate_matcher
type (default: contentUrlQueryParameters): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): regex
pattern (default: ): .*bitrate=100000.*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "bitrate_matcher",
"type": "contentUrlQueryParameters",
"inverted": false,
"patternType": "regex",
"pattern": ".*bitrate=100000.*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: geoip
Adding a 'geoip' element
classifier : {
name (default: ): sweden_matcher
type (default: geoip): ⏎
inverted (default: False): ⏎
continent (default: ): ⏎
country (default: ): sweden
cities : [
city (default: ): ⏎
Add another 'city' element to array 'cities'? [y/N]: ⏎
]
asn (default: ): ⏎
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "sweden_matcher",
"type": "geoip",
"inverted": false,
"continent": "",
"country": "sweden",
"cities": [
""
],
"asn": ""
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: hostName
Adding a 'hostName' element
classifier : {
name (default: ): host_name_classifier
type (default: hostName): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *live.example*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "host_name_classifier",
"type": "hostName",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*live.example*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: ipranges
Adding a 'ipranges' element
classifier : {
name (default: ): company_matcher
type (default: ipranges): ⏎
inverted (default: False): ⏎
ipranges : [
iprange (default: ): 90.128.0.0/12
Add another 'iprange' element to array 'ipranges'? [y/N]: ⏎
]
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "company_matcher",
"type": "ipranges",
"inverted": false,
"ipranges": [
"90.128.0.0/12"
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: random
Adding a 'random' element
classifier <A classifier randomly applying to clients based on the provided probability. (default: OrderedDict())>: {
name (default: ): random_matcher
type (default: random):
probability (default: 0.5): 0.7
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "random_matcher",
"type": "random",
"probability": 0.7
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: regexMatcher
Adding a 'regexMatcher' element
classifier : {
name (default: ): content_matcher
type (default: regexMatcher): ⏎
inverted (default: False): ⏎
source (default: content_url_path): ⏎
pattern (default: ): .*/(live|news_channel)/.*m3u8
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "content_matcher",
"type": "regexMatcher",
"inverted": false,
"source": "content_url_path",
"pattern": ".*/(live|news_channel)/.*m3u8"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: requestHeader
Adding a 'requestHeader' element
classifier <A classifier that matches on headers in the HTTP request. (default: OrderedDict())>: {
name (default: ): curl
type (default: requestHeader): ⏎
inverted (default: False): ⏎
header (default: ): User-Agent
patternType (default: stringMatch): ⏎
patternSource (default: inline): ⏎
pattern (default: ): curl*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "curl",
"type": "requestHeader",
"inverted": false,
"header": "User-Agent",
"patternType": "stringMatch",
"patternSource": "inline",
"pattern": "curl*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: stringMatcher
Adding a 'stringMatcher' element
classifier : {
name (default: ): apple_matcher
type (default: stringMatcher): ⏎
inverted (default: False): ⏎
source (default: content_url_path): user_agent
pattern (default: ): *apple*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "apple_matcher",
"type": "stringMatcher",
"inverted": false,
"source": "user_agent",
"pattern": "*apple*"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: subnet
Adding a 'subnet' element
classifier : {
name (default: ): company_matcher
type (default: subnet): ⏎
inverted (default: False): ⏎
patternSource (default: inline): ⏎
pattern (default: ): company
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "company_matcher",
"type": "subnet",
"inverted": false,
"patternSource": "inline",
"pattern": "company"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: userAgent
Adding a 'userAgent' element
classifier : {
name (default: ): iphone_matcher
type (default: userAgent): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): regex
pattern (default: ): i(P|p)hone
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "iphone_matcher",
"type": "userAgent",
"inverted": false,
"patternType": "regex",
"pattern": "i(P|p)hone"
}
]
}
Merge and apply the config? [y/n]: y
These classifiers can now be used to construct session groups and properly classify clients. Using the examples above, let’s create a session group classifying clients from Sweden using an Apple device:
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): inSwedenUsingAppleDevice
classifiers : [
classifier (default: ): sweden_matcher
Add another 'classifier' element to array 'classifiers'? [y/N]: y
classifier (default: ): apple_matcher
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "inSwedenUsingAppleDevice",
"classifiers": [
"sweden_matcher",
"apple_matcher"
]
}
]
}
Merge and apply the config? [y/n]: y
Clients classified by the sweden_matcher and apple_matcher classifiers
will now be put in the session group inSwedenUsingAppleDevice. Using session
groups in routing will be demonstrated later in this document.
Pattern Source
The requestHeader and subnet classifiers have a patternSource field,
which can be either inline or selectionInput. When set to inline, the
pattern is taken directly from the pattern field.
If it is selectionInput, the pattern field is used as a path in the
selection input that points
to the pattern to use for classification. The selection input path may contain
a wildcard ("*"), which matches all elements inside an object or array.
For example, if patternSource contains /blocked_user_agents/*/agent, the
classifier will take its pattern from all agent fields in objects inside
/blocked_user_agents.
If the selection input contains the following data:
{
"blocked_user_agents": {
{ "agent1": { "agent": "Firefox" }},
{ "agent2": { "agent": "Chrome" }}
}
}
then the classifier will match either Firefox or Chrome.
Advanced Classification
The above example will simply apply all classifiers in the list, and as long as they all evaluate to true for a session, that session will be tagged with the session group. For situations where this isn’t enough, classifiers can instead be combined using simple logic statements to form complex rules.
A first simple example can be a session group that accepts any viewers in either
ASN 1, 2 or 3 (corresponding to the classifier asn_matcher or living in Sweden.
This can be done by creating a session group, and adding the following logic
statement:
'sweden_matcher' OR 'asn_matcher'
A slightly more advanced case is where a session group should only contain sessions neither in any of the three ASNs nor in Sweden. This is done by negating the previous example:
NOT ('sweden_matcher' OR 'asn_matcher')
A single classifier can also be negated, rather than the whole statement, for example to accept any Swedish viewers except those in the three ASNs:
'sweden_matcher' AND NOT 'asn_matcher'
Arbitrarily complex statements can be created using classifier names, parentheses,
and the keywords AND, OR and NOT.
For example a session group accepting any Swedish viewers except those in the Stockholm region unless they are also Apple users:
'sweden_matcher' AND (NOT 'stockholm_matcher' OR 'apple_matcher')
Note that the classifier names must be enclosed in single quotes when using this syntax.
Applying this kind of complex classifier using confcli is no more difficult than adding a single classifier at a time:
$ confcli services.routing.sessionGroups. -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): complex_group
classifiers : [
classifier (default: ): 'sweden_matcher' AND (NOT 'stockholm_matcher' OR 'apple_matcher')
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "complex_group",
"classifiers": [
"'sweden_matcher' AND (NOT 'stockholm_matcher' OR 'apple_matcher')"
]
}
]
}
Merge and apply the config? [y/n]: y
1.1.5.5 - Accounts
If accounts are configured, the router will tag sessions as belonging to an
account. Note that if accounts are not configured or a session does not belong to
an account, a session will be tagged with the default account.
Metrics will be tracked separately for each account when applicable.
Configuration
Accounts are configured using session groups, see Classification
for more information. Using confcli, an account is configured by defining an
account name and a list of session groups for which a session must be classified
into to belong to the account. An account called account_1 can be configured by
running the command
confcli services.routing.accounts -w
Running wizard for resource 'accounts'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
accounts : [
account : {
name (default: ): account_1
sessionGroups <A session will be tagged as belonging to this account if it's classified into all of the listed session groups. (default: [])>: [
sessionGroup (default: ): session_group_1
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: y
sessionGroup (default: ): session_group_2
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: n
]
}
Add another 'account' element to array 'accounts'? [y/N]: n
]
Generated config:
{
"accounts": [
{
"name": "account_1",
"sessionGroups": [
"session_group_1",
"session_group_2"
]
}
]
}
Merge and apply the config? [y/n]: y
A session will belong to the account account_1 if it has been classified into
the two session groups session_group_1 and session_group_2.
Metrics
If using the configuration above, the metrics will be separated per account:
# TYPE num_requests counter
num_requests{account="account_1",selector="initial"} 3
# TYPE num_requests counter
num_requests{account="default",selector="initial"} 3
1.1.5.6 - Data streams
Data streams can be used to produce and consume data to and from external data sources. This is useful for integrating with other systems, such as Kafka, to allow data synchronization between different instances of the Director or to read external selection input data.
Configuration
Currently, only Kafka data streams are supported. The addresses of the Kafka
brokers to connect to are configured in integration.kafka.bootstrapServers:
confcli integration.kafka.bootstrapServers
{
"bootstrapServers": [
"kafka-broker-host:9095"
]
}
These Kafka brokers can then be interacted with by configuring data streams in
the services.routing.dataStreams section of the configuration:
confcli services.routing.dataStreams
{
"dataStreams": {
"incoming": [],
"outgoing": []
}
}
Incoming data streams
incoming is a list of data streams that the Director will consume data from.
An incoming data stream defines the following properties:
name: The name of the data stream. This is used to identify the data stream in the configuration and in the logs.source: The source of the data stream. Currently, the only supported source iskafka, which means that the data will be consumed from the Kafka broker configured inintegration.kafka.bootstrapServers.target: The target of the data consumed from the stream. Currently, the only supported target isselectionInput, which means that the consumed data will be stored as selection input data.kafkaTopics: A list of Kafka topics to consume data from.
The following configuration will make the Director consume data from the Kafka
topic selection_input from the Kafka broker configured in
integration.kafka.bootstrapServers and store it as selection input data.
confcli services.routing.dataStreams.incoming
{
"incoming": [
{
"name": "incomingDataStream",
"source": "kafka",
"kafkaTopics": [
"selection_input"
],
"target": "selectionInput"
}
]
}
Outgoing data streams
outgoing is a list of data streams that the Director will produce data to.
An outgoing data stream defines the following properties:
name: The name of the data stream. This is used to identify the data stream in the configuration, in a Lua context and in the logs.type: The type of the data stream. Currently, the only supported type iskafka, which means that the data will be produced to the Kafka broker configured inintegration.kafka.bootstrapServers.kafkaTopic: The Kafka topic to produce data to.
Example of an outgoing data stream that produces to the Kafka topic selection_input:
confcli services.routing.dataStreams.outgoing
{
"outgoing": [
{
"name": "outgoingDataStream",
"type": "kafka",
"kafkaTopic": "selection_input"
}
]
}
Data can be sent to outgoing data streams from a Lua function, see Data stream related functions for more information.
1.1.5.7 - Selection Input Configurations
Selection Input Limits
The number of stored selection input leaf items can be limited with the
selectionInputItemLimit tuning parameter.
$ confcli services.routing.tuning.general.selectionInputItemLimit
{
"selectionInputItemLimit": 10000
}
Selection Input Persistence
Selection input data used by classifiers can be stored in the AgileTV CDN
Manager. This makes the data persistent and allows it to be shared between
Director instances. Each Director fetches the data on startup from the Manager
when selectionInputFetchBase is configured:
$ confcli integration.manager.selectionInputFetchBase
{
"selectionInputFetchBase": "https://acd-manager.example.com/api/selection-input/"
}
1.1.5.8 - Advanced features
1.1.5.8.1 - Content popularity
ESB3024 Router can make routing decisions based on content popularity. All incoming content requests are tracked to continuously update a content popularity ranking list. The popularity ranking algorithm is designed to let popular content quickly rise to the top while unpopular content decays and sinks towards the bottom.
Routing
A content popularity based routing rule can be created by running
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: contentPopularity
Adding a 'contentPopularity' element
rule : {
name (default: ): content_popularity_rule
type (default: contentPopularity):
contentPopularityCutoff (default: 10): 5
onPopular (default: ): edge-streamer
onUnpopular (default: ): offload
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "content_popularity_rule",
"type": "contentPopularity",
"contentPopularityCutoff": 5.0,
"onPopular": "edge-streamer",
"onUnpopular": "offload"
}
]
}
Merge and apply the config? [y/n]: y
This rule will route requests for the top 5 most popular content items to
edge-streamer and all other requests to offload.
Some configuration settings attributed to content popularity are available:
$ confcli services.routing.settings.contentPopularity
{
"contentPopularity": {
"enabled": true,
"algorithm": "score_based",
"sessionGroupNames": [],
"popularityListMaxSize": 100000,
"scoreBased": {
"popularityDecayFraction": 0.2,
"popularityPredictionFactor": 2.5,
"requestsBetweenPopularityDecay": 1000
},
"timeBased": {
"intervalsPerHour": 10
}
}
}
enabled: Whether or not to track content popularity. Whenenabledis set tofalse, content popularity will not be tracked. Note that routing on content popularity is possible even ifenabledisfalseand content popularity has been tracked previously.algorithm: Choice of content popularity tracking algorithm. There are two possible choices:score_basedortime_based(detailed below).sessionGroupNames: Names of the session groups for which content popularity should be tracked. If left empty, content popularity will be tracked for all sessions. The content popularity is tracked globally, not per session group, but the popularity metrics is only updated for sessions belonging to these groups.popularityListMaxSize: The maximum amount of unique content items to track for popularity.scoreBased: Configuration parameters unique to the score based algorithm.timeBased: Configuration parameters unique to the time based algorithm.
Size of Popularity List
The size of the popularity list is limited to prevent it growing forever. A single entry in the popularity ranking list will at most consume 180 bytes of memory. E.g. setting the maximum size to 1000 would consume at most 180⋅1,000 = 180,000 B = 0.18 MB. If the content popularity list is full, a request to a new item will replace the least popular item.
Setting a very high maximum size will not impact performance, it will only consume more memory.
Score-Based Algorithm
The requestsBetweenPopularityDecay parameter defines the number of requests
between each popularity decay update, an integral component of this feature.
The popularityPredictionFactor and popularityDecayFraction settings tune
the behaviour of the content popularity ranking algorithm, explained further
below.
Decay Update
To allow for popular content to quickly rise in popularity and unpopular content to sink, a dynamic popularity ranking algorithm is used. The goal of the algorithm is to track content popularity in real time, allowing routing decisions based on the requested content’s popularity. The algorithm is applied every decay update.
The algorithm uses current trending content to predict content popularity. The
popularityPredictionFactor setting regulates how much the algorithm should rely
on predicted popularity. A high prediction factor allows rising content to quickly
rise to high popularity but can also cause unpopular content with a sudden burst
of requests to wrongfully rise to the top. A low prediction factor can cause
stagnation in the popularity ranking, not allowing new popular content to rise
to the top.
Unpopular content decays in popularity, the magnitude of which is regulated by
popularityDecayFraction. A high value will aggressively decay content
popularity on every decay update while a low value will bloat the ranking,
causing stagnation. Once content decays to a trivially low popularity score, it
is pruned from the content popularity list.
When configuring these tuning parameters, the most crucial data to consider is
the size of your asset catalog, i.e. the number of unique contents you offer.
The recommended values, obtained through testing, are presented in the table below.
Note that the popularityPredictionFactor setting is the principal factor in
controlling the algorithm’s behaviour.
| Catalog size n | Popularity prediction factor | Popularity decay fraction |
|---|---|---|
| n < 1000 | 2.2 | 0.2 |
| 1000 < n < 5000 | 2.3 | 0.2 |
| 5000 < n < 10000 | 2.5 | 0.2 |
| n > 10000 | 2.6 | 0.2 |
Time-Based Algorithm
The time based algorithm only requires the configuration parameter
intervalsPerHour. As an example, setting intervalsPerHour to 10
would give 10 six minute intervals per hour. During each interval,
all unique content requests has an associated counter, increasing
by one for each incoming request. After an hour, all intervals have
been cycled through. The counters in the first interval will be reset
and all incoming content requests will increase the counters in the
first interval again. This cycle continues forever.
When determining a single content’s popularity, the sum of each content’s counter in all intervals is used to determine a popularity ranking.
1.1.5.8.2 - Consistent Hashing
Consistent hashing based routing is a feature that can be used to distribute requests to a set of hosts in a cache friendly manner. By using AgileTV’s consistent distributed hash algorithm, the amount of cache redistribution is minimized within a set of hosts. Requests for a content will always be routed to the same set of hosts, the amount of which is configured by the spread factor, allowing high cache usage. When adding or removing hosts, the algorithm minimizes cache redistribution.
Say you have the host group [s1, s2, s3, s4, s5] and have
configured spreadFactor = 3. A request for a content asset1 would then be
routed to the same three hosts with one of them being selected randomly for each
request. Requests for a different content asset2 would also be routed to one
of three different hosts, most likely a different combination of hosts than
requests for content asset1.
Example routing results with spreadFactor = 3:
- Request for
asset1→ route to one of[s1, s3, s4]. - Request for
asset2→ route to one of[s2, s4, s5]. - Request for
asset3→ route to one of[s1, s2, s5].
Since consistent hashing based routing ensures that requests for a specific content always get routed to the same set of hosts, the risk of cache misses are lowered on the hosts since they will be served the same content requests over and over again.
Note that the maximum value of
spreadFactoris 64. Consequently, the highest amount of hosts you can use in aconsistentHashingrule block is 64.
Three different hashing algorithms are available: MD5, SDBM and Murmur.
The algorithm is chosen during configuration.
Configuration
Configuring consistent hashing based routing is easily done using confcli. Let’s configure the example described above:
confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: consistentHashing
Adding a 'consistentHashing' element
rule : {
name (default: ): consistentHashingRule
type (default: consistentHashing):
spreadFactor (default: 1): 3
hashAlgorithm (default: MD5):
targets : [
target : {
target (default: ): s1
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): s2
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): s3
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): s4
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): s5
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: n
]
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "consistentHashingRule",
"type": "consistentHashing",
"spreadFactor": 3,
"hashAlgorithm": "MD5",
"targets": [
{
"target": "s1",
"enabled": true
},
{
"target": "s2",
"enabled": true
},
{
"target": "s3",
"enabled": true
},
{
"target": "s4",
"enabled": true
},
{
"target": "s5",
"enabled": true
}
]
}
]
}
Adding Hosts
Adding a host to the list will give an additional target for the consistent hashing algorithm to route requests to. This will shift content distribution onto the new host.
confcli services.routing.rules.consistentHashingRule.targets -w
Running wizard for resource 'targets'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
targets : [
target : {
target (default: ): s6
enabled (default: True):
}
Add another 'target' element to array 'targets'? [y/N]: n
]
Generated config:
{
"targets": [
{
"target": "s6",
"enabled": true
}
]
}
Merge and apply the config? [y/n]: y
Removing Hosts
There is one very important caveat of using a consistent hashing rule block. As long as you don’t modify the list of hosts, the consistent hashing algorithm will keep routing requests to the same hosts. However, if you remove a host from the block in any position except the last, the consistent hashing algorithm’s behaviour will change and the algorithm cannot maintain a minimum amount of cache redistribution.
If you’re in a situation where you have to remove a host from the routing
targets but want to keep the same consistent hashing behaviour, e.g. during
very high load, you’ll have to toggle that target’s enabled field to false.
E.g., disabling requests to s2 can be accomplished by:
$ confcli services.routing.rules.consistentHashingRule.targets.1.enabled false
services.routing.rules.consistentHashingRule.targets.1.enabled = False
$ confcli services.routing.rules.consistentHashingRule.targets.1
{
"1": {
"target": "s2",
"enabled": false
}
}
If you modify the list order or remove hosts, it is highly recommended to do so during moments where a higher rate of cache misses are acceptable.
1.1.5.8.3 - Security token verification
The security token verification feature allows for ESB3024 Router to only process requests that contain a correct security token. The token is generated by the client, for example in the portal, using an algorithm that it shares with the router. The router verifies the token and rejects the request if the token is incorrect.
It is beyond the scope of this document to describe how the token is generated, that is described in the Security Tokens application note that is installed with the ESB3024 Router’s extra documentation.
Setting up a Routing Rule
The token verification is performed by calling the verify_security_token()
function from a routing rule. The function returns 1 if the token is
correct, otherwise it returns 0. It should typically be called from the
first routing rule, to make requests with bad tokens fail as early as possible.
The confcli example assumes that the router already has rules configured, with
an entry point named select_cdn. Token verification is enabled by inserting an
“allow” rule first in the rule list.
confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: allow
Adding a 'allow' element
rule : {
name (default: ): token_verification
type (default: allow):
condition (default: always()): verify_security_token()
onMatch (default: ): select_cdn
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "token_verification",
"type": "allow",
"condition": "verify_security_token()",
"onMatch": "select_cdn"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.entrypoint token_verification
services.routing.entrypoint = 'token_verification'
"routing": {
"id": "token_verification",
"member_order": "sequential",
"members": [
{
"id": "token_verification.0.select_cdn",
"member_order": "weighted",
"members": [
...
],
"weight_function": "return verify_security_token() ~= 0"
},
{
"id": "token_verification.1.rejected",
"member_order": "sequential",
"members": [],
"weight_function": "return 1"
}
],
"weight_function": "return 100"
},Configuring Security Token Options
The secret parameter is not part of the router request, but needs to be
configured separately in the router. That can be done with the host-config
tool that is installed with the router.
Besides configuring the secret, host-config can also configure floating
sessions and a URL prefix. Floating sessions are sessions that are not tied to a
specific IP address. When that is enabled, the token verification will not take
the IP address into account when verifying the token.
The security token verification is configured per host, where a host is the name
of the host that the request was sent to. This makes it possible for a router to
support multiple customer accounts, each with their own secret. If no
configuration is found for a host, a configuration with the name default is
used.
host-config supports three commands: print, set and delete.
The print command prints the current configuration for a host. The following
parameters are supported:
host-config print [-n <host-name>]
By default it prints the configuration for all hosts, but if the optional -n
flag is given it will print the configuration for a single host.
Set
The set command sets the configuration for a host. The configuration is given
as command line parameters. The following parameters are supported:
host-config set
-n <host-name>
[-f floating]
[-p url-prefix]
[-r <secret-to-remove>]
[-s <secret-to-add>]
-n <host-name>- The name of the host to configure.-f floating- A boolean option that specifies if floating sessions are accepted. The parameter accepts the valuestrueandfalse.-p url-prefix- A URL prefix that is used for identifying requests that come from a certain account. This is not used when verifying tokens.-r <secret-to-remove>- A secret that should be removed from the list of secrets.-s <secret-to-add>- A secret that should be added to the list of secrets.
For example, to set the secret “secret-1” and enable floating sessions for the default host, the following command can be used:
host-config set -n default -s secret-1 -f true
The set command only touches the configuration options that are mentioned on
the command line, so the following command line will add a second secret to the
default host without changing the floating session setting:
host-config set -n default -s secret-2
It is possible to set multiple secrets per host. This is useful when updating a secret, then both the old and the new secret can be valid during the transition period. After the transition period the old secret can be removed by typing:
host-config set -n default -r secret-1
Delete
The delete command deletes the configuration for a host. It supports the
following parameters:
host-config delete -n <host-name>
For example, to delete the configuration for example.com, the following
command can be used:
host-config delete -n example.com
Global Options
host-config also has a few global options. They are:
-k <security-key>- The security key that is used when communicating with the router. This is normally retrieved automatically.-h- Print a help message and exit.-r <router>- The router to connect to. This default tolocalhost, but can be changed to connect to a remote router.-v- Verbose output, can be given multiple times.
Debugging Security Token Verification
The security token verification only logs messages when the log level is set to
4 or higher. Then it will only log some errors. It is possible to enable more
verbose logging using the security-token-config that is installed together
with the router.
When verbose logging is enabled, the router will log information about the token verification, including the configured token secrets, so it needs to be used with care.
The logged lines are prefixed with verify_security_token.
The security-token-config tool supports the commands print and set.
The print command prints the current configuration. If nothing is configured
it will not print anything.
Set
The set command sets the configuration. The following parameters are
supported:
security-token-config set
[-d <enabled>]
-d <enabled>- A boolean option that specifies if debug logging should be enabled or not. The parameter accepts the valuestrueandfalse.
1.1.5.8.4 - Subnets API
ESB3024 Router provides utilities to quickly match clients into subnets. Any combination of IPv4 and IPv6 addresses can be used. To begin, a JSON file is needed, defining all subnets, e.g:
{
"255.255.255.255/24": "area1",
"255.255.255.255/16": "area2",
"255.255.255.255/8": "area3",
"90.90.1.3/16": "area4",
"5.5.0.4/8": "area5",
"2a02:2e02:9bc0::/48": "area6",
"2a02:2e02:9bc0::/32": "area7",
"2a02:2e02:9bc0::/16": "area8",
"2a02:2e02:9de0::/44": "combined_area",
"2a02:2e02:ada0::/44": "combined_area"
}
and PUT it to the endpoint :5001/v1/subnets or :5001/v2/subnets, the
API version doesn’t matter for subnets:
curl -k -T subnets.json -H "Content-Type: application/json" https://router-host:5001/v1/subnets
Note that it is possible for several subnet CIDR strings to share the same label, effectively grouping them together.
The router provides the built-in function in_subnet(subnet_name) that
can to make routing decisions based on a client’s subnet. For more details, see
Built-in Lua functions.
To configure a rule that only allows clients in the area1 subnet, run the
command
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: allow
Adding a 'allow' element
rule : {
name (default: ): only_allow_area1
type (default: allow):
condition (default: always()): in_subnet('area1')
onMatch (default: ): example-host
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "only_allow_area1",
"type": "allow",
"condition": "in_subnet('area1')",
"onMatch": "example-host"
}
]
}
Merge and apply the config? [y/n]: y
Invalid IP-addresses will be omitted during subnet list construction accompanied by a message in the log displaying the invalid IP address.
1.1.5.8.5 - Lua Features
1.1.5.8.5.1 - Built-in Lua Functions
This section details all built-in Lua functions provided by the router.
Logging Functions
The router provides Lua logging functionality that is convenient when creating custom Lua functions. A prefix can be added to the log message which is useful to differentiate log messages from different lua files. At the top of the Lua source file, add the line
local log = log.add_prefix("my_lua_file")
to prepend all log messages with "my_lua_file".
The logging functions support formatting and common log levels:
log.critical('A log message with number %d', 1.5)
log.error('A log message with string %s', 'a string')
log.warning('A log message with integer %i', 1)
log.info('A log message with a local number variable %d', some_local_number)
log.debug('A log message with a local string variable %s', some_local_string)
log.trace('A log message with a local integer variable %i', some_local_integer)
log.message('A log message')
Many of the router’s built-in Lua functions use the logging functions.
Predictive Load-Balancing Functions
Predictive load balancing is a tool that can be used to avoid overloading hosts with traffic. Consider the case where a popular event starts at a certain time, let’s say 12 PM. A spike in traffic will be routed to the hosts that are streaming the content at 12 PM, most of them starting at low bitrates. A host might have sufficient bandwidth left to take on more clients but when the recently connected clients start ramping up in video quality and increase their bitrate, the host can quickly become overloaded, possibly dropping incoming requests or going offline. Predictive load balancing solves this issue by considering how many times a host recently been redirected to.
Four functions for predictive load balancing are provided by the router
that can be used when constructing conditions/weight functions: host_bitrate()
, host_bitrate_custom(), host_has_bw() and host_has_bw_custom().
All require data to be supplied to the selection input API and apply
only to leaf nodes in the routing tree. In order for predictive load balancing
to work properly the data must be updated at regular intervals. The data needs
to be supplied by the target system.
These functions are suitable to used as host health checks. To configure host health checks, see configuring CDNs and hosts.
Note that host_bitrate() and host_has_bw() rely on data supplied by metrics
agents, detailed in Cache hardware metrics: monitoring and routing.
host_bitrate_custom() and host_has_bw_custom() rely on
manually supplied selection input data, detailed in selection input API. The
bitrate unit depends on the data submitted to the selection input API.
Example Metrics
The data supplied to the selection input API by the metrics agents uses the following structure:
{
"streamer-1": {
"hardware_metrics": {
"/": {
"free": 1741596278784,
"total": 1758357934080,
"used": 16761655296,
"used_percent": 0.9532561585516977
},
"cpu_load1": 0.02,
"cpu_load15": 0.12,
"cpu_load5": 0.02,
"mem_available": 4895789056,
"mem_available_percent": 59.551760354263074,
"mem_total": 8221065216,
"mem_used": 2474393600,
"n_cpus": 4
},
"per_interface_metrics": {
"eths1": {
"link": 1,
"interface_up": true,
"megabits_sent": 22322295739.378456,
"megabits_sent_rate": 8085.2523952,
"speed": 100000
}
}
}
}
Note that all built-in functions interacting with selection input values support indexing into nested selection input data. Consider the selection input data in above. The nested values can be accessed by using dots between the keys:
si('streamer-1.per_interface_metrics.eths1.megabits_sent_rate')
Note that the whole selection input variable name must be within single quotes.
The function si() is documented under
general purpose functions.
host_bitrate({})
host_bitrate() returns the predicted bitrate (in megabits per second) of
the host after the recently connected clients start ramping up in streaming
quality. The function accepts an argument table with the following keys:
interface: The name of the interface to use for bitrate prediction.- Optional
avg_bitrate: the average bitrate per client, defaults to 6 megabits per second. - Optional
num_routers: the number of routers that can route to this host, defaults to 1. This is important to accurately predict the incoming load if multiple routers are used. - Optional
host: The name of the host to use for bitrate prediction. Defaults to the current host if not provided.
Required Selection Input Data
This function relies on the field megabits_sent_rate, supplied by the Telegraf
metrics agent, as seen in example metrics. If these fields
are missing from your selection input data, this function will not work.
Examples of usage:
host_bitrate({interface='eths0'})
host_bitrate({avg_bitrate=1, interface='eths0'})
host_bitrate({num_routers=2, interface='eths0'})
host_bitrate({avg_bitrate=1, num_routers=4, interface='eths0'})
host_bitrate({avg_bitrate=1, num_routers=4, host='custom_host', interface='eths0'})
host_bitrate({}) calculates the predicted bitrate as:
predicted_host_bitrate = current_host_bitrate + (recent_connections * avg_bitrate * num_routers)
host_bitrate_custom({})
Same functionality as host_bitrate() but uses a custom selection input
variable as bitrate input instead of accessing hardware metrics. The function
accepts an argument table with the following keys:
custom_bitrate_var: The name of the selection input variable to be used for accessing current host bitrate.- Optional
avg_bitrate: seehost_bitrate()documentation above. - Optional
num_routers: seehost_bitrate()documentation above.
host_bitrate_custom({custom_bitrate_var='host1_current_bitrate'})
host_bitrate_custom({avg_bitrate=1, custom_bitrate_var='host1_current_bitrate'})
host_bitrate_custom({num_routers=4, custom_bitrate_var='host1_current_bitrate'})
host_has_bw({})
Instead of accessing the predicted bitrate of a host through host_bitrate(),
host_has_bw() returns 1 if the host is predicted to have enough
bandwidth left to take on more clients after recent connections ramp up in
bitrate, otherwise it returns 0. The function accepts an argument table with the
following keys:
interface: seehost_bitrate()documentation above.- Optional
avg_bitrate: seehost_bitrate()documentation above. - Optional
num_routers: seehost_bitrate()documentation above. - Optional
host: seehost_bitrate()documentation above. - Optional
margin: the bitrate (megabits per second) headroom that should be taken into account during calculation, defaults to 0.
host_has_bw({}) returns whether or not the following statement is true:
predicted_host_bitrate + margin < host_bitrate_capacity
Required Selection Input Data
host_has_bw({}) relies on the fields megabits_sent_rate and speed,
supplied by the Telegraf metrics agent, as seen in
example metrics. If these fields are missing from your
selection input data, this function will not work.
Examples of usage:
host_has_bw({interface='eths0'})
host_has_bw({margin=10, interface='eth0'})
host_has_bw({avg_bitrate=1, interface='eth0'})
host_has_bw({num_routers=4, interface='eth0'})
host_has_bw({host='custom_host', interface='eth0'})
host_has_bw_custom({})
Same functionality as host_has_bw() but uses a custom selection input
variable as bitrate. It also uses a number or a custom selection input
variable for the capacity. The function accepts an argument table
with the following keys:
custom_capacity_var: a number representing the capacity of the network interface OR the name of the selection input variable to be used for accessing host capacity.custom_bitrate_var: seehost_bitrate_custom()documentation- Optional
margin: seehost_has_bw()documentation above. above. - Optional
avg_bitrate: seehost_bitrate()documentation above. - Optional
num_routers: seehost_bitrate()documentation above.
Examples of usage:
host_has_bw_custom({custom_capacity_var=10000, custom_bitrate_var='streamer-1.per_interface_metrics.eths1.megabits_sent_rate'})
host_has_bw_custom({custom_capacity_var='host1_capacity', custom_bitrate_var='streamer-1.per_interface_metrics.eths1.megabits_sent_rate'})
host_has_bw_custom({margin=10, custom_capacity_var=10000, custom_bitrate_var='streamer-1.per_interface_metrics.eths1.megabits_sent_rate'})
host_has_bw_custom({avg_bitrate=1, custom_capacity_var=10000, custom_bitrate_var='streamer-1.per_interface_metrics.eths1.megabits_sent_rate'})
host_has_bw_custom({num_routers=4, custom_capacity_var=10000, custom_bitrate_var='streamer-1.per_interface_metrics.eths1.megabits_sent_rate'})
Health Check Functions
This section details built-in Lua functions that are meant to be used for host health checks. Note that these functions rely on data supplied by metric agents detailed in Cache hardware metrics: monitoring and routing. Make sure cache hardware metrics are supplied to the router before using any of these functions.
cpu_load_ok({})
The function accepts an optional argument table with the following keys:
- Optional
host: The name of the host. Defaults to the name of the selected host if not provided. - Optional
cpu_load5_limit: The acceptable limit for the 5-minute CPU load. Defaults to 0.9 if not provided.
The function returns 1 if the five minute CPU load average is below their respective limits, and 0 otherwise.
Examples of usage:
cpu_load_ok()
cpu_load_ok({host = 'custom_host'})
cpu_load_ok({cpu_load5_limit = 0.8})
cpu_load_ok({host = 'custom_host', cpu_load5_limit = 0.8})
memory_usage_ok({})
The function accepts an optional argument table with the following keys:
- Optional
host: The name of the host. Defaults to the host of the selected host if not provided. - Optional
memory_usage_limit: The acceptable limit for the memory usage. Defaults to 0.9 if not provided.
The function returns 1 if the memory usage is below the limit, and 0 otherwise.
Examples of usage:
memory_usage_ok()
memory_usage_ok({host = 'custom_host'})
memory_usage_ok({memory_usage_limit = 0.7})
memory_usage_ok({host = 'custom_host', memory_usage_limit = 0.7})
interfaces_online({})
The function accepts an argument table with the following keys:
- Required
interfaces: A string or a table of strings representing the network interfaces to check. - Optional
host: The name of the host. Defaults to the host of the selected host if not provided.
The function returns 1 if all the specified interfaces are online, and 0 otherwise.
Required Selection Input Data
This function relies on the fields link and interface_up, supplied by
the Telegraf metrics agent, as seen in example metrics. If
these fields are missing from your selection input data, this function will not
work.
Examples of usage:
interfaces_online({interfaces = 'eth0'})
interfaces_online({interfaces = {'eth0', 'eth1'}})
interfaces_online({host = 'custom_host', interfaces = 'eth0'})
interfaces_online({host = 'custom_host', interfaces = {'eth0', 'eth1'}})
health_check({})
The function accepts an optional argument table with the following keys:
- Required
interfaces: A string or a table of strings representing the network interfaces to check. - Optional
host: The name of the host. Defaults to the host of the selected host if not provided. - Optional
cpu_load5_limit: The acceptable limit for the 5-minute CPU load. Defaults to 0.9 if not provided. - Optional
memory_usage_limit: The acceptable limit for the memory usage. Defaults to 0.9 if not provided.
The function calls the health check functions cpu_load_ok({}),
memory_usage_ok({}) and interfaces_online({}). The functions returns 1 if
all these functions returned 1, otherwise it returns 0.
Examples of usage:
health_check({interfaces = 'eths0'})
health_check({host = 'custom_host', interfaces = 'eths0'})
health_check({cpu_load5_limit = 0.7, memory_usage_limit = 0.8, interfaces = 'eth0'})
health_check({host = 'custom_host', cpu_load5_limit = 0.7, memory_usage_limit = 0.8, interfaces = {'eth0', 'eth1'}})
General Purpose Functions
The router supplies a number of general purpose Lua functions.
always()
Always returns 1.
never()
Always returns 0. Useful for temporarily disabling caches by using it as a health check.
Examples of usage:
always()
never()
si(si_name)
The function reads the value of the selection input variable si_name and
returns it if it exists, otherwise it returns 0. The function accepts a string
argument for the selection input variable name.
Examples of usage:
si('some_selection_input_variable_name')
si('streamer-1.per_interface_metrics.eths1.megabits_sent_rate')
Comparison functions
All comparison functions use the form function(si_name, value) and compares
the selection input value with the name si_name with value.
ge(si_name, value) - greater than or equal
gt(si_name, value) - greater than
le(si_name, value) - less than or equal
lt(si_name, value) - less than
eq(si_name, value) - equal to
neq(si_name, value) - not equal to
Examples of usage:
ge('streamer-1.hardware_metrics.mem_available_percent', 30)
gt('streamer-1.hardware_metrics./.free', 1000000000)
le('streamer-1.hardware_metrics.cpu_load5', 0.8)
lt('streamer-1.per_interface_metrics.eths1.megabits_sent_rate', 9000)
eq('streamer-1.per_interface_metrics.eths1.link.', 1)
neq('streamer-1.hardware_metrics.n_cpus', 4)
Session Checking Functions
in_subnet(subnet)
Returns 1 if the current session belongs to subnet, otherwise it returns 0.
See Subnets API for more details on how to use
subnets in routing. The function accepts a string argument for the subnet name.
Examples of usage:
in_subnet('stockholm')
in_subnet('unserviced_region')
in_subnet('some_other_subnet')
These functions checks the current session’s session groups.
in_session_group(session_group)
Returns 1 if the current session has been classified into session_group,
otherwise it returns 0. The function accepts a string argument for the session
group name.
in_any_session_group({})
Returns 1 if the current session has been classified into any of
session_groups, otherwise it returns 0. The function accepts a table array of
strings as argument for the session group names.
in_all_session_groups({})
Returns 1 if the current session has been classified into all of
session_groups, otherwise it returns 0. The function accepts a table array of
strings as argument for the session group names.
Examples of usage:
in_session_group('safari_browser')
in_any_session_group({ 'in_europe', 'in_asia'})
in_all_session_group({ 'vod_content', 'in_america'})
Other built-in functions
base64_encode(data)
base64_encode(data) returns the base64 encoded string of data.
Arguments:
data: The data to encode.
Example:
print(base64_encode('Hello world!'))
SGVsbG8gd29ybGQh
base64_decode(data)
base64_decode(data) returns the decoded data of the base64 encoded string, as
a raw binary string.
Arguments:
data: The data to decode.
Example:
print(base64_decode('SGVsbG8gd29ybGQh'))
Hello world!
base64_url_encode(data)
base64_url_encode(data) returns the base64 URL encoded string of data.
Arguments:
data: The data to encode.
Example:
print(base64_url_encode('ab~~'))
YWJ-fg
base64_url_decode(data)
base64_url_decode(data) returns the decoded data of the base64 URL encoded
string, as a raw binary string.
Arguments:
data: The data to decode.
Example:
print(base64_url_decode('YWJ-fg'))
ab~~
to_hex_string(data)
to_hex_string(data) returns a string containing the hexadecimal
representation of the string data.
Arguments:
data: The data to convert.
Example:
print(to_hex_string('Hello world!\n'))
48656c6c6f20776f726c64210a
from_hex_string(data)
from_hex_string(data) returns a string containing the byte representation of
the hexadecimal string data.
Arguments:
data: The data to convert.
Example:
print(from_hex_string('48656c6c6f20776f726c6421'))
Hello world!
empty(table)
empty(table) returns true if table is empty, otherwise it returns false.
Arguments:
table: The table to check.
Examples:
print(tostring(empty({})))
true
print(tostring(empty({1, 2, 3})))
false
md5(data)
md5(data) returns the MD5 hash of data, as a hexstring.
Arguments:
data: The data to hash.
Example:
print(md5('Hello world!'))
86fb269d190d2c85f6e0468ceca42a20
sha256(date)
sha256(data) returns the SHA-256 hash of data, as a hexstring.
Arguments:
data: The data to hash.
Example:
print(sha256('Hello world!'))
c0535e4be2b79ffd93291305436bf889314e4a3faec05ecffcbb7df31ad9e51a
hmac_sha256(key, data)
hmac_sha256(key, data) returns the HMAC-SHA-256 hash of data using key,
as a string containing raw binary data.
Arguments:
key: The key to use.data: The data to hash.
Example:
print(to_hex_string(hmac_sha256('secret', 'Hello world!')))
a65f4cfcf5f421ff2be052e0642bccbcfeb126ee73ebc4fe3b381964302eb632
hmac_sha384(key, data)
hmac_sha384(key, data) returns the HMAC-SHA-384 hash of data using key,
as a string containing raw binary data.
Arguments:
key: The key to use.data: The data to hash.
Example:
print(to_hex_string(hmac_sha384('secret', 'Hello world!')))
917516d93d3509a371a129ca50933195dd659712652f07ba5792cbd5cade5e6285a841808842cfa0c3c69c8fb234468a
hmac_sha512(key, data)
hmac_sha512(key, data) returns the HMAC-SHA-512 hash of data using key,
as a string containing raw binary data.
Arguments:
key: The key to use.data: The data to hash.
Example:
print(to_hex_string(hmac_sha512('secret', 'Hello world!')))
dff6c00943387f9039566bfee0994de698aa2005eecdbf12d109e17aff5bbb1b022347fbf4bd94ede7c7d51571022525556b64f9d5e4386de99d0025886eaaff
hmac_md5(key, data)
hmac_md5(key, data) returns the HMAC-MD5 hash of data using key,
as a string containing raw binary data.
Arguments:
key: The key to use.data: The data to hash.
Example:
print(to_hex_string(hmac_md5('secret', 'Hello world!')))
444fad0d374d14369d6b595062da5d91
regex_replace
regex_replace(data, pattern, replacement) returns the string data with all
occurrences of the regular expression pattern replaced with replacement.
Arguments:
data: The data to replace.pattern: The regular expression pattern to match.replacement: The replacement string.
Examples:
print(regex_replace('Hello world!', 'world', 'Lua'))
Hello Lua!
print(regex_replace('Hello world!', 'l+', 'lua'))
Heluao worluad!
If the regular expression pattern is invalid, regex_replace() returns an
error message.
Examples:
print(regex_replace('Hello world!', '*', 'lua'))
regex_error caught: regex_error
unixtime()
unixtime() returns the current Unix timestamp, as seconds since midnight,
Janury 1 1970 UTC, as an integer.
Arguments:
- None
Example:
print(unixtime())
1733517373
now()
now() returns the current Unix timestamp, the number of seconds since
midnight, Janury 1 1970 UTC, as an number with decimals.
Arguments:
- None
Example:
print(now())
1733517373.5007
time_to_epoch(time, fmt)
time_to_epoch(time, fmt) returns the Unix timestamp, the number of seconds
since midnight, Janury 1 1970 UTC, of the time string time, which is
formatted according to the format string fmt.
Arguments:
time: The time string to convert.fmt(Optional): The format string of the time string, as specified by the POSIX function strptime(). If not specified, it defaults to “%Y-%m-%dT%TZ”.
Examples:
print(time_to_epoch('1972-04-17T06:10:20Z'))
72339020
print(time_to_epoch('17/04-72 06:20:30', '%d/%m-%y %H:%M:%S'))
72339630
epoch_to_time(time, format)
epoch_to_time(time, format) returns the time string of the Unix timestamp
time, formatted according to format.
Arguments:
time: The Unix timestamp to convert, as a number.format(Optional): The format string of the time string, as specified by the POSIX function strftime(). If not specified, it defaults to “%Y-%m-%dT%TZ”.
Examples:
print(epoch_to_time(123456789))
1973-11-29T21:33:09Z
print(epoch_to_time(1234567890, '%d/%m-%y %H:%M:%S'))
13/02-09 23:31:30
get_consistent_hashing_weight(contentName, nodeIdsString, spreadFactor, hashAlgoritm, nodeId)
get_consistent_hashing_weight(contentName, nodeIdsString, spreadFactor, hashAlgoritm, nodeId)
returns the priority that node nodeId has in the list of preferred nodes,
determined using consistent hashing. The first spreadfactor:th nodes should
have equal weights to randomize requests between them. Remaining nodes should
have decrementally decreasing weights to honor node priority during failover.
Arguments:
contentName: The name of the content to hash.nodeIdsString: A string containing the node IDs to hash, on the format ‘0,1,2,3’.spreadFactor: The number of nodes to spread the requests between.hashAlgorithm: Which hash algorithm to use. Supported algorithms are “MD5”, “SDBM” and “Murmur”. Default is “MD5”.nodeId: The ID of the node to calculate the weight for.
Examples:
print(get_consistent_hashing_weight('/vod/film1', '0,1,2,3,4,5', 3, 'MD5', 3))
6
print(get_consistent_hashing_weight('/vod/film2', '0,1,2,3,4,5', 3, 'MD5', 3))
4
print(get_consistent_hashing_weight('/vod/film2', '0,1,2', 2, 'Murmur', 1))
2
See Consistent Hashing for more information about consistent hashing.
expand_ipv6_address(address)
expand_ipv6_address(address) returns the fully expanded form of the IPv6
address address.
Arguments:
address: The IPv6 address to expand. If the address is not a valid IPv6 address, the function returns the contents ofaddressunmodified. This allows for the function to pass through IPv4 addresses.
Examples:
print(expand_ipv6_address('2001:db8::1'))
2001:0db8:0000:0000:0000:0000:0000:0001
print(expand_ipv6_address('198.51.100.5'))
198.51.100.5
Data stream related functions
The router provides a number of functions that are useful when working with
data streams. These functions are used to write data to the data stream
configured in the services.routing.dataStreams.outgoing section of the
configuration. See data streams for more information.
send_to_data_stream
send_to_data_stream(data_stream, message) sends the string message to the
outgoing data stream data_stream. Note that message is sent verbatim,
without any formatting.
Arguments:
data_stream: The name of the data stream to send to.message: The message to send.
Example:
-- Sends the message "Hello world!" to the data stream 'token_stream'
send_to_data_stream('token_stream', 'Hello world!')
data_streams.post_selection_key_value
data_streams.post_selection_key_value(data_stream, path, key, value, ttl_s)
posts the key-value pair key=value on the path path to the data stream
data_stream. The key-value is formatted as a selection input value
{key: value}, will be stored in path and will persist for ttl_s seconds.
This is the same format that is expected when parsing data from incoming data
streams of the type "selectionInput" to read selection input data from
external data streams. This means that this function can be used to post
selection input data to an external data stream, which can then be read by
other Director instances.
Arguments:
data_stream: The name of the data stream to post to.path: The path to post the key-value pair to. Note that the path is automatically prefixed with"/v2/selection_input".key: The key to post.value: The value to post.- Optional
ttl_s: The time to live of the key-value pair, in seconds. If not specified, it will persist forever.
Example:
-- Posts the selection input value {"si_var": 1337} on the path "/v2/selection_input/path"
-- to the data stream 'outgoingDataStream' with a TTL of 60 seconds
data_streams.post_selection_key_value('outgoingDataStream', '/path', 'si_var', 1337, 60)
Token blocking functions
The router provides a number of functions that are useful when working with token blocking to control CDN access.
blocked_tokens.augment_token(token, customer_id)
Returns an augmented token string formatted like <customer_id>__<token>. This
function is useful when additional information is needed for token blocking,
such as customer ID.
Arguments:
token: The token to augment.customer_id: The customer ID to augment the token with.
Example:
-- Augments the token eyJhbG213 with the customer ID 12345
local augmented_token = blocked_tokens.augment_token('eyJhbG213', '12345')
print(augmented_token)
12345__eyJhbG213
blocked_tokens.add(stream_name, token, ttl_s)
blocked_tokens.add() is a specialized version of
data_streams.post_selection_key_value() that is commonly used to synchronize
blocked tokens between multiple Directors to deny unpermitted access into a CDN.
It posts selection input data to the data stream stream_name which is consumed
into selection input by all connected Director instances so that the blocked
token can easily be checked during routing by calling blocked_tokens.is_blocked(token).
Arguments:
stream_name: The name of the data stream to post to.token: The token to post.- Optional
ttl_s: The time to live of the token, in seconds. Defaults to 3 hours (10800 seconds) if not specified.
Example:
-- Posts the token eyJhbG213 with a TTL of 3 hours
blocked_tokens.add('token_stream', 'eyJhbG213')
-- Posts the token R5cCI6Ik with a TTL of 60 seconds
blocked_tokens.add('token_stream', 'R5cCI6Ik', 60)
blocked_tokens.is_blocked(token)
blocked_tokens.is_blocked(token) checks if the token token has been blocked
by checking if it is stored in selection input. It returns true if the token is
blocked, otherwise it returns false.
Arguments:
token: The token to check.
Example:
-- Checks if the token eyJhbG213 is blocked
blocked_tokens.is_blocked('eyJhbG213')
-- Checks if the augmented token 12345__eyJhbG213 is blocked
blocked_tokens.is_blocked(blocked_tokens.augment_token('eyJhbG213', '12345'))
blocked_tokens.is_blocked('12345__eyJhbG213')
Custom Lua Metrics functions
The router provides functions for managing custom metrics counters that will be available in the OpenMetrics format on the router’s metrics API.
increase_metrics_counter(counter_name, label_table, amount)
increase_metrics_counter(counter_name, label_table, amount) increases the
custom metrics counter counter_name by amount. The counter is identified by
the label_table which is a table of key-value pairs.
Arguments:
counter_name: The name of the counter to increase.label_table: A table of key-value pairs to identify the counter.- Optional
amount: The amount to increase the counter by. Defaults to 1 if not defined.
Example:
-- Increases the counter 'my_counter' by 1
increase_metrics_counter('my_counter', {label='foo'})
-- Increases the counter 'another_counter' by 5
increase_metrics_counter('another_counter', {label1='value1', label2='value2'}, 5)
These examples will create the following metrics:
# TYPE my_counter counter
my_counter{label="foo"} 1
# TYPE another_counter counter
another_counter{label1="value1", label2="value2"} 5
reset_metrics_counter(counter_name, label_table)
reset_metrics_counter(counter_name, label_table) removes the custom metrics
counter counter_name with the labels defined in label_table.
Arguments:
counter_name: The name of the counter to remove.label_table: A table of key-value pairs to identify the counter.
Example:
-- Removes the counter 'my_counter'
reset_metrics_counter('my_counter', {label='foo'})
-- Removes the counter 'another_counter'
reset_metrics_counter('another_counter', {label1='value1', label2='value2'})
Configuration examples
Many of the functions documented are suitable to use in host health checks. To configure host health checks, see configuring CDNs and hosts. Here are some configuration examples of using the built-in Lua functions, utilizing the example metrics:
"healthChecks": [
"gt('streamer-1.hardware_metrics.mem_available_percent', 20)", // More than 20% memory is left
"lt('streamer-1.per_interface_metrics.eths1.megabits_sent_rate', 9000)" // Current bitrate is lower than 9000 Mbps
"host_has_bw({host='streamer-1', interface='eths1', margin=1000})", // host_has_bw() uses 'streamer-1.per_interface_metrics.eths1.speed' to determine if there is enough bandwidth left with a 1000 Mbps margin
"interfaces_online({host='streamer-1', interfaces='eths1'})",
"memory_usage_ok({host='streamer-1'})",
"cpu_load_ok({host='streamer-1'})",
"health_check({host='streamer-1', interfaces='eths1'})" // Combines interfaces_online(), memory_usage_ok(), cpu_load_ok()
]
1.1.5.8.5.2 - Global Lua Tables
There are multiple global tables containing important data available while writing Lua code for the router.
selection_input
Contains arbitrary, custom fields fed into the router by clients, see API overview for details on how to inject data into this table.
Note that the selection_input table is iterable.
Usage examples:
print(selection_input['some_value'])
-- Iterate over table
if selection_input then
for k, v in pairs(selection_input) do
print('here is '..'selection_input!')
print(k..'='..v)
end
else
print('selection_input is nil')
end
session_groups
Defines a mapping from session group name to boolean, indicating whether
the session belongs to the session group or not.
Usage examples:
if session_groups.vod then print('vod') else print('not vod') end
if session_groups['vod'] then print('vod') else print('not vod') end
session_count
Provides counters of number of session types per session group. The table
uses the structure qoe_score.<session_type>.<session_group>.
Usage examples:
print(session_count.instream.vod)
print(session_count.initial.vod)
qoe_score
Provides the quality of experience score per host per session group. The table
uses the structure qoe_score.<host>.<session_group>.
Usage examples:
print(qoe_score.host1.vod)
print(qoe_score.host1.live)
request
Contains data related to the HTTP request between the client and the router.
request.method- Description: HTTP request method.
- Type:
string - Example:
'GET','POST'
request.body- Description: HTTP request body string.
- Type:
stringornil - Example:
'{"foo": "bar"}'
request.major_version- Description: Major HTTP version such as
xinHTTP/x.1. - Type:
integer - Example:
1
- Description: Major HTTP version such as
request.minor_version- Description: Minor HTTP version such as
xinHTTP/1.x. - Type:
integer - Example:
1
- Description: Minor HTTP version such as
request.protocol- Description: Transfer protocol variant.
- Type:
string - Example:
'HTTP','HTTPS'
request.client_ip- Description: IP address of the client issuing the request.
- Type:
string - Example:
'172.16.238.128'
request.path_with_query_params- Description: Full request path including query parameters.
- Type:
string - Example:
'/mycontent/superman.m3u8?b=y&c=z&a=x'
request.path- Description: Request path without query parameters.
- Type:
string - Example:
'/mycontent/superman.m3u8'
request.query_params- Description: The query parameter string.
- Type:
string - Example:
'b=y&c=z&a=x'
request.filename- Description: The part of the path following the final slash, if any.
- Type:
string - Example:
'superman.m3u8'
request.subnet- Description: Subnet of
client_ip. - Type:
stringornil - Example:
'all'
- Description: Subnet of
session
Contains data related to the current session.
session.client_ip- Description: Alias for
request.client_ip. See documentation for table request above.
- Description: Alias for
session.path_with_query_params- Description: Alias for
request.path_with_query_params. See documentation for table request above.
- Description: Alias for
session.path- Description: Alias for
request.path. See documentation for table request above.
- Description: Alias for
session.query_params- Description: Alias for
request.query_params. See documentation for table request above.
- Description: Alias for
session.filename- Description: Alias for
request.filename. See documentation for table request above.
- Description: Alias for
session.subnet- Description: Alias for
request.subnet. See documentation for table request above.
- Description: Alias for
session.host- Description: ID of the currently selected host for the session.
- Type:
stringornil - Example:
'host1'
session.id- Description: ID of the session.
- Type:
string - Example:
'8eb2c1bdc106-17d2ff-00000000'
session.session_type- Description: Type of the session.
- Type:
string - Example:
'initial'or'instream'. Identical to the value of theTypeargument of the session translation function.
session.is_managed- Description: Identifies managed sessions.
- Type:
boolean - Example:
trueifType/session.session_typeis'instream'
request_headers
Contains the headers from the request between the client and the router, keyed by name.
Usage example:
print(request_headers['User-Agent'])
request_query_params
Contains the query parameters from the request between the client and the router, keyed by name.
Usage example:
print(request_query_params.a)
session_query_params
Alias for metatable request_query_params.
response
Contains data related to the outgoing response apart from the headers.
response.body- Description: HTTP response body string.
- Type:
stringornil - Example:
'{"foo": "bar"}'
response.code- Description: HTTP response status code.
- Type:
integer - Example:
200,404
response.text- Description: HTTP response status text.
- Type:
string - Example:
'OK','Not found'
response.major_version- Description: Major HTTP version such as
xinHTTP/x.1. - Type:
integer - Example:
1
- Description: Major HTTP version such as
response.minor_version- Description: Minor HTTP version such as
xinHTTP/1.x. - Type:
integer - Example:
1
- Description: Minor HTTP version such as
response.protocol- Description: Transfer protocol variant.
- Type:
string - Example:
'HTTP','HTTPS'
response_headers
Contains the response headers keyed by name.
Usage example:
print(response_headers['User-Agent'])
1.1.5.8.5.3 - Request Translation Function
Specifies the body of a Lua function that inspects every incoming HTTP request and overwrites individual fields before further processing by the router.
Returns nil when nothing is to be changed, or HTTPRequest(t) where t
is a table with any of the following optional fields:
Method- Description: Replaces the HTTP request method in the request being processed.
- Type:
string - Example:
'GET','POST'
Path- Description: Replaces the request path in the request being processed.
- Type:
string - Example:
'/mycontent/superman.m3u8'
ClientIp- Description: Replaces client IP address in the request being processed.
- Type:
string - Example:
'172.16.238.128'
Body- Description: Replaces body in the request being processed.
- Type:
stringornil - Example:
'{"foo": "bar"}'
QueryParameters- Description: Adds, removes or replaces individual query parameters in the request being processed.
- Type: nested
table(indexed by number) representing an array of query parameters as{[1]='Name',[2]='Value'}pairs that are added to the request being processed, or overwriting existing query parameters with colliding names. To remove a query parameter from the request, specifynilas value, i.e.QueryParameters={..., {[1]='foo',[2]=nil} ...}. Returning a query parameter with a name but no value, such asain the request'/index.m3u8?a&b=22'is currently not supported.
Headers- Description: Adds, removes or replaces individual headers in the request being processed.
- Type: nested
table(indexed by number) representing an array of request headers as{[1]='Name',[2]='Value'}pairs that are added to the request being processed, or overwriting existing request headers with colliding names. To remove a header from the request, specifynilas value, i.e.Headers={..., {[1]='foo',[2]=nil} ...}. Duplicate names are supported. A multi-value header such asFoo: bar1,bar2is defined by specifyingHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar2'}, ...}.
OutgoingRequest: See Sending HTTP requests from translation functions for more information.
Example of a request_translation_function body that sets the request path
to a hardcoded value and adds the hardcoded query parameter a=b:
-- Statements go here
print('Setting hardcoded Path and QueryParameters')
return HTTPRequest({
Path = '/content.mpd',
QueryParameters = {
{'a','b'}
}
})
Arguments
The following (iterable) arguments will be known by the function:
QueryParameters
Type: nested
table(indexed by number).Description: Array of query parameters as
{[1]='Name',[2]='Value'}pairs that were present in the query string of the request. Format identical to theHTTPRequest.QueryParameters-field specified for the return value above.Example usage:
for _, queryParam in pairs(QueryParameters) do print(queryParam[1]..'='..queryParam[2]) end
Headers
Type: nested
table(indexed by number).Description: Array of request headers as
{[1]='Name',[2]='Value'}pairs that were present in the request. Format identical to theHTTPRequest.Headers-field specified for the return value above. A multi-value header such asFoo: bar1,bar2is seen inrequest_translation_functionasHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar1'}, ...}.Example usage:
for _, header in pairs(Headers) do print(header[1]..'='..header[2]) end
Additional Data
In addition to the arguments above, the following Lua tables, documented in Global Lua Tables, provide additional data that is available when executing the request translation function:
If the request translation function modifies the request, the request,
request_query_params and request_headers tables will be updated with the
modified request and made available to the routing rules.
1.1.5.8.5.4 - Session Translation Function
Specifies the body of a Lua function that inspects a newly created session and may override its suggested type from “initial” to “instream” or vice versa. A number of helper functions are provided to simplify changing the session type.
Returns nil when the session type is to remain unchanged, or Session(t)
where t is a table with a single field:
Type- Description: New type of the session.
- Type:
string - Example:
'instream','initial'
OutgoingRequest: See Sending HTTP requests from translation functions for more information.
Basic Configuration
It is possible to configure the maximum number of simultaneous managed sessions
on the router. If the maximum number is reached, no more managed sessions can be
created. Using confcli, it can be configured by running
$ confcli services.routing.tuning.general.maxActiveManagedSessions
{
"maxActiveManagedSessions": 1000
}
$ confcli services.routing.tuning.general.maxActiveManagedSessions 900
services.routing.tuning.general.maxActiveManagedSessions = 900
Common Arguments
While executing the session translation function, the following arguments are available:
Type: The current type of the session ('instream'or'initial').
Usage examples:
-- Flip session type
local newType = 'initial'
if Type == 'initial' then
newType = 'instream'
end
print('Changing session type from ' .. Type .. ' to ' .. newType)
return Session({['Type'] = newType})
Session Translation Helper Functions
The standard Lua library prodives four helper functions to simplify the configuration of the session translation function:
set_session_type(session_type)
This function will set the session type to the supplied session_type and
the maximum number of sessions of that type has not been reached.
Parameters
session_type: The type of session to create, possible values are ‘initial’ or ‘instream’.
Usage Examples
return set_session_type('instream')
return set_session_type('initial')
set_session_type_if_in_group(session_type, session_group)
This function will set the session type to the supplied session_type if the
session is part of session_group and the maximum number of sessions of that
type has not been reached.
Parameters
session_type: The type of session to create, possible values are ‘initial’ or ‘instream’.session_group: The name of the session group.
Usage Examples
return set_session_type_if_in_group('instream', 'sg1')
set_session_type_if_in_all_groups(session_type, session_groups)
This function will set the session type to the supplied session_type if the
session is part of all session groups given by session_groups and the maximum
number of sessions of that type has not been reached.
Parameters
session_type: The type of session to create, possible values are ‘initial’ or ‘instream’.session_groups: A list of session group names.
Usage Examples
return set_session_type_if_in_all_groups('instream', {'sg1', 'sg2'})
set_session_type_if_in_any_group(session_type)
This function will set the session type to the supplied session_type if the
session is part of one or more of the session groups given by session_groups
and the maximum number of sessions of that type has not been reached.
Parameters
session_type: The type of session to create, possible values are ‘initial’ or ‘instream’.session_groups: A list of session group names.
Usage Examples
return set_session_type_if_in_any_group('instream', {'sg1', 'sg2'})
Configuration
Using confcli, example of how the functions above can be used in the session
translation function can be configured by running any of
$ confcli services.routing.translationFunctions.session "return set_session_type('instream')"
services.routing.translationFunctions.session = "return set_session_type('instream')"
$ confcli services.routing.translationFunctions.session "return set_session_type_if_in_group('instream', 'sg1')"
services.routing.translationFunctions.session = "return set_session_type_if_in_group('instream', 'sg1')"
$ confcli services.routing.translationFunctions.session "return set_session_type_if_in_all_groups('instream', {'sg1', 'sg2'})"
services.routing.translationFunctions.session = "return set_session_type_if_in_all_groups('instream', {'sg1', 'sg2'})"
$ confcli services.routing.translationFunctions.session "return set_session_type_if_in_any_group('instream', {'sg1', 'sg2'})"
services.routing.translationFunctions.session = "return set_session_type_if_in_any_group('instream', {'sg1', 'sg2'})"
Additional Data
In addition to the arguments above, the following Lua tables, documented in Global Lua Tables, provide additional data that is available when executing the response translation function:
The selection_input table will not change while a routing request is handled.
A request_translation_function and the corresponding
response_translation_function will see the same selection_input table, even
if the selection data is updated while the request is being handled.
1.1.5.8.5.5 - Host Request Translation Function
The host request translation function defines a Lua function that modifies
HTTP requests sent to a host. These hosts are configured in
services.routing.hostGroups.
Hosts can receive requests for a manifest. A regular host will respond with the manifest itself, while a redirecting host and a DNS host will respond with a redirection to a streamer. This function can modify all these types of requests.
The function returns nil when nothing is to be changed, or HTTPRequest(t)
where t is a table with any of the following optional fields:
Method- Description: Replaces the HTTP request method in the request being processed.
- Type:
string - Example:
'GET','POST'
Path- Description: Replaces the request path in the request being processed.
- Type:
string - Example:
'/mycontent/superman.m3u8'
Body- Description: Replaces body in the request being processed.
- Type:
stringornil - Example:
'{"foo": "bar"}'
QueryParameters- Description: Adds, removes or replaces individual query parameters in the request being processed.
- Type: nested
table(indexed by number) representing an array of query parameters as{[1]='Name',[2]='Value'}pairs that are added to the request being processed, or overwriting existing query parameters with colliding names. To remove a query parameter from the request, specifynilas value, i.e.QueryParameters={..., {[1]='foo',[2]=nil} ...}. Returning a query parameter with a name but no value, such asain the request'/index.m3u8?a&b=22'is currently not supported.
Headers- Description: Adds, removes or replaces individual headers in the request being processed.
- Type: nested
table(indexed by number) representing an array of request headers as{[1]='Name',[2]='Value'}pairs that are added to the request being processed, or overwriting existing request headers with colliding names. To remove a header from the request, specifynilas value, i.e.Headers={..., {[1]='foo',[2]=nil} ...}. Duplicate names are supported. A multi-value header such asFoo: bar1,bar2is defined by specifyingHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar2'}, ...}.
Host- Description: Replaces the host that the request is sent to.
- Type:
string - Example:
'new-host.example.com','192.0.2.7'
Port- Description: Replaces the TCP port that the request is sent to.
- Type:
number - Example:
8081
Protocol- Description: Decides which protocol that will be used for sending the
request. Valid protocols are
'HTTP'and'HTTPS'. - Type:
string - Example:
'HTTP','HTTPS'
- Description: Decides which protocol that will be used for sending the
request. Valid protocols are
OutgoingRequest: See Sending HTTP requests from translation functions for more information.
Example of a host_request_translation_function body that sets the request path
to a hardcoded value and adds the hardcoded query parameter a=b:
-- Statements go here
print('Setting hardcoded Path and QueryParameters')
return HTTPRequest({
Path = '/content.mpd',
QueryParameters = {
{'a','b'}
}
})
Arguments
The following (iterable) arguments will be known by the function:
QueryParameters
Type: nested
table(indexed by number).Description: Array of query parameters as
{[1]='Name',[2]='Value'}pairs that are present in the query string of the request from the client to the router. Format identical to theHTTPRequest.QueryParameters-field specified for the return value above.Example usage:
for _, queryParam in pairs(QueryParameters) do print(queryParam[1]..'='..queryParam[2]) end
Headers
Type: nested
table(indexed by number).Description: Array of request headers as
{[1]='Name',[2]='Value'}pairs that are present in the request from the client to the router. Format identical to theHTTPRequest.Headers-field specified for the return value above. A multi-value header such asFoo: bar1,bar2is seen inhost_request_translation_functionasHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar1'}, ...}.Example usage:
for _, header in pairs(Headers) do print(header[1]..'='..header[2]) end
Global Tables
The following non-iterable global tables are available for use by the
host_request_translation_function.
Table outgoing_request
The outgoing_request table contains the request that is to be sent to the
host.
outgoing_request.method- Description: HTTP request method.
- Type:
string - Example:
'GET','POST'
outgoing_request.body- Description: HTTP request body string.
- Type:
stringornil - Example:
'{"foo": "bar"}'
outgoing_request.major_version- Description: Major HTTP version such as
xinHTTP/x.1. - Type:
integer - Example:
1
- Description: Major HTTP version such as
outgoing_request.minor_version- Description: Minor HTTP version such as
xinHTTP/1.x. - Type:
integer - Example:
1
- Description: Minor HTTP version such as
outgoing_request.protocol- Description: Transfer protocol variant.
- Type:
string - Example:
'HTTP','HTTPS'
Table outgoing_request_headers
Contains the request headers from the request that is to be sent to the host, keyed by name.
Example:
print(outgoing_request_headers['X-Forwarded-For'])
Multiple values are separated with a comma.
Additional Data
In addition to the arguments above, the following Lua tables, documented in Global Lua Tables, provide additional data that is available when executing the request translation function:
1.1.5.8.5.6 - Response Translation Function
Specifies the body of a Lua function that inspects every outgoing HTTP response and overwrites individual fields before being sent to the client.
Returns nil when nothing is to be changed, or HTTPResponse(t) where t
is a table with any of the following optional fields:
Code- Description: Replaces status code in the response being sent.
- Type:
integer - Example:
200,404
Text- Description: Replaces status text in the response being sent.
- Type:
string - Example:
'OK','Not found'
MajorVersion- Description: Replaces major HTTP version such as
xinHTTP/x.1in the response being sent. - Type:
integer - Example:
1
- Description: Replaces major HTTP version such as
MinorVersion- Description: Replaces minor HTTP version such as
xinHTTP/1.xin the response being sent. - Type:
integer - Example:
1
- Description: Replaces minor HTTP version such as
Protocol- Description: Replaces protocol in the response being sent.
- Type:
string - Example:
'HTTP','HTTPS'
Body- Description: Replaces body in the response being sent.
- Type:
stringornil - Example:
'{"foo": "bar"}'
Headers- Description: Adds, removes or replaces individual headers in the response being sent.
- Type: nested
table(indexed by number) representing an array of response headers as{[1]='Name',[2]='Value'}pairs that are added to the response being sent, or overwriting existing request headers with colliding names. To remove a header from the response, specifynilas value, i.e.Headers={..., {[1]='foo',[2]=nil} ...}. Duplicate names are supported. A multi-value header such asFoo: bar1,bar2is defined by specifyingHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar2'}, ...}.
OutgoingRequest: See Sending HTTP requests from translation functions for more information.
Example of a response_translation_function body that sets the Location
header to a hardcoded value:
-- Statements go here
print('Setting hardcoded Location')
return HTTPResponse({
Headers = {
{'Location', 'cdn1.com/content.mpd?a=b'}
}
})
Arguments
The following (iterable) arguments will be known by the function:
Headers
Type: nested
table(indexed by number).Description: Array of response headers as
{[1]='Name',[2]='Value'}pairs that are present in the response being sent. Format identical to theHTTPResponse.Headers-field specified for the return value above. A multi-value header such asFoo: bar1,bar2is seen inresponse_translation_functionasHeaders={..., {[1]='foo',[2]='bar1'}, {[1]='foo',[2]='bar1'}, ...}.Example usage:
for _, header in pairs(Headers) do print(header[1]..'='..header[2]) end
Additional Data
In addition to the arguments above, the following Lua tables, documented in Global Lua Tables, provide additional data that is available when executing the response translation function:
1.1.5.8.5.7 - Sending HTTP requests from translation functions
It is possible to configure all translation functions to send HTTP requests. If an outgoing request is sent in a translation function, the Director will delay the response to the incoming request until the outgoing request has been completed. Note that the response to the outgoing request is not handled by the Director, it only waits for the outgoing request to complete.
Requests can be sent from any translation function by defining the table
OutgoingRequest in the translation function return value:
{
OutgoingRequest = {
Method = "HEAD",
Protocol = "HTTP",
Host = "example.com",
Port = 8080,
Path = "/example/path",
EncodeURL = true,
QueryParameters = {{"param1", "value1"}, {"param2", "value2"}},
Headers = {{"x-header", "header-value"}, {"Authorization", "Basic dXNlcjpwYXNz"}}
}
}
The following fields for OutgoingRequest are supported:
Method: The HTTP method to use. Defaults toHEAD.Protocol: The protocol to use. Defaults to the protocol of the incoming request.Host: The host to send the request to.Port: The port to send the request to. Defaults to 80 ifProtocolisHTTPand 443 ifProtocolisHTTPS.Path: The path to send the request to. Defaults to/.EncodeURL: A boolean value that determines if the URL should be percent-encoded. Defaults totrue. WARNING: Not encoding the URL is not HTTP compliant and might cause issues with some servers. Use with caution. See RFC 1738 for more information.QueryParameters: A list of query parameters to include in the request. Note that the query parameters are defined as two-element lists in Lua.Headers: A Lua table of headers to include in the request. Note that if the header name contains a dash-, it must be defined as a two-element list as seen in the example above.Body: A string containing the body of the request. If this field is not defined, no body will be included in the request. If it is defined, theContent-Lengthheader, with the length of the body, will be added to the request.
All fields except Host are optional.
Using the example above, the following response translation function
will make the Director can send a GET request to
http://example.com:8080/example/path?param1=value1¶m2=value2 with the
headers x-header: x-value and Authorization: Basic dXNlcjpwYXNz:
return HTTPResponse({
OutgoingRequest = {
Method = "HEAD",
Protocol = "HTTP",
Host = "example.com",
Port = 8080,
Path = "/example/path",
QueryParameters = {{"param1", "value1"}, {"param2", "value2"}},
Headers = {{"x-header", "x-value"}, {"Authorization", "Basic dXNlcjpwYXNz"}}
}
})
Using log level 4, the outgoing request can be seen in the Director logs:
DEBUG orc-re-work-0 AsyncRequestSender: Sending request: url=http://example.com/example/path?param1=value1¶m2=value2
DEBUG orc-re-work-0 CDNManager: OutboundContentConn: example.com:8080: Connecting to target CDN example.com:8080
DEBUG orc-re-work-0 ClientConn: 192.168.103.16/28:60201/https: Sent a Lua request: outstanding-requests=1
DEBUG orc-re-work-0 CDNManager: OutboundContentConn: example.com:8080: Target CDN connection established.
DEBUG orc-re-work-0 CDNManager: OutboundContentConn: example.com:8080: Sending request to target CDN:
GET /example/path?param1=value1¶m2=value2 HTTP/1.0
Authorization: Basic dXNlcjpwYXNz
Host: example.com:8080
x-header: x-value
1.1.5.9 - Trusted proxies
When a request with the header X-Forwarded-For is sent to the router, the
router will check if the client is in the list of trusted proxies. If the client
is not a trusted proxy, the router will drop the connection, returning an empty
reply to the client. If the client is a trusted proxy, the IP address defined
in the X-Forwarded-For will be regarded as the client’s IP address.
The list of trusted proxies can be configured by modifying the configuration
field services.routing.settings.trustedProxies with the IP addresses of
trusted proxies:
$ confcli services.routing.settings.trustedProxies -w
Running wizard for resource 'trustedProxies'
<A list of IP addresses from which the proxy IP address of requests with the X-Forwarded-For header defined are checked. If the IP isn't in this list, the connection is dropped. (default: [])>
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
trustedProxies <A list of IP addresses from which the proxy IP address of requests with the X-Forwarded-For header defined are checked. If the IP isn't in this list, the connection is dropped. (default: [])>: [
trustedProxy (default: ): 1.2.3.4
Add another 'trustedProxy' element to array 'trustedProxies'? [y/N]: n
]
Generated config:
{
"trustedProxies": [
"1.2.3.4"
]
}
Merge and apply the config? [y/n]: y
Note that by configuring 0.0.0.0/0 as a trusted proxy, all proxied requests
will be trusted.
1.1.5.10 - Confd Auto Upgrade Tool
The confd-auto-upgrade tool is a simple utility to automatically migrate the confd
configuration schema between different versions of the Director. Starting with version
1.12.0, it is possible to automatically apply the necessary configuration changes in a
controlled and predictable manner. While this tool is intended to help transition the
configuration format between the different versions, it is not a substitute for proper
backups, and while downgrading to an earlier version, it may not be possible to recover
previously modified or deleted configuration values.
When using the tool, both the “from” and “to” versions must be specified. Internally, the tool will calculate a list of migrations which must be applied to transition between the given versions, and apply them, outputting the final configuration to standard output. The current configuration can either be piped in to the tool via standard input, or supplied as a static file. Providing a “from” version which is later than the “to” version will result in the downgrade migrations being applied in reverse order, effectively downgrading the configuration to the lower version.
For convenience, the tool is deployed to the ACD Nodes automatically at install time as a standard Podman container, however since it is not intended to run as a service, only the image will be present, not a running container.
Performing the Upgrade
In the following example scenario, a system with version 1.10.1 has been upgraded
to 1.14.0. Before upgrading a backup of the configuration was taken and saved to
current_config.json.
Using the image and tag as determined in the above section. Issue the following command:
cat current_config.json | \
podman run -i --rm images.edgeware.tv/acd-confd-migration:1.14.0 \
--in - --from 1.10.1 --to 1.14.0 \
| tee upgraded_config.json
In the above example, the updated configuration is saved to upgraded_config.json.
It is recommended to manually verify the generated configuration, and after
which apply the config to confd by using cat upgraded_config.json | confcli -i.
It is also possible to combine the two commands, by piping the output of the auto-upgrade
tool directly to confcli -i. E.g.
cat current_config.json | podman run ... | tee upgraded_config.json | confcli -i
This will save a backup of the upgraded configuration to upgraded_config.json and
at the same time apply the changes to confd immediately.
Downgrading the Configuration
The steps for downgrading the configuration are exactly the same as for upgrade except for the --from
and --to versions should be swapped. E.g. --from 1.14.0 --to 1.10.1. Keep in mind however,
that during an upgrade some configuration properties may have been deleted or modified, and while
downgrading over those steps, some data loss may occur. In those cases, it may be easier and safer
to simply restore from backup. In most cases where configuration properties are removed during upgrade,
the corresponding downgrade will simply restore the default values of those properties.
1.1.6 - Operations
This guide describes how to perform day-to-day operations of the ACD Router and its associated services, collectively known as the Director.
Component Overview
To effectively operate the Director software, it is important to understand the composition of the various software components and how they are deployed.
Each Director instance functions as an independent system, comprising multiple containerized services. These containers are managed by a standard container runtime and are seamlessly integrated with the host’s operating system to enhance the overall operator experience.
The containers are managed by the Podman container runtime, which operates without additional daemon services running on the host. Unlike Docker, Podman manages each container as a separate process, eliminating the reliance on a shared daemon and mitigating the risk of a single-point-of-failure scenario.
Although several distinct services make up the Director, the primary component is the router. The router is responsible for listening for incoming requests, processing the request, and redirecting the client to the appropriate host, or CDN to deliver the requested content.
Two additional containers are responsible for configuration management. Those are
confd and confd-transformer. The former manages a local database of configuration
metadata and provides a REST API for managing the configuration. The confd-transformer
simply listens for configuration changes from confd and adapts that configuration
to a format suitable for the router to ingest. For additional information about
setting up and using confd see here..
The next two components, the edns-proxy and the convoy-bridge allow the router
to communicate with an EDNS server for EDNS-based routing, and with synchronization
with Convoy respectively. Additional information about the EDNS-Proxy is available
here.. For the Convoy Bridge
service see here..
The remaining containers are useful for metrics, monitoring, and alerting. These
include prometheus and grafana for monitoring and analytics, and alertmanager
for monitoring and alarms.
1.1.6.1 - Services
Each container shipped with the Director is fully-integrated with the systemd
service on the host, enabling easy management using standard systemd commands.
The logs for each container are also full-integrated with journald to simplify
troubleshooting.
In order to integrate the Podman containers with systemd, a common prefix
of acd- has been applied to each service name. For example the router
container is managed by the service acd-router, and the confd container
is managed by the service acd-confd. These same prefixed names apply while
fetching logs via journald. This common prefix aids in grouping the related
services as well as provides simpler filtering for tab-completion.
Starting / Stopping Services
Standard systemd commands should be used to start and stop the services.
systemctl start acd-router- Starts theroutercontainer.systemctl stop acd-router- Stops theroutercontainer.systemctl status acd-router- Displays the status of theroutercontainer.
Due to the limitation of needing the acd- prefix, it provides the ability to
work with all ACD services in a group. For example:
systemctl status 'acd-*'- Display the status of all installed ACD components.systemctl start 'acd-*'- Start all ACD components.
Logging
Each ACD component corresponds to a journal entry with the same unit name, with
the acd- prefix. Standard journald commands can be used to view and manage the
logging.
journalctl -u acd-router- Display the logs for theroutercontainer
Access Log
Refer to Access Logging.
Troubleshooting
Some additional logging may be available in the filesystem, the paths of which can
be determined by executing the ew-sysinfo command. See
Diagnostics. for additional details.
1.1.6.2 - Geographic Databases
To do geographic based routing, the Director uses geographic location databases. The databases need to be on the format provided by MaxMind.
When first installed, the Director comes with example databases. These are only suitable for testing and evaluation, if geographic routing is to be used in production, proper databases need to be obtained from MaxMind.
For the Director to find them, each database needs to have a specific filename. Three databases are supported:
| Type | Filename |
|---|---|
| City and Country | /opt/edgeware/acd/geoip2/GeoIP2-City.mmdb |
| ASN | /opt/edgeware/acd/geoip2/GeoLite2-ASN.mmdb |
| Anonymous IP | /opt/edgeware/acd/geoip2/GeoIP2-Anonymous-IP.mmdb |
When updating the database files, the new file is copied over the old file. After that the Director has to be told to reload it. This is done by typing the following:
podman kill --signal HUP router
1.1.7 - Convoy Bridge
The convoy-bridge is an optional integration service, pre-installed alongside the router which provides two-way communication between the router and a separate Convoy installation.
The convoy-bridge is designed to allow the Convoy account metadata to be available from within the router for such use-cases as inserting the account specific prefixes in the redirect URL and validating per-account internal security tokens. The service works by periodically polling the Convoy server for changes to the configuration, and when detected, the relevant configuration information is pushed to the router.
In addition, the convoy-bridge has the ability to integrate the router with the Convoy analytics service, such that client sessions started by the router are properly collected by Convoy, and are available in the dashboards.
Configuration
The convoy-bridge service is configured using confcli on the router host.
All configuration for the convoy-bridge exists under the path
integration.convoy.bridge.
{
"logLevel": "info",
"accounts": {
"enabled": true,
"dbUrl": "mysql://convoy:eith7jee@convoy:3306",
"dbPollInterval": 60
},
"analytics": {
"enabled": true,
"brokers": ["broker1:9092", "broker2:9092"],
"batchInterval": 10,
"maxBatchSize": 500
},
"otherRouters": [
{
"url": "https://router2:5001",
"apiKey": "key1",
"validateCerts": true
}
]
}
In the above configuration block, there are three main sections. The accounts
section enables fetching account metadata from Convoy towards the router. The
analytics section controls the integration between the router and the Convoy
analytics service. The otherRouters section is used to synchronize additional
router instances. The local router instance will always be implicitly included.
Additional routers listed in this section will be handled by this instance of
the convoy-bridge service.
Logging
The logs are available in the system journal and can be viewed using:
journalctl -u acd-convoy-bridge
1.1.8 - Monitoring
1.1.8.1 - Access logging
Access logging is activated by default and can be enabled/disabled by running
$ confcli services.routing.tuning.general.accessLog true
$ confcli services.routing.tuning.general.accessLog false
Requests are logged in the combined log format and can be found at
/var/log/acd-router/access.log. Additionally, the symbolic link
/opt/edgeware/acd/router/log points to /var/log/acd-router, allowing
the access logs to also be found at /opt/edgeware/acd/router/log/access.log.
Example Output
$ cat /var/log/acd-router/access.log
May 29 07:20:00 router[52236]: ::1 - - [29/May/2023:07:20:00 +0000] "GET /vod/batman.m3u8 HTTP/1.1" 302 0 "-" "curl/7.61.1"
Access Log Rotation
Access logs are rotated and compressed once the access log file reaches a size of 100 MB. By default, 10 rotated logs are stored before being rotated out. These rotation parameters can be reconfigured by editing the lines
size 100M
rotate 10
in /etc/logrotate.d/acd-router-access-log. For more log rotation configuration
possibilites, refer to the
Logrotate documentation.
1.1.8.2 - System troubleshooting
ESB3024 contains the tool ew-sysinfo that gives an overview of how the
system is doing. Simply use the command and the tool will output information
about the system and the installed ESB3024 services.
The output format can be changed using the --format flag, possible values
are human (default) and json, e.g.:
$ ew-sysinfo
system:
os: ['5.4.17-2136.321.4.el8uek.x86_64', 'Oracle Linux Server 8.8']
cpu_cores: 2
cpu_load_average: [0.03, 0.03, 0.0]
memory_usage: 478 MB
memory_load_average: [0.03, 0.03, 0.0]
boot_time: 2023-09-08T08:30:57Z
uptime: 6 days, 3:43:44.640665
processes: 122
open_sockets:
ipv4: 12
ipv6: 18
ip_total: 30
tcp_over_ipv4: 9
tcp_over_ipv6: 16
tcp_total: 25
udp_over_ipv4: 3
udp_over_ipv6: 2
udp_total: 5
total: 145
system_disk (/):
total: 33271 MB
used: 7978 MB (24.00%)
free: 25293 MB
journal_disk (/run/log/journal):
total: 1954 MB
used: 217 MB (11.10%)
free: 1736 MB
vulnerabilities:
meltdown: Mitigation: PTI
spectre_v1: Mitigation: usercopy/swapgs barriers and __user pointer sanitization
spectre_v2: Mitigation: Retpolines, STIBP: disabled, RSB filling, PBRSB-eIBRS: Not affected
processes:
orc-re:
pid: 177199
status: sleeping
cpu_usage_percent: 1.0%
cpu_load_average: 131.11%
memory_usage: 14 MB (0.38%)
num_threads: 10
hints:
get_raw_router_config: cat /opt/edgeware/acd/router/cache/config.json
get_confd_config: cat /opt/edgeware/acd/confd/store/__active
get_router_logs: journalctl -u acd-router
get_edns_proxy_logs: journalctl -u acd-edns-proxy
check_firewall_status: systemctl status firewalld
check_firewall_config: iptables -nvL# For --format=json, it's recommended to pipe the output to a JSON interpreter
# such as jq
$ ew-sysinfo --format=json | jq
{
"system": {
"os": [
"5.4.17-2136.321.4.el8uek.x86_64",
"Oracle Linux Server 8.8"
],
"cpu_cores": 2,
"cpu_load_average": [
0.01,
0.0,
0.0
],
"memory_usage": "479 MB",
"memory_load_average": [
0.01,
0.0,
0.0
],
"boot_time": "2023-09-08 08:30:57",
"uptime": "6 days, 5:12:24.617114",
"processes": 123,
"open_sockets": {
"ipv4": 13,
"ipv6": 18,
"ip_total": 31,
"tcp_over_ipv4": 10,
"tcp_over_ipv6": 16,
"tcp_total": 26,
"udp_over_ipv4": 3,
"udp_over_ipv6": 2,
"udp_total": 5,
"total": 146
}
},
"system_disk (/)": {
"total": "33271 MB",
"used": "7977 MB (24.00%)",
"free": "25293 MB"
},
"journal_disk (/run/log/journal)": {
"total": "1954 MB",
"used": "225 MB (11.50%)",
"free": "1728 MB"
},
"vulnerabilities": {
"meltdown": "Mitigation: PTI",
"spectre_v1": "Mitigation: usercopy/swapgs barriers and __user pointer sanitization",
"spectre_v2": "Mitigation: Retpolines, STIBP: disabled, RSB filling, PBRSB-eIBRS: Not affected"
},
"processes": {
"orc-re": {
"pid": 177199,
"status": "sleeping",
"cpu_usage_percent": "0.0%",
"cpu_load_average": "137.63%",
"memory_usage": "14 MB (0.38%)",
"num_threads": 10
}
}
}Note that your system might have different monitored processes and field names.
The field hints is different from the rest. It lists common commands
that can be used to further monitor system performance, useful for
quickly troubleshooting a faulty system.
1.1.8.3 - Scraping data with Prometheus
Prometheus is a third-party data scraper which is installed as a containerized service in the default installation of ESB3024 Router. It periodically reads metrics data from different services, such as acd-router, aggregates it and makes it available to other services that visualize the data. Those services include Grafana and Alertmanager.
The Prometheus configuration file can be found on the host at
/opt/edgeware/acd/prometheus/prometheus.yaml.
Accessing Prometheus
Prometheus has a web interface that is listening for HTTP connections on port 9090. There is no authentication, so anyone who has access to the host that is running Prometheus can access the interface.
Starting / Stopping Prometheus
After the service is configured, it can be managed via systemd, under the
service unit acd-prometheus.
systemctl start acd-prometheus
Logging
The container logs are automatically published to the system journal, under
the same unit descriptor, and can be viewed using journalctl
journalctl -u acd-prometheus
1.1.8.4 - Visualizing data with Grafana
1.1.8.4.1 - Managing Grafana
Grafana displays graphs based on data from Prometheus. A default deployment of Grafana is running in a container alongside ESB3024 Router.
Grafana’s configuration and runtime files are stored under
/opt/edgeware/acd/grafana. It comes with default dashboards that are
documented at Grafana dashboards.
Accessing Grafana
Grafana’s web interface is listening for HTTP connections on port
3000. It has two default accounts, edgeware and admin.
The edgeware account can only view graphs, while the admin account can also
edit graphs. The accounts with default passwords are shown in the table below.
| Account | Default password |
|---|---|
edgeware | edgeware |
admin | edgeware |
Starting / Stopping Grafana
Grafana can be managed via systemd, under the service unit acd-grafana.
systemctl start acd-grafana
Logging
The container logs are automatically published to the system journal, under
the same unit descriptor, and can be viewed using journalctl
journalctl -u acd-grafana
1.1.8.4.2 - Grafana Dashboards
Grafana will be populated with pre-configured graphs which present some metrics on a time scale. Below is a comprehensive list of those dashboards, along with short descriptions.
Router Monitoring dashboard
This dashboard is by default set as home directory - it’s what user will see
after logging in.
Number Of Initial Routing Decisions
HTTP Status Codes
Total number of responses sent back to incoming requests, shown by their status codes. Metric: client-response-status
Incoming HTTP and HTTPS Requests
Total number of incoming requests that were deemed valid, divided into SSL
and Unencrypted categories.
Metric: num_valid_http_requests
Debugging Information dashboard
Number of Lua Exceptions
Number of exceptions encountered so far while evaluating Lua rules. Metric: lua_num_errors
Number of Lua Contexts
Number of active Lua interpreters, both running and idle. Metric: lua_num_evaluators
Time Spent In Lua
Number of microseconds the Lua interpreters were running. Metric: lua_time_spent
Router Latencies
Histogram-like graph showing how many responses were sent within the given latency interval. Metric: orc_latency_bucket
Internal debugging
A folder that contains dashboards intended for internal use.
ACD: Incoming Internet Connections dashboard
SSL Warnings
Rate of warnings logged during TLS connections Metric: num_ssl_warnings_total
SSL Errors
Rate of errors logged during TLS connections Metric: num_ssl_errors_total
Valid Internet HTTPS Requests
Rate of incoming requests that were deemed valid, HTTPS only. Metric: num_valid_http_requests
Invalid Internet HTTPS Requests
Rate of incoming requests that were deemed invalid, HTTPS only. Metric: num_invalid_http_requests
Valid Internet HTTP Requests
Rate of incoming requests that were deemed valid, HTTP only. Metric: num_valid_http_requests
Invalid Internet HTTP Requests
Rate of incoming requests that were deemed invalid, HTTP only. Metric: num_invalid_http_requests
Prometheus: ACD dashboard
Logged Warnings
Rate of logged warnings since the router has started, divided into CDN-related and CDN-unrelated. Metric: num_log_warnings_total
Logged Errors
Rate of logged errors since the router has started. Metric: num_log_errors_total
HTTP Requests
Rate of responses sent to incoming connections. Metric: orc_latency_count
Number Of Active Sessions
Number of sessions opened on router that are still active. Metric: num_sessions
Total Number Of Sessions
Total number of sessions opened on router. Metric: num_sessions
Session Type Counts (Non-Stacked)
Number of active sessions divided by type; see metric documentation linked below for up-to-date list of types. Metric: num_sessions
Prometheus/ACD: Subrunners
Client Connections
Number of currently open client connections per subrunner. Metric: subrunner_client_conns
Asynchronous Queues (Current)
Number of queued events per subrunner, roughly corresponding to load. Metric: subrunner_async_queue
Used <Send/receive> Data Blocks
Number of send or receive data blocks currently in use per subrunner, as decided by the “Send/receive” drop down box. Metric: subrunner_used_send_data_blocks and subrunner_used_receive_data_blocks
Asynchronous Queues (Max)
Maximum number of events waiting in queue. Metric: subrunner_max_async_queue
Total <Send/receive> Data Blocks
Number of send or receive data blocks allocated per subrunner, as decided by the “Send/receive” drop down box. Metric: subrunner_total_send_data_blocks and subrunner_total_receive_data_blocks
Low Queue (Current)
Number of low priority events queued per subrunner. Metric: subrunner_low_queue
Medium Queue (Current)
Number of medium priority events queued per subrunner. Metric: subrunner_medium_queue
High Queue (Current)
Number of high priority events queued per subrunner. Metric: subrunner_high_queue
Low Queue (Max)
Maximum number of events waiting in low priority queue. Metric: subrunner_max_low_queue
Medium Queue (Max)
Maximum number of events waiting in medium priority queue. Metric: subrunner_max_medium_queue
High Queue (Max)
Maximum number of events waiting in high priority queue. Metric: subrunner_max_high_queue
Wakeups
The number of times a subrunner has been waken up from sleep. Metric: subrunner_io_wakeups
Overloaded
The number of times the number of queued events for a subrunner exceeded its maximum. Metric: subrunner_times_worker_overloaded
Autopause
Number of sockets that have been automatically paused. This happens when the work manager is under heavy load. Metric: subrunner_io_autopause_sockets
1.1.8.5 - Alarms and Alerting
Alerts are generated by the third-party service Prometheus, which sends them to the Alertmanager service. A default containerized instance of Alertmanager is deployed alongside ESB3024 Router. Out of the box, Alertmanager ships with only a sample configuration file, and will require manual configuration prior to enabling the alerting functionality. Due to the many different possible configurations for how alerts are both detected and where they are pushed, the official Alertmanager documentation should be followed for how to configure the service.
The router ships with Alertmanager 0.25, the documentation
for which can be found at prometheus.io.
The Alertmanager configuration file can be found on the host at
/opt/edgeware/acd/alertmanager/alertmanager.yml.
Accessing Alertmanager
Alertmanager has a web interface that is listening for HTTP connections on port 9093. There is no authentication, so anyone who has access to the host that is running Alertmanager can access the interface.
Starting / Stopping Alertmanager
After the service is configured, it can be managed via systemd, under the
service unit acd-alertmanager.
systemctl start acd-alertmanager
Logging
The container logs are automatically published to the system journal, under
the same unit descriptor, and can be viewed using journalctl
journalctl -u acd-alertmanager
1.1.8.6 - Monitoring multiple routers
By default an instance of Prometheus only monitors the ESB3024 Router that is installed on the same host as where Prometheus is installed. It is possible to make it monitor other router instances and visualize all instances on one Grafana instance.
Configuring of Prometheus
This is configured in the scraping configuration of Prometheus, which is found
in the file /opt/edgeware/acd/prometheus/prometheus.yaml, which typically
looks like this:
global:
scrape_interval: 15s
rule_files:
- recording-rules.yaml
# A scrape configuration for router metrics
scrape_configs:
- job_name: 'router-scraper'
scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets:
- acd-router-1:5001
metrics_path: /m1/v1/metrics
honor_timestamps: true
- job_name: 'edns-proxy-scraper'
scheme: http
static_configs:
- targets:
- acd-router-1:8888
metrics_path: /metrics
honor_timestamps: true
More routers can be added to the scrape configuration by simply adding more
routers under targets in the scraper jobs.
For instance, to monitor acd-router-2 and acd-router-3 along acd-router-1,
the configuration file needs to be modified like this:
global:
scrape_interval: 15s
rule_files:
- recording-rules.yaml
# A scrape configuration for router metrics
scrape_configs:
- job_name: 'router-scraper'
scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets:
- acd-router-1:5001
- acd-router-2:5001
- acd-router-3:5001
metrics_path: /m1/v1/metrics
honor_timestamps: true
- job_name: 'edns-proxy-scraper'
scheme: http
static_configs:
- targets:
- acd-router-1:8888
- acd-router-2:8888
- acd-router-3:8888
metrics_path: /metrics
honor_timestamps: true
After the file has been modified, Prometheus needs to be restarted by typing
systemctl restart acd-prometheus
It is possible to use the same configuration on multiple routers, so that all routers in a deployment can monitor each other.
Selecting Router in Grafana
In the top left corner the Grafana dashboards have a drop-down menu labeled “ACD Router”, which allows to choose which router to monitor.
1.1.8.7 - Routing Rule Evaluation Metrics
ESB3024 Router counts the number of times a node and any of its children is selected in the routing table.
The visit counters can be retrieved with the following end points:
/v1/node_visits
Returns visit counters for each node as a flat list of
host:counterpairs in JSON.Example output:
{ "node1": "1", "node2": "1", "node3": "1", "top": "3" }
/v1/node_visits_graph
Returns a full graph of nodes with their respective visit counters in GraphML.
Example output:
<?xml version="1.0"?> <graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd"> <key id="visits" for="node" attr.name="visits" attr.type="string" /> <graph id="G" edgedefault="directed"> <node id="routing_table"> <data key="visits">5</data> </node> <node id="cdn1"> <data key="visits">1</data> </node> <node id="node1"> <data key="visits">1</data> </node> <node id="cdn2"> <data key="visits">2</data> </node> <node id="node2"> <data key="visits">2</data> </node> <node id="cdn3"> <data key="visits">2</data> </node> <node id="node3"> <data key="visits">2</data> </node> <edge id="e0" source="cdn1" target="node1" /> <edge id="e1" source="routing_table" target="cdn1" /> <edge id="e2" source="cdn2" target="node2" /> <edge id="e3" source="routing_table" target="cdn2" /> <edge id="e4" source="cdn3" target="node3" /> <edge id="e5" source="routing_table" target="cdn3" /> </graph> </graphml>To receive the graph as JSON, specify
Accept:application/jsonin the request headers.Example output:
{ "edges": [ { "source": "cdn1", "target": "node1" }, { "source": "routing_table", "target": "cdn1" }, { "source": "cdn2", "target": "node2" }, { "source": "routing_table", "target": "cdn2" }, { "source": "cdn3", "target": "node3" }, { "source": "routing_table", "target": "cdn3" } ], "nodes": [ { "id": "routing_table", "visits": "5" }, { "id": "cdn1", "visits": "1" }, { "id": "node1", "visits": "1" }, { "id": "cdn2", "visits": "2" }, { "id": "node2", "visits": "2" }, { "id": "cdn3", "visits": "2" }, { "id": "node3", "visits": "2" } ] }
Resetting Visit Counters
A node visit counter with an id not matching any node id of a newly applied
routing table is destroyed.
Reset all counters to zero by momentarily applying a configuration with a
placeholder routing root node, that has unique id and an empty members
list, e.g:
"routing": {
"id": "empty_routing_table",
"members": []
}
… and immediately reapply the desired configuration.
1.1.8.8 - Metrics
ESB3024 Router collects a large number of metrics that can give insight into
it’s condition at runtime. Those metrics are available in
Prometheus’ text-based exposition format
at endpoint :5001/m1/v1/metrics.
Below is the description of these metrics along with their labels.
client_response_status
Number of responses sent back to incoming requests.
- Type: counter
lua_num_errors
Number of errors encountered when evaluating Lua rules.
- Type:
counter
lua_num_evaluators
Number of Lua rules evaluators (active interpreters).
- Type: gauge
lua_time_spent
Time spent by running Lua evaluators, in microseconds.
- Type:
counter
num_configuration_changes
Number of times configuration has been changed since the router has started.
- Type:
counter
num_endpoint_requests
Number of requests redirected per CDN endpoint.
- Type:
counter - Labels:
endpoint- CDN endpoint address.selector- whether the request was counted duringinitialorinstreamselection.
num_invalid_http_requests
Number of client requests that either use wrong method or wrong URL path. Also number of all requests that cannot be parsed as HTTP.
- Type:
counter - Labels:
source- name of internal filter function that classified request as invalid. Probably not of much use outside debugging.type- whether the request was HTTP (Unencrypted) or HTTPS (SSL).
num_log_errors_total
Number of logged errors since the router has started.
- Type:
counter
num_log_warnings_total
Number of logged warnings since the router has started.
- Type:
counter
num_managed_redirects
Number of redirects to the router itself, which allows session management.
- Type:
counter
num_manifests
Number of cached manifests.
- Type:
gauge - Labels:
count- state of manifest in cache, can be eitherlru,evictedortotal.
num_qoe_losses
Number of “lost” QoE decisions per CDN.
- Type:
counter - Labels:
cdn_id- ID of CDN that loose QoE battle.cdn_name- name of CDN that loose QoE battle.selector- whether the decision was taken duringinitialorinstreamselection.
num_qoe_wins
Number of “won” QoE decisions per CDN.
- Type:
counter - Labels:
cdn_id- ID of CDN that won QoE battle.cdn_name- name of CDN that won QoE battle.selector- whether the decision was taken duringinitialorinstreamselection.
num_rejected_requests
Deprecated, should always be at 0.
- Type:
counter - Labels:
selector- whether the request was counted duringinitialorinstreamselection.
num_requests
Total number of requests received by the router.
- Type:
counter - Labels:
selector- whether the request was counted duringinitialorinstreamselection.
num_sessions
Number of sessions opened on router.
- Type:
gauge - Labels:
state- eitheractiveorinactive.type- one of:initial,instream,qoe_on,qoe_off,qoe_agentorsp_agent.
num_ssl_errors_total
Number of all errors logged during TLS connections, both incoming and outgoing.
- Type:
counter
num_ssl_warnings_total
Number of all warnings logged during TLS connections, both incoming and outgoing.
- Type:
counter - Labels:
category- which kind of TLS connection triggered the warning. Can be one of:cdn,content,generic,repeated_sessionor empty.
num_unhandled_requests
Number of requests for which no CDN could be found.
- Type:
counter - Labels:
selector- whether the request was counted duringinitialorinstreamselection.
num_unmanaged_redirects
Number of redirects to “outside” the router - usually to CDN.
- Type:
counter - Labels:
cdn_id- ID of CDN picked for redirection.cdn_name- name of CDN picked for redirection.selector- whether the redirect was result ofinitialorinstreamselection.
num_valid_http_requests
Number of received requests that were not deemed invalid, see
num_invalid_http_requests.
- Type:
counter - Labels:
source- name of internal filter function that classified request as invalid. Probably not of much use outside debugging.type- whether the request was HTTP (Unencrypted) or HTTPS (SSL).
orc_latency_bucket
Total number of responses sorted into “latency buckets” - labels denoting latency interval.
- Type:
counter - Labels:
le- latency bucket that given response falls into.orc_status_code- HTTP status code of given response.
orc_latency_count
Total number of responses.
- Type:
counter - Labels:
tls- whether the response was sent via SSL/TLS connection or not.orc_status_code- HTTP status code of given response.
ssl_certificate_days_remaining
Number of days until a SSL certificate expires.
- Type:
gauge - Labels:
domain- the common name of the domain that the certificate authenticates.not_valid_after- the expiry time of the certificate.not_valid_before- when the certificate starts being valid.usable- if the certificate is usable to the router, see the ssl_certificate_usable_count metric for an explanation.
ssl_certificate_usable_count
Number of usable SSL certificates. A certificate is usable if it is valid and authenticates a domain name that points to the router.
- Type:
gauge
1.1.8.8.1 - Internal Metrics
A subrunner is an internal module of ESB3024 Router which handles routing requests. The subrunner metrics are technical and mainly of interest for AgileTV. These metrics will be briefly described here.
subrunner_async_queue
Number of queued events per subrunner, roughly corresponding to load.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_client_conns
Number of currently open client connections per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_high_queue
Number of high priority events queued per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_io_autopause_sockets
Number of sockets that have been automatically paused. This happens when the work manager is under heavy load.
- Type:
counter - Labels:
subrunner_id- ID of given subrunner.
subrunner_io_send_data_fast_attempts
A fast data path was added that in many cases increases the performance of the router. This metric was added to verify that the fast data path is taken.
- Type:
counter - Labels:
subrunner_id- ID of given subrunner.
subrunner_io_wakeups
The number of times a subrunner has been waken up from sleep.
- Type:
counter - Labels:
subrunner_id- ID of given subrunner.
subrunner_low_queue
Number of low priority events queued per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_max_async_queue
Maximum number of events waiting in queue.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_max_high_queue
Maximum number of events waiting in high priority queue.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_max_low_queue
Maximum number of events waiting in low priority queue.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_max_medium_queue
Maximum number of events waiting in medium priority queue.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_medium_queue
Number of medium priority events queued per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_times_worker_overloaded
Number of times when queued events for given subrunner exceeded
the tuning.overload_threshold value (defaults to 32).
- Type:
counter - Labels:
subrunner_id- ID of given subrunner.
subrunner_total_receive_data_blocks
Number of receive data blocks allocated per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_total_send_data_blocks
Number of send data blocks allocated per subrunner.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_used_receive_data_blocks
Number of receive data blocks currently in use per subrunner. Same as subrunner_total_receive_data_blocks.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
subrunner_used_send_data_blocks
Number of send data blocks currently in use per subrunner. Same as subrunner_total_send_data_blocks.
- Type:
gauge - Labels:
subrunner_id- ID of given subrunner.
1.1.9 - Releases
1.1.9.1 - Release esb3024-1.22.1
Build date
2026-02-05
Release status
Type: production
Compatibility
This release has been tested with the following product versions:
- AgileTV CDN Manager, ESB3027-1.4.1
- Orbit, ESB2001-4.2.2 (see Known limitations below)
- SW-Streamer, ESB3004-2.6.2
- Convoy, ESB3006-3.8.0
- Request Router, ESB3008-3.10.1
- GUI 3.2.9
Breaking changes since release esb3024-1.22.0
- If the system has a lot of entries in the selection input,
services.routing.tuning.general.selectionInputItemLimitneeds to be tweaked, otherwise it will not work after upgrading.
Change log
- NEW: Performance optimizations and improvements
- NEW: Show number of selection input entries in Grafana [ESB3024-1582]
- NEW: Monitor Lua memory usage [ESB3024-1591]
- NEW: Monitor memory and CPU usage [ESB3024-1592]
- NEW: Improved expiration handling of messages read from Kafka [ESB3024-1594]
- FIXED: Selection input item limit does not work [ESB3024-1472]
- FIXED: The Director does not reconnect when a Kafka topic is recreated [ESB3024-1491]
- FIXED: Segmentation fault when connection to Kafka is lost [ESB3024-1523]
- FIXED: SELinux being set to enforced without consent [ESB3024-1586]
- FIXED: Migraton script missing for
integration.guiconfig [ESB3024-1621] - FIXED: Installation fails if firewalld is disabled [ESB3024-1623]
Deprecated functionality
Deprecated since ESB3024-1.18.0:
- Lua function
epochToTimehas been deprecated in favor ofepoch_to_time. - Lua function
timeToEpochhas been deprecated in favor oftime_to_epoch. - The session proxy has been deprecated. Its functionality is replaced by the new “Send HTTP requests from Lua code” function.
System requirements
See the current system requirements in Getting Started.
Known limitations
It is recommended to set
services.routing.tuning.general.overloadThresholdto 128. This is particularly important if the Director will receive messages from Kafka.Sometimes the ACD Confd Transformer does not start correctly after the ACD Director has been upgraded. This can be identified by typing
systemctl status acd-confd-transformer.serviceafter the upgrade is complete. If it shows that the service is not running, it needs to be started manually by typingsystemctl start acd-confd-transformer.service. [ESB3024-1675]When configured to use TLS,
acd-telegraf-metrics-databasemight log the following error message:http: TLS handshake error from <client ip>: client sent an HTTP request to an HTTPS serverwhen receiving metrics from caches even though the Telegraf agents are configured to use TLS. The Telegraf logs on the caches do not show any errors related to this. However, the data is still received over TLS and stored correctly byacd-telegraf-metrics-database. The issue seemingly resolved itself during investigation and is not reproducible. Current hypothesis is a logging bug in Telegraf.The Telegraf metrics agent might not be able to read all relevant network interface data on ESB2001 releases older than 3.6.2. The predictive load balancing function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()for ESB2001 instances until they are updated to 3.6.2 or later.
- The recommended workaround for
1.1.9.2 - Release esb3024-1.22.0
Build date
2025-10-23
Release status
Type: production
Compatibility
This release has been tested with the following product versions:
- AgileTV CDN Manager, ESB3027-1.4.0
- Orbit, ESB2001-4.2.0 (see Known limitations below)
- SW-Streamer, ESB3004-2.6.0
- Convoy, ESB3006-3.6.1
- Request Router, ESB3008-3.8.0
Breaking changes from previous release
- Requires CDN Manager ESB3027-1.4.0
- Does not work with older GUI versions (3.2.8 or older)
- Lua hmac_sha256 function now returns a binary string [ESB3024-1245]
Change log
- NEW: Add support for UTF-8 to configuration [ESB3024-489]
- NEW: Add classifier type for HTTP headers [ESB3024-1177]
- NEW: Make Lua
hmac_sha256function return a binary string [ESB3024-1245] - NEW: Limit which headers are forwarded to a host [ESB3024-1387]
- NEW: Reload GeoIP databases without restarting the router service [ESB3024-1429]
- NEW: [ANSSI-BP-028] System Settings - Network Configuration and Firewalls [ESB3024-1450]
- NEW: [ANSSI-BP-028] System Settings - SELinux [ESB3024-1452]
- NEW: [ANSSI-BP-028] Services - SSH Server [ESB3024-1456]
- NEW: Improved classifiers [ESB3024-1492]
- NEW: Improved Selection Input Rest API [ESB3024-1511]
- FIXED: trustedProxies does not support CIDR [ESB3024-1136]
- FIXED: Some valid configurations are rejected [ESB3024-1191]
- FIXED: Lua
print()does not behave according to the documentation [ESB3024-1248] - FIXED: Session translation function only applies to initial sessions [ESB3024-1379]
- FIXED: It is not possible to change the configuration port [ESB3024-1381]
- FIXED: Invalid metrics endpoint response [ESB3024-1388]
- FIXED: Slow CDN response can prevent manifest from being downloaded [ESB3024-1424]
- FIXED: CORS error in select input handler response [ESB3024-1426]
- FIXED: Expired selection input entries are not always deleted [ESB3024-1485]
- FIXED: The Director blocks when loading messages from Kafka [ESB3024-1490]
Deprecated functionality
Deprecated since ESB3024-1.18.0:
- Lua function
epochToTimehas been deprecated in favor ofepoch_to_time. - Lua function
timeToEpochhas been deprecated in favor oftime_to_epoch. - The session proxy has been deprecated. Its functionality is replaced by the new “Send HTTP requests from Lua code” function.
System requirements
See the current system requirements in Getting Started.
Known limitations
When configured to use TLS,
acd-telegraf-metrics-databasemight log the following error message:http: TLS handshake error from <client ip>: client sent an HTTP request to an HTTPS serverwhen receiving metrics from caches even though the Telegraf agents are configured to use TLS. The Telegraf logs on the caches do not show any errors related to this. However, the data is still received over TLS and stored correctly byacd-telegraf-metrics-database. The issue seemingly resolved itself during investigation and is not reproducible. Current hypothesis is a logging bug in Telegraf.The Telegraf metrics agent might not be able to read all relevant network interface data on ESB2001 releases older than 3.6.2. The predictive load balancing function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()for ESB2001 instances until they are updated to 3.6.2 or later.
- The recommended workaround for
1.1.9.3 - Release esb3024-1.20.1
Build date
2025-05-14
Release status
Type: production
Compatibility
This release has been tested with the following product versions:
- AgileTV CDN Manager, ESB3027-1.2.0
- Orbit, ESB2001-3.6.3 (see Known limitations below)
- SW-Streamer, ESB3004-1.36.2
- Convoy, ESB3006-3.4.0
- Request Router, ESB3008-3.2.1
Breaking changes from previous release
- There are no breaking changes in this release.
Change log
- NEW: Support any 3xx response from redirecting CDNs [ESB3024-1271]
- NEW: Support blocking of previously used tokens [ESB3024-1277]
- NEW: Set and get selection input over Kafka. The new configuration field
dataStreamsintroduces support to interface with Kafka. [ESB3024-1278] - NEW: Support TTL in selection input over Kafka [ESB3024-1286]
- NEW: Add option to disable URL encoding on outgoing requests from Lua [ESB3024-1306]
- NEW: Add Lua function for populating metrics [ESB3024-1334]
- FIXED: Improve selection input performance [ESB3024-1290]
- FIXED: Wildcard certificates wrongly documented as being unsupported [ESB3024-1324]
- FIXED: Selection input items with empty keys are not rejected [ESB3024-1328]
- FIXED: IP addresses wrongly classified as anonymous [ESB3024-1331]
- FIXED: Some selection input payloads are erroneously rejected [ESB3024-1344]
Deprecated functionality
- Lua function
epochToTimehas been deprecated in favor ofepoch_to_time. - Lua function
timeToEpochhas been deprecated in favor oftime_to_epoch. - The session proxy has been deprecated. Its functionality is replaced by the new “Send HTTP requests from Lua code” function.
System requirements
- The ACD Router requires a minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
When configured to use TLS,
acd-telegraf-metrics-databasemight log the following error message:http: TLS handshake error from <client ip>: client sent an HTTP request to an HTTPS serverwhen receiving metrics from caches even though the Telegraf agents are configured to use TLS. The Telegraf logs on the caches do not show any errors related to this. However, the data is still received over TLS and stored correctly byacd-telegraf-metrics-database. The issue seemingly resolved itself during investigation and is not reproducible. Current hypothesis is a logging bug in Telegraf.The Telegraf metrics agent might not be able to read all relevant network interface data on ESB2001 releases older than 3.6.2. The predictive load balancing function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()for ESB2001 instances until they are updated to 3.6.2 or later.
- The recommended workaround for
1.1.9.4 - Release esb3024-1.18.0
Build date
2025-02-13
Release status
Type: production
Compatibility
This release is compatible with the following product versions:
- Orbit, ESB2001-3.6.2 (see Known limitations below)
- SW-Streamer, ESB3004-1.36.2
- Convoy, ESB3006-3.4.0
- Request Router, ESB3008-3.2.1
Breaking changes from previous release
- Configurations with an invalid entrypoint will be rejected.
Change log
- NEW: Support configuration feedback. concli provides very basic feedback [ESB3024-1165]
- NEW: Send HTTP requests from Lua code [ESB3024-1172]
- NEW: Add
acd-metrics-aggregatorservice [ESB3024-1221] - NEW: Add
acd-telegraf-metrics-databaseservice [ESB3024-1224] - NEW: Make all Lua functions snake_case.
timeToEpochandepochToTimehave been deprecated. [ESB3024-1246] - FIXED: Content popularity parameters can’t be configured [ESB3024-1187]
- FIXED:
acd-edns-proxyreturns CNAME records in brackets. Hostnames were erroneously interpreted as IPv6 addresses. [ESB3024-1276]
Deprecations from previous release
- Lua function
epochToTimehas been deprecated in favor ofepoch_to_time. - Lua function
timeToEpochhas been deprecated in favor oftime_to_epoch. - The session proxy has been deprecated. Its functionality is replaced by the new “Send HTTP requests from Lua code” function.
System requirements
- The ACD Router requires a minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
GUI version 3.0.2 or earlier will not work with this release.
When configured to use TLS,
acd-telegraf-metrics-databasemight log the following error message:http: TLS handshake error from <client ip>: client sent an HTTP request to an HTTPS serverwhen receiving metrics from caches even though the Telegraf agents are configured to use TLS. The Telegraf logs on the caches do not show any errors related to this. However, the data is still received over TLS and stored correctly byacd-telegraf-metrics-database. The issue seemingly resolved itself during investigation and is not reproducible. Current hypothesis is a logging bug in Telegraf.The Telegraf metrics agent might not be able to read all relevant network interface data on ESB2001 releases older than 3.6.2. The predictive load balancing function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()for ESB2001 instances until they are updated to 3.6.2 or later.
- The recommended workaround for
1.1.9.5 - Release esb3024-1.16.0
Build date
2024-12-04
Release status
Type: production
Compatibility
This release is compatible with the following product versions:
- Orbit, ESB2001-3.6.0 (see Known limitations below)
- SW-Streamer, ESB3004-1.36.0
- Convoy, ESB3006-3.4.0
- Request Router, ESB3008-3.2.1
Breaking changes from previous release
- Access logs are now saved to disk at
/var/log/acd-router/access.loginstead of being handled byjournald.
Change log
- NEW: Collect metrics per account [ESB3024-911]
- NEW: Strip whitespace from beginning and end of names in configuration [ESB3024-954]
- NEW: Improved reselection logging [ESB3024-1089]
- NEW: Access log to file instead of journald. Access logs can now be found in
/var/log/acd-router/access.log[ESB3024-1164] - NEW: Additional Lua checksum functions [ESB3024-1229]
- NEW: Symlink logging directory
/var/log/acd-routerto/opt/edgeware/acd/router/log[ESB3024-1232] - FIXED: Convoy Bridge retries errors too fast [ESB3024-1120]
- FIXED: Memory safety issue. Certain circumstances could cause the director to crash [ESB3024-1123]
- FIXED: Too high severity on some log messages [ESB3024-1171]
- FIXED: Session Proxy sends lowercase header names, which are not supported by Agile Cache [ESB3024-1183]
- FIXED: Translation functions
hostRequestandrequestfail when used together [ESB3024-1184] - FIXED: Lua hashing functions do not accept binary data [ESB3024-1196]
- FIXED: Session Proxy has poor throughput [ESB3024-1197]
- FIXED: Configuration doesn’t handle nested Lua tables as argument to conditions [ESB3024-1218]
Deprecations from previous release
- None
System requirements
- The ACD Router requires a minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
- The Telegraf metrics agent might not be able to read all relevant network
interface data on ESB2001 releases older than 3.6.0. The predictive load balancing
function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()until the issue is resolved on ESB2001.
- The recommended workaround for
1.1.9.6 - Release esb3024-1.14.2
Build date
2024-10-01
Release status
Type: production
Breaking changes
- If upgrading from a release prior to 1.10.0, the Director needs to be upgraded to 1.10.0, 1.10.1 or 1.10.2 before installing 1.14.2. See Installing a 1.14 release for more information.
- In esb3024-1.14.0, the configuration setting
services.routing.settings.allowedProxieshas been renamed toservices.routing.settings.trustedProxiesand has changed default behavior. If empty, proxy connections are now denied by default. See Trusted proxies for more information. - Starting with esb3024-1.14.0, a minimum CPU architecture level of x86-64-v2 is required. See system requirements below for more information.
Change log
- NEW: Define
custom_capacity_varas a number inhost_has_bw_custom(). Using a selection input variable forcustom_capacity_varis no longer necessary. [ESB3024-1119] - FIXED: Predictive load balancing functions do not handle missing interface [ESB3024-1100]
- FIXED: Client closing socket can cause proxy IP to resolve to “?” [ESB3024-1139]
- FIXED: ACD crashes when attempting to read corrupt cached data. The cached data can become corrupt if the filesystem is manipulated by a user or the system runs out of storage. [ESB3024-1147]
- FIXED: Subnets are not being persisted to disk [ESB3024-1149]
- FIXED: ACD overwrites custom GeoIP MMDB files with the default shipped MMDB files when upgrading [ESB3024-1150]
Deprecations
- From esb3024-1.14.0, the grafana-loki and fluentbit containers have been deprecated and are no longer installed with the system. Previously installed containers may be manually stopped and removed if not used, but they will not be uninstalled automatically.
System Requirements
- Starting with esb3024-1.14.0 the ACD Router now requires a minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known Limitations
- The GUI is not working for this release.
- The Telegraf metrics agent might not be able to read all relevant network
interface data on some releases of ESB2001. The predictive load balancing
function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions.host_has_bw_custom()accepts a numeric argument for the host’s network interface capacity which can be used if the data supplied by the Telegraf metrics agents do not contain this information. - It is not recommended to use
interfaces_online()until the issue is resolved on ESB2001.
- The recommended workaround for
1.1.9.7 - Release esb3024-1.14.0
Build date
2024-09-03
Release status
Type: production
Breaking changes
If upgrading from a release prior to 1.10.0, the Director needs to be upgraded to 1.10.0, 1.10.1 or 1.10.2 before installing 1.14.0. See Installing an 1.14 release for more information.
In esb3024-1.14.0, the configuration setting
services.routing.settings.allowedProxieshas been renamed toservices.routing.settings.trustedProxiesand has changed default behavior. If empty, proxy connections are now denied by default. See Trusted proxies for more information.Starting with esb3024-1.14.0, a minimum CPU architecture level of x86-64-v2 is required. See system requirements below for more information.
Change log
- NEW: Remove grafana-loki and fluentbit containers [ESB3024-774]
- NEW: Extend
num_endpoint_requestsmetric with host ID [ESB3024-975] - NEW: Improved subnets endpoint. See API overview documentation for details. [ESB3024-1018]
- NEW: Support RHEL-9 / OL9 [ESB3024-1022]
- NEW: Support OpenSSL 3 [ESB3024-1025]
- NEW: Changed the router base image to oracle linux 9. See breaking changes [ESB3024-1034]
- NEW: Rename allowedProxies to trustedProxies [ESB3024-1085]
- NEW: Deny proxy connections by default if trustedProxies is empty [ESB3024-1088]
- FIXED: Too long classifier name crashes confd-transformer [ESB3024-949]
- FIXED: Lua condition si() doesn’t handle boolean values [ESB3024-1017]
- FIXED: Classifiers of type stringMatcher and regexMatcher can’t use content query params as source [ESB3024-1032]
- FIXED: ConsistentHashing algorithm is not content aware [ESB3024-1053]
- FIXED: Large configurations fail to apply. The REST API max body size is now configurable. [ESB3024-1056]
- FIXED: Convoy-bridge DB connection failure spams logs [ESB3024-1080]
- FIXED: Convoy-bridge does not send correctly formatted session-id [ESB3024-1081]
- FIXED: Response translation removes message body [ESB3024-1082]
Deprecations
- From esb3024-1.14.0, the grafana-loki and fluentbit containers have been deprecated and are no longer installed with the system. During upgrade these containers may manually be stopped and removed if not used.
System Requirements
- Starting with esb3024-1.14.0 the ACD-Router now requires a minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known Limitations
The GUI is not working for this release.
The Telegraf metrics agent might not be able to read all relevant network interface data on some releases of ESB2001. The predictive load balancing function
host_has_bw()and the health check functioninterfaces_online()might therefore not work as expected.- The recommended workaround for
host_has_bw()is to usehost_has_bw_custom(), documented in Built-in Lua functions. A manual integration of setting a custom selection input variable representing the network interface capacity and using this inhost_has_bw_custom()is necessary. See API Overview for details on using the selection input API. to usehost_has_bw_custom() - The recommended workaround for
interfaces_online()is to not use the function until the issue is resolved.
- The recommended workaround for
1.1.9.8 - Release esb3024-1.12.1
Build date
2024-07-03
Release status
Type: production
Breaking changes
If upgrading from a release prior to 1.10.0, the Director needs to be upgraded to 1.10.0, 1.10.1 or 1.10.2 before installing 1.12.1. See Installing an 1.12 release for more information.
Change log
- NEW: Remove support for EL7 [ESB3024-1046]
- FIXED: Large configuration causes crash [ESB3024-1043]
Known Limitations
The GUI is not working for this release.
1.1.9.9 - Release esb3024-1.12.0
Build date
2024-06-19
Release status
Type: production
Breaking changes
If upgrading from a release prior to 1.10.0, the Director needs to be upgraded to 1.10.0, 1.10.1 or 1.10.2 before installing 1.12.0. See Installing release 1.12.0 for more information.
Change log
- NEW: Move managed session creation to Lua. Creating managed sessions is now handled by using the session translation function. [ESB3024-454]
- NEW: Grafana dashboards to monitor Quality [ESB3024-511]
- NEW: Measure and expose quality scores. A quality score per host and session group is now available when making routing decisions. [ESB3024-512]
- NEW: Add default session classifiers. When resetting the list of classifiers in confd, it is now populated with commonly used classifers. [ESB3024-769]
- NEW: Add configuration migration tool [ESB3024-824]
- NEW: Add new Random classifier [ESB3024-899]
- NEW: Add URL parsing code to Lua library. An URL parser based on https://github.com/golgote/neturl/ with extensions for path splitting and joining [ESB3024-936]
- NEW: Standard library Lua functions now use the same log mechanism as the Director [ESB3024-966]
- NEW: Extend ’num_sessions’ metric to include a label with the selected host [ESB3024-973]
- NEW: Add quality level metrics [ESB3024-974]
- NEW: Add host request translation function [ESB3024-996]
- FIXED: ConsistentHashing Algorithm only supports MD5. MD5, SDBM and Murmur are now supported. [ESB3024-929]
- FIXED: Confd IPv4 validation rejects IPs with /29 netmask [ESB3024-1010]
- FIXED: Stale timestamped selection input not being pruned. Added configurable timestamped selection input timeout limit. [ESB3024-1016]
Known Limitations
The GUI is not working for this release.
1.1.9.10 - Release esb3024-1.10.2
Build date
2024-06-03
Release status
Type: production
Breaking changes
If upgrading from a release prior to 1.10.0, the configuration needs to be manually updated after upgrading to 1.10.2. See Installing release 1.10.x for more information.
Change log
- FIXED: ConsistentHashing rule broken [ESB3024-969]
- FIXED: Increase configuration size limit [ESB3024-983]
Known Limitations
None
1.1.9.11 - Release esb3024-1.10.1
Build date
2024-04-18
Release status
Type: production
Breaking changes
If upgrading from a release prior to 1.10.0, the configuration needs to be manually updated after upgrading to 1.10.1. See Installing release 1.10.x for more information.
Change log
- NEW: Change predictive load balancing functions to use megabits/s [ESB3024-932]
- FIXED: Logic classifier statements can consume all memory [ESB3024-937]
Known Limitations
None
1.1.9.12 - Release esb3024-1.10.0
Build date
2024-04-02
Release status
Type: production
Breaking changes
The configuration needs to be manually updated after upgrading to 1.10.0. See Installing release 1.10.0 for more information.
Change log
- NEW: Use metrics from streamers in routing decisions. Added standard library Lua support to use hardware metrics in routing decisions. Added host health checks in the configuration. [ESB3024-154]
- NEW: Remove unused field “apiKey” from configuration [ESB3024-426]
- NEW: Support integration with Convoy Analytics [ESB3024-694]
- NEW: Support combining classifiers using AND/OR in session groups [ESB3024-776]
- NEW: Enable access logging by default [ESB3024-816]
- NEW: Improved Lua translation function error handling [ESB3024-874]
- NEW: Updated predictive load balancing functions to support hardware metrics [ESB3024-887]
- NEW: Remove apiKey from documentation [ESB3024-927]
- FIXED: Condition with ‘or’ statement sometimes generate faulty Lua [ESB3024-863]
Known Limitations
None
1.1.9.13 - Release esb3024-1.8.0
Build date
2024-02-07
Release status
Type: production
Breaking changes
The configuration needs to be manually updated after upgrading to 1.8.0. See Installing release 1.8.0 for more information.
Change log
- NEW: Remove ESB3026 Account Monitor from installer. [ESB3024-354]
- NEW: Improve selection input endpoint flexibility and security. See API overview documentation for details. [ESB3024-423]
- NEW: Support anonymous geoip rules [ESB3024-699]
- NEW: Add ASN IDs list classifiers to confd [ESB3024-778]
- NEW: Enable content popularity tracking by default. Added option to enable/disable in confd/confcli. [ESB3024-781]
- NEW: Remove dependency on session from security token verification [ESB3024-809]
- FIXED: A lot of JSON output on failed routing. HTTP response no longer contains internal routing information. [ESB3024-523]
- FIXED: Returning Lua table from Lua debug endpoint can crash router. Selection Input values now support floating point values in a Lua context [ESB3024-691]
- FIXED: Floating point selection inputs are truncated to ints when passed to Lua context [ESB3024-710]
- FIXED: Race condition between
RestApiandSession[ESB3024-753] - FIXED: confd/concli doesn’t support “forward_host_header” on hostGroups [ESB3024-761]
- FIXED: Support Lua vector keys in reverse order [ESB3024-780]
Known Limitations
None
1.1.9.14 - Release esb3024-1.6.0
Build date
2023-12-20
Release status
Type: production
Breaking changes
The configuration needs to be manually updated after upgrading to 1.6.0. See configuration changes between 1.4.0 and 1.6.0 for more information.
Change log
- NEW: Remove the
lua_pathsarray from the config . Lua scripts are now added using a REST API on the/v1/lua/endpoint. [ESB3024-204] - NEW: Separate “account-monitor” from installer [ESB3024-238]
- NEW: Consistent hashing based routing . Added support for content distribution control for load balancing and cache partitioning [ESB3024-274]
- NEW: Predictive load balancing . Account for in-transit traffic to prevent cache overload when there is a sudden burst of new sessions. [ESB3024-275]
- NEW: Support Convoy security tokens [ESB3024-386]
- NEW: Expose quality, host and session ID in the session object in Lua context [ESB3024-429]
- NEW: Support upgrade of system python in installer [ESB3024-442]
- NEW: Do not configure selinux and firewalld in installer [ESB3024-493]
- NEW: Convoy Distribution/Account integration [ESB3024-503]
- NEW: Make eDNS server port configurable . The router configuration
hosts.proxy_addresshas been renamed tohosts.proxy_urland now accepts a port that is used when connecting to the proxy. Thecdns.http_portandcdns.https_portconfigurations now configure the port that is used for connecting to the EDNS server, before they configured the port that was used for connecting to the proxy. [ESB3024-509] - NEW: Expand node table in Lua context . New fields are:
node.id,node.visits,host.id,host.recent_selections[ESB3024-630] - FIXED: DNS lookup can fail . DNS lookup can fail when same content requested from both IPv4 and IPv6 clients [ESB3024-427]
- FIXED: Failed DNS requests are not retried . Fixed bug where failed eDNS requests were not retried [ESB3024-504]
- FIXED: Lua functions are not updated when uploaded [ESB3024-544]
- FIXED: Undefined metatable fields evaluate to
falserather thannil[ESB3024-642] - FIXED:
Evaluator::evaluate()doesn’t support different types of its variadic arguments [ESB3024-687] - FIXED: Segfault when accessing REST api with empty path [ESB3024-752]
- FIXED: Container UID/GID may change between versions [ESB3024-755]
1.1.9.15 - Release esb3024-1.4.0
Build date
2023-09-29
Release status
Type: production
Breaking changes
- All configuration is now stored under /opt/edgeware/acd, see [ESB3024-425]. Any configuration that is to be kept needs to be manually migrated.
Typically/opt/edgeware/etc/confd/store/store.jsonneeds to be copied to/opt/edgeware/acd/confd/store/store.json,/opt/edgeware/var/lib/acd-router/cached-acd-router-config.jsonneeds to be copied to/opt/edgeware/acd/router/cache/config.jsonand/opt/edgeware/var/lib/acd-router/cached-router-rest-api-key.jsonneeds to be copied to/opt/edgeware/acd/router/cache/rest-api-key.json. Custom Lua functions need to be migrated from/opt/edgeware/acd/var/lib/custom_luato/opt/edgeware/acd/router/lib/custom_lua. The Prometheus and Grafana configurations also need to be copied if they have been modified.
The following changes were made to the confcli configuration [ESB3024-455]. - The
rulefields inside the routing rule items were renamed toconditionto avoid confusion with theruleslist. This applies to the blocksallow,deny,splitandweighted. - The
popularityThresholdin thecontentPopularityrouting rule was renamed tocontentPopularityCutoff.
Change log
- NEW: 1-Page Status Report . Added command
ew-sysinfothat can be used on any machine with an ESB3024 installation. The command outputs various information about the system and installed services which can be used for monitoring and diagnostics. [ESB3024-391] - NEW: Update routing rule property names . Routing rule property names updated for consistency and clarity [ESB3024-455]
- FIXED: Deleting confd API array element inside oneOf object fails [ESB3024-355]
- FIXED: Container logging not captured by
systemduntil services are restarted [ESB3024-359] - FIXED: Alertmanager restricts the configuration to a single file [ESB3024-381]
- FIXED: Split rules in routing configuration should terminate on error [ESB3024-420]
- FIXED: Improve alert configuration in Prometheus [ESB3024-422]
- FIXED: Inconsistent storage paths of service configuration and data [ESB3024-425]
- FIXED: confd-transformer is not working in el7 [ESB3024-430]
1.1.9.16 - Release acd-router-1.2.3
Build date
2023-08-16
Release status
Type: production
Breaking changes
None
Change log
- NEW: Add more classifiers . New classifiers are
hostName,contentUrlPath,userAgent,contentUrlQueryParameters[ESB3024-298] - NEW: Add allow- and denylist rule blocks [ESB3024-380]
- NEW: Add enhanced validation of scriptable field in routing rules [ESB3024-393]
- NEW: Add
servicesto the config tree [ESB3024-410] - NEW: Prohibit unknown configuration properties [ESB3024-416]
- FIXED: Duplicate session group IDs are allowed [ESB3024-49]
- FIXED: Invalid URL returned for IPv4 requests when using a DNS backend [ESB3024-374]
- FIXED: Not possible to set log level in eDNS proxy [ESB3024-378]
- FIXED: Instream selection fails when DASH manifest has template paths using “../” [ESB3024-384]
1.1.9.17 - Release acd-router-1.2.0
Build date
2023-06-27
Release status
Type: production
Breaking changes
None
Change log
- NEW: Add meta fields to the configuration . The API now allows the meta data fields “created_at”, “source” and “source_checksum” that can be used for the API consumer to track who did what change when.
- NEW: Control routing behavior based on backend response code . This gives control over when to return backend response codes to the end user and when to trigger a failover to another CDN or host.
- NEW: Manage Lua scripts via API
- NEW: Support popularity-based routing . Content can be ordered in multiple groups with descending popularity. Popularity can also be tracked per session group.
- NEW: Improved support for IPv6 routing . It is now possible to select backend depending on the IP protocol version.
- NEW: Add DNS backend support . This allows delegating routing decisions to an EDNS0 server.
- NEW: Support HMAC with SHA256 in Lua scripts
- NEW: Add alarm support . The alarms are handled by Prometheus and Alertmanager.
- NEW: Support saving Grafana Dashboards
- NEW: Add simplified configuration API and CLI tool . A new configuration API with an easier to use model has been added. The “confcli” tool present in many other Edgeware products is now supported.
- NEW: Add authentication to the REST API
- FIXED: Host headers not forwarded to Request Router when ‘redirecting: true’ is enabled
- FIXED: IP range classifier 0.0.0.0/0 does not work in session groups
1.1.9.18 - Release acd-router-1.0.0
Build date
2022-11-22
Release status
Type: First production release
Known Limitations
The setting “allowed_clients” should not be used since the functionality does not work as expected.
Change log
- Flexible routing rule engine with support for Lua plugins. Support many use cases, including CDN Offload and CDN Selection.
- Advanced client classification mechanisms for routing based on group memberships (device type, content type, etc).
- Geobased routing including dedicated high-performing API for subnet matching, associating an incoming request with a region.
- Integration API to feed the service with arbitrary variables to use for routing decisions. Can be used to get streaming bitrate in public CDNs, status from network probes, etc.
- Flexible request/response translation manipulation on the client facing interface. Can be used for URL manipulation, encoding/decoding tokens or adapting the interface to e.g. the PowerDNS backend protocol.
- Metrics API that can be monitored with standard monitoring software. Out-of-the-box integration with Prometheus and Grafana.
- Robust deployment with each service instance running independently, and allowing the service to stay in operational state even when backends become temporarily unavailable.
- RHEL 7/8 support.
- Online documentation at https://docs.agilecontent.com/
1.1.10 - Glossary
- ACD
- Agile CDN Director. See “Director”.
- Confd
- A backend service that hosts the service configuration. Comes with an API, a CLI and a GUI.
- Classifier
- A filter that associate a request with a tag that can be used to define session groups.
- Director
- The Agile Delivery OTT router and related services.
- ESB
- A software bundle that can be separately installed and upgraded, and is released as one entity with one change log. Each ESB is identified with a number. Over time, features and functions within an ESB can change.
- Lua
- A widely available scripting language that is often used to extend the capabilities of a piece of software.
- Router
- Unless otherwise specified, an HTTP router that manages an OTT session using HTTP redirect. There are also ways to use DNS instead of HTTP.
- Selection Input API
- Data posted to this API can be accessed by the routing rules and hence influence the routing decisions.
- Subnet API
- An API to define mappings between subnets and names (typically regions) for those subnets. Routing rules can then refer to the names rather than the subnets.
- Session Group
- A handle on a group of requests, defined via classifiers.
1.2 - AgileTV Account Aggregator (esb3032)
1.2.1 - Getting Started
The account aggregator is a service responsible for monitoring various input streams, compiling and aggregating statistics, and selectively reporting to one or more output streams. It acts primarily as a centralized collector of metrics which may have various aggregations applied before being published to one or more endpoints.
Modes of Operation
There are two primary modes of operation, a live-monitoring mode, as well as a reporting mode. The live-monitoring mode measures the account records in real-time, filters, and aggregates the data to the various outputs in real-time. In this mode, only the most recent data will be considered, and any historical context upon startup may be skipped. In the reporting mode, the account record data will be consumed and processed in the order in which they were published to Kafka, and the service will guarantee that all records, still available within the Kafka topic will be processed and reported upon.
Activating the various modes of operation is performed by way of the set of
input and output blocks within the configuration file. The file may
contain one or more input blocks which specify where the data is sourced,
e.g. account records from Kafka, and one or more output blocks which
determine how and where the aggregated statistics are published.
While it is possible to specify multiple input and output blocks within
a single configuration file, it is highly recommended to separate each pairing
of input and output blocks into separate instances running on different
nodes. This will yield the best performance and provide for better load
balancing, since each instance will be responsible for a single mode of
operation.
Real-Time Account Monitoring
In the real-time account monitoring mode, account records, which are sent from each streaming server through the Kafka message broker, are processed by the account aggregator, and current real-time throughput metrics are updated in a Redis database. These metrics, which are constantly being updated, reflect the most current state of the CDN, and can be used by the Convoy Request Router to make real-time routing decisions.
PCX Reporting
In the PCX collector mode, account records are consumed in such a way that past throughput and session statistics can be aggregated to produce billing related reports. These reports are not considered real-time metrics, but represent usage statistics over fixed time intervals. This mode of operation requires a PCX API compatible reporting endpoint. See Appendix B for additional information regarding the PCX reporting format.
Installation
Prerequisites
The account aggregator is shipped as a compressed OCI formatted container image and as such, it requires a supported container runtime such as one of the following:
- Docker
- Podman
- Kubernetes
Any runtime capable of running a Linux container should work the same. For simplicity, the following installation instructions assume that Docker is being used, and that Docker is already configured and running on the target system.
To test that Docker is setup and running, and that the current user has the required privileges to create a container, you may execute the following command.
$ docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
If you get a permission denied error, ensure that the current user is a member
of the docker group or execute all Docker commands under sudo.
Loading the Container Image
The container image is delivered as a compressed OCI formatted image, which
can be loaded directly via the docker load command. The following assumes
that the image is in /tmp/esb3032-acd-aggregator-0.0.0.gz
docker load --input /tmp/esb3032-acd-aggregator-0.0.0.gz
You will now be able to verify that the image was loaded successfully by executing the following and looking for the image name in the output.
$ docker images | grep acd-aggregator
images.edgeware.tv/esb3032-acd-aggregator latest 4bbe28b444d3 1 day ago 2.08GB
Creating the Configuration File
The configuration file may be located anywhere on the filesystem, however
it is recommended to keep everything under the /opt/edgeware/acd/aggregator
folder to be consistent with other products under the ACD product family.
If that folder doesn’t already exist, you may create the folder with the
following command.
mkdir -p /opt/edgeware/acd/aggregator
If using a different location, you will need to map the folder to the container while creating the Docker container. Additional information describing how to map the volume is available in the section “Creating and starting the container” below.
The configuration file for the account aggregator is divided into several
sections, input, output and tuning. One or more input blocks may
be specified to configure from where the data should be sourced. One or
more output blocks may be configured which determine to where the resulting
aggregated data is published. Finally the tuning block configures various
global settings for how the account aggregator operates, such as the global
log_level.
Configuring the Input Source
As of the current version of the account aggregator, there is only a single
type of input source supported, and that is account_records. This input
source connects to a Kafka message broker, and consumes account records.
Depending on which output types are configured, the Kafka consumer may either
start by processing the oldest or most recent records first.
The following configuration block sample will be used as an example in the description below.
Note that the key input is surrounded by double-square-brackets. This is
a syntax element to indicate that there may be multiple input sections in
the configuration.
[[input]]
type = "account_records"
servers = [
"kafka://192.0.2.1:9092",
"kafka://192.0.2.2:9092",
]
group_name = "acd-aggregator"
kafka_max_poll_interval_ms = 30000
kafka_session_timeout_ms = 3000
log_level = "off"
The type property is used to determine the type of input, and the only
valid value is account_records.
The servers list must contain at least 1 Kafka URL, prefixed with the
URL scheme kafka://. If not specified, the default Kafka port of 9092
will be used. It is recommended but not required to specify all servers
here, as the Kafka client library will obtain the full list of endpoints
from the server on startup, however, the initial connection will be made
to one or more of the provided URLs.
The group_name property identifies to which consumer group the aggregator
should belong. Due to the type of data which account records represent, each
instance of the aggregator connecting to the same Kafka message broker
MUST have a unique group name. If two instances belong to the same group,
the data will be partitioned among both instances, and the resulting
aggregations may not be correct. If only a single instance of the account
aggregator is used, this property is optional and defaults to “acd-aggregator”.
The kafka_* properties, for max_poll_interval and session_timeout are
used to tune the connection parameters for the internal Kafka consumer. More
details for these properties can be found in the documentation for the
rdkafka library. See Kafka documentation
for more details.
The log_level property configures the logging level for the Kafka library
and supports the values “off”, “trace”, “debug”, “info”, “warn”, and “error”.
By default, logging from this library is disabled. This should only be
enabled for troubleshooting purposes, as it is extremely verbose, and any
warnings or error messages will be repeated in the account aggregator’s log.
The logging level for the Kafka library must be higher then the general
logging level for the aggregator, as defined in the “tuning” section or the
lower-level messages from the Kafka library will be skipped.
Configuring Output
The account aggregator currently supports two types of output blocks, depending on the desired mode of operation. For reference purposes, both types will be described within this section, but it is recommended to only use a single type per instance of the account aggregator.
Note that the key output is surrounded by double-square-brackets. This is
a syntax element to indicate that there may be multiple output sections in
the configuration.
[[output]]
type = "account_monitor"
redis_servers = [
"redis://192.0.2.7:6379/0",
"redis://:password@192.0.2.8:6379/1",
]
stale_threshold_s = 12
throughput_correction_mbps = 0
minimum_check_interval_ms = 1000
[[output]]
type = "pcx_collector"
report_url = "https://192.0.2.5:8000/v1/collector"
client_id = "edgeware"
secret = "abc123"
report_timeout_ms = 2000
report_interval_s = 30
report_delay_s = 30
Real-Time Account Monitor Output
The first output block has the type account_monitor and represents the
live account monitoring functionality, which publishes per-account bandwidth
metrics to one or more Redis servers. When this type of output block is
configured, the account records will be consumed starting with the most
recent messages first, and offsets will not be committed. Stopping or
restarting the service may cause account records to be skipped. This type
of output is suitable for making real-time routing decisions, but should
not be relied upon for critical billing or reporting metrics.
The redis_servers list consists of URLs to Redis instances which shall be
updated with the current real-time bandwidth metrics. If the Redis instance
requires authentication, the global instance password can be specified as part
of the URL as in the second entry in the list. Since Redis does not support
usernames, anything before the : in the credentials part of the URL will
be ignored. At least 1 Redis URL must be provided.
The stale_threshold_s property determines the maximum timeout in seconds,
after which, if no account records have been received for a given host,
the host will be considered stale and removed.
The throughput_correction_mbps property can be used to add or subtract a
fixed correction factor to the bandwidth reported in Redis. This is specified
in megabits per second, and this may be either positive or negative. If
the value is negative, and the calculated bandwidth is less than the correction
factor, a minimum bandwidth of 0 will be reported.
The minimum_check_interval_ms property is used to throttle how frequently
the statistics will be processed. By default, the account aggregator will not
recalculate the statistics more than once per second. Setting this value too
low will result in potentially higher CPU usage, while setting it too high may
result in some account records being missed. The default of 1 second should
be adequate for most situations.
PCX Collector Output
The pcx_collector type configures the account aggregator as a reporting
agent for the PCX API. Whenever this configuration is present, the account
record consumer will be configured to always start at the oldest records
retained within the Kafka topic. It then processes the records one at a time,
committing the Kafka offset each time a report is successfully received.
This mode does not make any guarantees as to how recent the data is on which
the reports are made, but does guarantee that every record will be counted
in the aggregated report. Stopping or restarting the service will result in
the account record consumer resuming processing from the last successful
report. This type of reporting is suitable for billing purposes assuming
that there are multiple replicated Kafka nodes, and that the service is not
stopped for longer than the maximum retention period configured within
Kafka. Stopping the service for longer than the retention period will result
in messages being unavailable. Because this type of output requires that
the Kafka consumer is processed in a specific order, and will not proceed
with reading additional messages until all reports have been successfully
received, it is not recommended to have both pcx_collector and the
account_monitor type output blocks configured within the same instance.
The report_url property is a single HTTP endpoint URL where the PCX API
can be reached. This property is required and may be either an HTTP or HTTPS
URL. For HTTPS, the validity of the TLS certificate will be enforced, meaning
that self-signed certificates will not be considered valid.
The client_id and secret fields are used to authenticate the client with
the PCX API via token-based authentication. These fields are both required,
however if not used by the specific PCX API instance, the empty string ""
may be provided.
The report_timeout_ms field is an optional maximum timeout for the HTTP
connection to the PCX API before the connection will fail. Failed reports
will be retried indefinitely.
The report_interval_s property represents the interval bucket size for
reporting metrics. The timing for this type of output is based solely
on the embedded timestamp value of the account records, meaning that this
property is not an absolute period on which the reports will be sent, but
instead represents the duration between the start and ending timestamps of
the report. Especially upon startup, reports may be sent much more frequently
than this interval, but will always cover this duration of time.
The report_delay_s property is an optional offset used to account for both
clock synchronization between servers as well as propagation delay of the
account records through the message broker. The default delay is 30 seconds.
This means that the ending timestamp of a given report will be no more recent
than this many seconds in the past. It is important to include this delay, as
any account records received with a timestamp that would be within period which
has already been reported upon, will be dropped.
Tuning the Account Aggregator
The tuning configuration block represents the global properties for tuning
how the account aggregator functions. Currently only one tuning property
can be configured, and that is the log_level. The default log_level is
“info”, which should be used in normal operation of the account aggregator,
however, other possible values in order of verbosity include “trace”,
“debug”, “info”, “warn”, “error”, and “off”.
Note that the tuning key is surrounded by single square-brackets. This is
TOML syntax meaning that only one instance of tuning is allowed.
[tuning]
log_level = "info"
Example Configurations
This section describes some example configuration files which can be used as a starting template depending on which mode of operation is desired.
Real-Time Account Monitoring Example
This configuration will consume account records from a Kafka server running on 3 hosts, kafka-1, kafka-2, and kafka-3. The account records will be consumed starting with the most recent records. The resulting aggregations will be published to two Redis instances, running on redis-1 and redis-2. The reported bandwidth will have a 2Gb/s correction factor applied.
[[input]]
type = "account_records"
servers = [
"kafka://kafka-1:9092",
"kafka://kafka-2:9092",
"kafka://kafka-3:9092"
]
group_name = "acd-aggregator-live"
# kafka_max_poll_interval_ms = 30000
# kafka_session_timeout_ms = 3000
# log_level = "off"
[[output]]
type = "account_monitor"
redis_servers = [
"redis://redis-1:6379/0",
"redis://redis-2:6379/0",
]
# stale_threshold_s = 12
throughput_correction_mbps = 2000
# minimum_check_interval_ms = 1000
[tuning]
log_level = "info"
The keys prefixed by # are commented out, since the default values will
be used. They are included in the example for completeness.
PCX Collector
This configuration will consume account records starting from the earliest
record, calculate aggregated statistics for every 30 seconds, offset with
a delay of 30 seconds, and publish the results to
https://pcx.example.com/v1/collector.
[[input]]
type = "account_records"
servers = [
"kafka://kafka-1:9092",
"kafka://kafka-2:9092",
"kafka://kafka-3:9092"
]
group_name = "acd-aggregator-pcx"
# kafka_max_poll_interval_ms = 30000
# kafka_session_timeout_ms = 3000
# log_level = "off"
[[output]]
type = "pcx_collector"
report_url = "https://pcx.example.com/v1/collector"
client_id = "edgeware"
secret = "abc123"
# report_timeout_ms = 2000
# report_interval_s = 30
# report_delay_s = 30
[tuning]
log_level = "info"
The keys prefixed by # are commented out, since the default values will
be used. They are included in the example for completeness.
Combined PCX Collector with Real-Time Account Monitoring
While this configuration is possible, it is not recommended, since the
pcx_collector output type will force all records to be consumed starting
at the earliest record. This will cause the live statistics to be delayed
until ALL earlier records have been consumed, and reports have been
successfully accepted by the PCX API. This combined role configuration can be
used to minimize the number of servers or services running if the above
limitations are acceptable.
Note: This is simply the combination of the above two output blocks in the
same configuration file.
[[input]]
type = "account_records"
servers = [
"kafka://kafka-1:9092",
"kafka://kafka-2:9092",
"kafka://kafka-3:9092"
]
group_name = "acd-aggregator-combined"
# kafka_max_poll_interval_ms = 30000
# kafka_session_timeout_ms = 3000
# log_level = "off"
[[output]]
type = "account_monitor"
redis_servers = [
"redis://redis-1:6379/0",
"redis://redis-2:6379/0",
]
# stale_threshold_s = 12
throughput_correction_mbps = 2000
# minimum_check_interval_ms = 1000
[[output]]
type = "pcx_collector"
report_url = "https://pcx.example.com/v1/collector"
client_id = "edgeware"
secret = "abc123"
# report_timeout_ms = 2000
# report_interval_s = 30
# report_delay_s = 30
[tuning]
log_level = "info"
Upgrading
The upgrade procedure for the aggregator consists of simply stopping
the existing container with docker stop acd-aggregator, removing the
existing container with docker rm acd-aggregator, and following the
steps in “Creating and starting the container” below with the upgraded
Docker image.
To roll back to a previous version, simply perform the same steps with the
previous image. It is recommended to keep at least one previous image
around until such time that you are satisfied with the new version. After
which, you may remove the previous image with
docker rmi images.edgeware.tv/esb3032-acd-aggregator:1.2.3 where “1.2.3”
represents the previous version number.
Creating and Starting the Container
Now that the configuration file has been created, and the image has been
loaded, we will need to create and start the container instance. The
following docker run command will create a new container called
“acd-aggregator”, start the process, and automatically resume the container
once the Docker daemon is loaded at startup.
docker run \
--name "acd-aggregator" \
--detach \
--restart=always \
-v <PATH_TO_CONFIG_FOLDER>:/opt/edgeware/acd/aggregator:ro \
<IMAGE NAME>:<VERSION> \
--config /opt/edgeware/acd/aggregator/aggregator.toml
As an example using version 1.4.0:
docker run \
--name "acd-aggregator" \
--detach \
--restart=always \
-v /opt/edgeware/acd/aggregator:/opt/edgeware/acd/aggregator:ro \
images.edgeware.tv/esb3032-acd-aggregator:1.4.0 \
--config /opt/edgeware/acd/aggregator/aggregator.toml
Note: The image tag in the example is “1.4.0”, you will need to replace
that tag with the image tag loaded from the compressed OCI formatted image
file, which can be obtained by running docker images and searching for the
account aggregator image as described in the step “Loading the container image”
above.
If the configuration file saved in the previous step was at a different
location from /opt/edgeware/acd/aggregator/aggregator.toml you will need to
change both the -v option and the --config option in the above
command to represent that location. The -v option mounts the containing
folder from the host system on the left to the corresponding path inside
the container on the right, and the :ro tells Docker that the volume is
mounted read-only. The --config should be the absolute path to the
configuration file from INSIDE the container. For example, if you saved
the configuration file as /host/path/config.toml on the host, and you need
to map that to /container/path/config.toml within the container, the lines
should be -v /host/path:/container/path:ro and
--config /container/path/config.toml respectively.
The --restart=always line tells Docker to automatically restart the
container when the Docker runtime is loaded, and is the equivalent in
systemd to “enabling” the service.
Starting and Stopping the Container
To view the status of the running container, use the docker ps command.
This will give a line of output for the acd-aggregator container if it
is currently running. Appending the -a flag, will list the aggregator
container if is not running as well.
Execute the following:
docker ps -a
You should see a line for the container with the container name “acd-aggregator” along with the current state of the container. If all is OK, you should see the container process running at this point, but it may show as “exited” if there was a problem.
To start and stop the container the docker start acd-aggregator and
docker stop acd-aggregator commands can be used.
Viewing the Logs
By default, Docker will maintain the logs of the individual containers within its own internal logging subsystem, which requires the user to use the command
docker logs
to view them. It is possible however to configure the Docker daemon to send logs to the system journal, however configuring that is beyond the scope of this document. Additional details describing how to do that are described here
[https://docs.docker.com/config/containers/logging/journald/].
To view the complete log for the aggregator the following command can be used.
docker logs acd-aggregator
Supplying the -f flag, can be used to “follow” the log until either the
process terminates or CTRL+C is pressed.
docker logs -f acd-aggregator
Appendix A: Real-time Account Monitoring
Redis Key-Value Pairs
Each account will have a single key-value stored in Redis with the current throughput with any correction factor applied, which will be updated in real-time every time all hosts for the given account have received a new account record. This should be approximately every 10 seconds, but may vary slightly due to processing time.
The keys are structured in the following format:
bandwidth:<account>:value
and the value is reported in bits-per-second.
For example for accounts foo, bar and baz we may see the following:
bandwidth:foo:value = 123456789
bandwidth:bar:value = 234567890
bandwidth:baz:value = 102400
These values represent the most current throughput for each account, and will be updated periodically. A TTL of 48 hours is added to the keys, such that they will be pruned automatically after 48 hours since the last update. This is to prevent stale keys from remaining in Redis indefinitely. This TTL is not configurable by the end user.
Appendix B: PCX Collector Reporting
PCX Reporting Format
The following is an example of the report sent to the PCX HTTP endpoint.
{
timestamp_begin: 1674165540,
timestamp_end: 1674165570,
writer_id: "writer-1",
traffic: [
Traffic {
account_id: "unknown",
num_ongoing_sessions: 0,
bytes_transmitted: 0,
edges: [
Edge {
server: "orbit-1632",
num_ongoing_sessions: 0,
bytes_transmitted: 0,
},
],
},
Traffic {
account_id: "default",
num_ongoing_sessions: 747,
bytes_transmitted: 75326,
edges: [
Edge {
server: "orbit-1632",
num_ongoing_sessions: 747,
bytes_transmitted: 75326,
},
],
},
],
}
The report can be broken down into 3 parts. The outer root section includes
the starting and stopping timestamps, as well as a writer_id field which is
currently unused. For each account a Traffic section contains the
aggregated statistics for that account, as well as a detailed breakdown of
each Edge. An Edge is the portion of traffic for the account streamed
by each server. Within an Edge the num_ongoing_sessions represents the
peak ongoing sessions during the reporting interval, while the
bytes_transmitted represents the total egress bandwidth in bytes over the
entire period. For each outer Traffic section, the num_ongoing_sessions
and bytes_transmitted represent the sum of the corresponding entries in
all Edges.
Data Protection and Consistency
The ACD aggregator works by consuming messages from Kafka. Once a report has successfully been submitted, as determined by a 200 OK HTTP status from the reporting endpoint, the position in the Kafka topic will be committed. This means that if the aggregator process stops and is restarted, reporting will resume from the last successful report, and no data will be lost. There is a limitation to this, however, and that has to do with the data retention time of the messages in Kafka and the TTL value specified in the aggregator configuration. Both default to the same value of 24 hours. This means that if the aggregator process is stopped for more than 24 hours, data loss will result since the source account records will have expired from Kafka before they can be reported on by the aggregator.
Upon startup of the aggregator, all records stored in Kafka will be reported on in the order they are read, starting from either the last successful report or the oldest record currently in Kafka. Reports will be sent each time the timestamp in the current record read from Kafka exceeds the reporting interval meaning a large burst of reports will be sent at startup to cover each interval. Once the aggregator has caught up with the backlog of account records, it will send a single report roughly every 30 seconds (configurable).
It is not recommended to have more than a single account aggregator instance reading from Kafka at a time, as this will result in partial reports being sent to the HTTP endpoint which will require the endpoint to reconstruct the data upon receipt. All redundancy in the account aggregator is handled by the redundancy within Kafka itself. With this in mind, it is important to ensure that there are multiple Kafka instances running and that the aggregator is configured to read from all of them.
1.2.2 - Releases
1.2.2.1 - Release esb3032-0.2.0
Build date
2022-12-21
Release status
Type: devdrop
Change log
- NEW: Use config file instead of command line switches
- NEW: Reports are now aligned with wall-clock time
- NEW: Reporting time no longer contains gaps in coverage
- FIX: Per-account number of sessions only shows largest host
1.2.2.2 - Release esb3032-1.0.0
Build date
2023-02-14
Release status
Type: production
Change log
- NEW: Create user documentation for ACD Aggregator
- NEW: Simplify configuration . Changed from YAML to TOML format.
- NEW: Handle account records arriving late
- FIXED: Aggregator hangs if committing to Kafka delays more than 5 minutes
1.2.2.3 - Release esb3032-1.2.1
Build date
2023-04-24
Release status
Type: production
Breaking changes
No breaking changes
Change log
- NEW: Port Account Monitor functionality for Convoy Request Router
- NEW: Aggregator Performance Improvements
- FIXED: Reports lost when restarting acd-aggregator
1.2.2.4 - Release esb3032-1.4.0
Build date
2023-09-28
Release status
Type: production
Breaking changes
None
Change log
- NEW: Extend aggregator with additional metrics. Per streamer bandwidth and total bandwidth are now updated in Redis. [ESB3032-98]
- FIXED: Not all Redis instances are updated after a failure [ESB3032-99]
- FIXED: Kafka consumer restarts on Partition EOF [ESB3032-100]
1.3 - AgileTV CDN Manager (esb3027)
1.3.1 - Getting Started
Introduction
The ESB3027 AgileTV CDN Manager is a suite of services responsible for coordinating the Content Delivery Network (CDN) operations. It provides essential APIs and features supporting the ESB3024 AgileTV CDN Director. Key capabilities include:
Centralized user management for authentication and authorization Configuration services, APIs, and user interfaces CDN usage monitoring and metrics reporting License-based tracking, monitoring, and billing Core API services Event coordination and synchronization The software can be deployed as either a self-managed cluster or in a public cloud environment such as AWS. Designed as a cloud-native application following CNCF best practices, its deployment varies slightly depending on the environment:
Self-hosted: A lightweight Kubernetes cluster runs on bare-metal or virtual machines within the customer’s network. The application is deployed within this cluster.
Public cloud: The cloud provider manages the cluster infrastructure, with the application deploying into it. The differences are primarily operational; the software’s functionality remains consistent across environments, with distinctions clearly noted in this guide.
Since deployment relies on Kubernetes, familiarity with key tools is essential:
helm: The package manager for Kubernetes, used for installing, upgrading, rolling back, and removing application charts. Helm charts are collections of templates and default values that generate Kubernetes manifests for deployment.
kubectl: The primary command-line tool for managing Kubernetes resources and applications. In a self-hosted setup, it’s typically used from the control plane nodes; in cloud environments, it may be run locally, often from your laptop or desktop.
Cloud provider tools: In cloud environments, familiarity with CLI tools like awscli and the WebUI is also required for managing infrastructure.
Architectural Overview
See the Architecture Guide.
Installation Overview
The installation process for the manager varies depending on the environment.
Self-hosted: Begin by deploying a lightweight Kubernetes cluster. The installation ISO includes an installer for a simple K3s cluster, a Rancher Labs Kubernetes distribution.
Public cloud: Use your cloud provider’s tooling to deploy the cluster. Specific instructions are beyond this document’s scope, as they vary by provider.
Once the cluster is operational, the remaining steps are the same: deploy the manager software using Helm.
The following sections provide an overview based on your environment. For detailed instructions, refer to the Installation Guide.
Hardware Requirements
In a Kubernetes cluster, each node has a fixed amount of resources—such as CPU, memory, and free disk space. Pods are assigned to nodes based on resource availability. The control plane uses a best-effort approach to schedule pods on nodes with the lowest overall utilization.
Kubernetes manifests for each deployment specify both resource requests and limits for each pod. A node must have at least the requested resources available to schedule a pod there. Since each replica of a deployment requires the same resource requests, the total resource consumption depends on the number of replicas, which is configurable.
Additionally, a Horizontal Pod Autoscaler can automatically adjust the number of replicas based on resource utilization, within defined minimum and maximum bounds.
Because of this, the hardware requirements for deploying the software depend heavily on expected load, configuration, and cluster size. Nonetheless, there are some general recommendations for hardware selection.
See the System Requirements Guide for details about the recommended hardware, supported operating systems, and networking requirements.
Installation Guide
The installation instructions can be found in the Installation Guide.
Configuration Reference
A detailed look at the configuration can be found in the Configuration Reference Guide.
1.3.2 - System Requirements Guide
Cluster Sizing
The ESB3027 AgileTV CDN Manager requires a minimum of three machines for production deployment. While it’s possible to run the software on a single node in a lab environment, such an setup will not offer optimal performance or high availability.
A typical cluster comprises nodes assigned to either a Server or Agent role. Server nodes are responsible for running the control plane software, which manages the cluster, and they can also host application workloads if configured accordingly. Agent nodes, on the other hand, execute the application containers (workloads) but do not participate in the control plane or quorum. They serve to scale capacity as needed. See the Installation Guide for more information about the role types and responsibilities.
For high availability, it is essential to have an odd number of Server nodes. The minimum recommended is three, which allows the cluster to tolerate the loss of one server node. Increasing the Server nodes to five enhances resilience, enabling the cluster to withstand the loss of two server nodes. The critical factor is that more than half of the Server nodes are available; this quorum ensures the cluster remains operational. The loss of Agent nodes does not impact quorum, though workloads on failed nodes are automatically migrated if there is sufficient capacity.
Hardware Requirements
Single-Node Lab Cluster (Acceptance Testing)
For customer acceptance testing in a single-node lab environment, the following hardware is required. These requirements match the Lab Install Guide and are intended for non-production, single-node clusters only:
| CPU | Memory | Disk | |
|---|---|---|---|
| Minimum | 8 Cores | 16GB | 128GB |
| Recommended | 12 Cores | 24GB | 128GB |
- Disk space should be available in the
/varpartition
Note: These requirements are for lab/acceptance testing only. For production workloads, see below.
Production Cluster (3 or More Nodes)
The following tables outline the minimum and recommended hardware specifications for different node
roles within a production cluster. All disk space values refer to the available space on the
/var/lib/longhorn partition. Additional capacity may be needed in other locations not specified
here; it is advisable to follow the operating system vendor’s recommendations for those areas. For
optimal performance, it is recommended to use SSDs or similar high-speed disks for Longhorn storage.
Both virtual machines and bare-metal hardware are supported; however, hosting multiple nodes under a
single hypervisor can impact performance.
Server Role - Control Plane only
| CPU | Memory | Disk | |
|---|---|---|---|
| Minimum | 4 Cores | 8GB | 64GB |
| Recommended | 8 Cores | 16GB | 128GB |
- Disk space should be available in the
/varpartition
Agent Role
| CPU | Memory | Disk | |
|---|---|---|---|
| Minimum | 8 Cores | 16GB | 128GB |
| Recommended | 16 Cores | 32GB | 256GB |
- Disk space should be available in the
/varpartition
Server Role - Control Plane + Workloads
| CPU | Memory | Disk | |
|---|---|---|---|
| Minimum | 12 Cores | 24GB | 128GB |
| Recommended | 24 Cores | 48GB | 256GB |
- Disk space should be available in the
/varpartition
Operating System Requirements
| Operating System | Supported |
|---|---|
| RedHat 7 | No |
| RedHat 8 | Yes |
| RedHat 9 | Yes |
| RedHat 10 | Untested |
We currently support RedHat Enterprise Linux or any compatible clone such as Oracle Linux, Alma Linux, etc., as long as the major version is listed as supported in the above table.
SELinux support will be installed if SELinux is “Enforcing” when installing the ESB3027 AgileTV CDN Manager cluster.
Networking Requirements
A minimum of 1 Network Interface Card must be present and configured as the default gateway on the node when the cluster is installed. If the node does not have an interface with the default route, a default route must be configured. See the Installation Guide for details.
1.3.3 - Architecture Guide
Kubernetes Architecture
Kubernetes is an open-source container orchestration platform that simplifies the deployment, management, and scaling of containerized applications. It provides a robust framework to run applications reliably across a cluster of machines by abstracting the complexities of the underlying infrastructure. At its core, Kubernetes manages resources through various objects that define how applications are deployed and maintained.
Nodes are the physical or virtual machines that make up the Kubernetes cluster. Each node runs a container runtime, the kubelet agent, and other necessary components to host and manage containers. The smallest deployable units in Kubernetes are Pods, which typically consist of one or more containers sharing storage, network, and a specified way to run the containers. Containers within Pods are the actual runtime instances of the applications.
To manage the lifecycle of applications, Kubernetes offers different controllers such as Deployments and StatefulSets. Deployments are used for stateless applications, enabling easy rolling updates and scaling. StatefulSets, on the other hand, are designed for stateful applications that require persistent storage and stable network identities, like databases. Kubernetes also uses Services to provide a stable network endpoint that abstracts Pods, facilitating reliable communication within the application or from outside the cluster, often distributing traffic load across multiple Pods.
graph TD
subgraph Cluster
direction TB
Node1["Node"]
Node2["Node"]
end
subgraph "Workloads"
Deployment["Deployment (stateless)"]
StatefulSet["StatefulSet (stateful)"]
Pod1["Pod"]
Pod2["Pod"]
Container1["Container"]
Container2["Container"]
end
subgraph "Networking"
Service["Service"]
end
Node1 -->|Hosts| Pod1
Node2 -->|Hosts| Pod2
Deployment -->|Manages| Pod1
StatefulSet -->|Manages| Pod2
Pod1 -->|Contains| Container1
Pod2 -->|Contains| Container2
Service -->|Provides endpoint to| Pod1
Service -->|Provides endpoint to| Pod2Additional Concepts
Both Deployments and StatefulSets can be scaled by adjusting the number of Pod replicas.
In a Deployment, replicas are considered identical clones of the Pod, and a Service
typically performs load balancing across them. Each replica in a ReplicaSet is assigned
a fixed name, usually following a pattern like <name>-<index>, for example, postgresql-0,
postgresql-1, and so on.
Many applications use a fixed number of replicas set through Helm, which remains constant regardless of system load. Alternatively, for more dynamic scaling, a Horizontal Pod Autoscaler (HPA) can be used to automatically adjust the number of replicas between a defined minimum and maximum based on real-time load metrics. In public cloud environments, a Vertical Pod Autoscaler (VPA) may also be employed to dynamically scale the number of nodes, but since this feature is not supported in self-hosted setups and depends on the specific cloud provider’s implementation, it is less commonly used in on-premises environments.
Architectural Diagram
graph TD
subgraph Cluster
direction TB
PostgreSQL[PostgreSQL Database]
Kafka[kafka-controller Pods]
Redis[Redis Master & Replicas]
VictoriaMetrics[VictoriaMetrics]
Prometheus[Prometheus Server]
Grafana[Grafana Dashboard]
Gateway[Nginx Gateway]
Confd[Confd]
Manager[ACD-Manager]
Frontend[MIB Frontend]
ZITADEL[Zitadel]
Telegraf[Telegraf]
AlertManager[Alertmanager]
end
PostgreSQL -->|Stores data| Manager
Kafka -->|Streams data| Manager
Redis -->|Cache / Message Broker| Manager
VictoriaMetrics -->|Billing data| Grafana
Prometheus -->|Billing data| VictoriaMetrics
Prometheus -->|Monitoring data| Grafana
Manager -->|Metrics & Monitoring| Prometheus
Manager -->|Alerting| AlertManager
Manager -->|User Interface| Frontend
Manager -->|Authentication| ZITADEL
Frontend -->|Authentication| Manager
Confd -->|Config Updates| Manager
Telegraf -->|System Metrics| Prometheus
Gateway -->|Proxies| Director[Director APIs]
style PostgreSQL fill:#f9f,stroke:#333,stroke-width:1px
style Kafka fill:#ccf,stroke:#333,stroke-width:1px
style Redis fill:#cfc,stroke:#333,stroke-width:1px
style VictoriaMetrics fill:#ffc,stroke:#333,stroke-width:1px
style Prometheus fill:#ccf,stroke:#333,stroke-width:1px
style Grafana fill:#f99,stroke:#333,stroke-width:1px
style Gateway fill:#eef,stroke:#333,stroke-width:1px
style Confd fill:#eef,stroke:#333,stroke-width:1px
style Manager fill:#eef,stroke:#333,stroke-width:1px
style Frontend fill:#eef,stroke:#333,stroke-width:1px
style ZITADEL fill:#eef,stroke:#333,stroke-width:1px
style Telegraf fill:#eef,stroke:#333,stroke-width:1px
style AlertManager fill:#eef,stroke:#333,stroke-width:1pxCluster Scaling
Most components, of the cluster can be horizontally scaled, as long as sufficient resources exist in the cluster to support the additional pods. There are a few exceptions however. The Selection Input service, currently does not support scaling as the order in which Kafka records would no longer be maintained among different consumer group members. Services such as PostgreSQL, Prometheus and VictoriaMetrics also do not support scaling at the present time due to the additional configuration requirements. Most if not all of the other services may be scaled, either by explicitly setting the number of replicas in the configuration or in some cases by enabling and configuring the horizontal pod autoscaler.
The Horizontal Pod Autoscaler, monitors the resource utilization of the Pods in a deployment, and based on some configurable metrics, will manage the scaling between a preset minimum and maximum number of replicas. See the Configuration Guide for more information.
Kubernetes automatically selects which node will run the pods based on several factors including, the resource utilization of the nodes, any pod and node affinity rules, selector labels, among other considerations. By default, all nodes with the ability to run workloads of both Server and Agent roles are considered unless specific configuration for node and pod affinity rules have been defined.
Summary
- The
acd-managerinteracts with core components like PostgreSQL, Kafka, and Redis for data storage, messaging, and caching. - It exposes APIs via the API Gateway and integrates with Zitadel for authentication.
- Monitoring and alerting are handled through Prometheus, VictoriaMetrics, Grafana, and Alertmanager.
- Supporting services like Confd facilitate configuration management, while Telegraf collects system metrics.
1.3.4 - Installation Guide
1.3.4.1 - Overview
Introduction
Installing the ESB3027 AgileTV CDN Manager for production requires a minimum of three nodes. More details about node roles and sizing can be found in the System Requirements Guide. Before beginning the installation, select one node as the primary “Server” node. This node will serve as the main installation point. Once additional Server nodes join the cluster, all Server nodes are considered equivalent, and cluster operations can be managed from any of them. The typical process involves installing the primary node as a Server, then adding more Server nodes to expand the cluster, followed by joining Agent nodes as needed to increase capacity.
Air-Gapped Environments
In air-gapped environments—those without direct Internet access—additional considerations are
required. First, on each node, the Operating System’s ISO must be mounted so that dnf can be
used to install essential packages included with the OS. Second, the “Extras” ISO from the
ESB3027 AgileTV CDN Manager must be mounted to provide access to container images for
third-party software that would otherwise be downloaded from public repositories. Details on
mounting this ISO and loading the included images are provided below.
Roles
All nodes in the cluster have one of two roles. Server nodes run the control-plane software necessary to manage the cluster and provide redundancy. Agent nodes do not run the control-plane software; instead, they are responsible for running the Pods that make up the applications. Jobs are distributed among agent nodes to enable horizontal scalability of workloads. However, agent nodes do not contribute to the cluster’s high availability. If an agent node fails, the Pods assigned to that node are automatically moved to another node, provided sufficient resources are available.
Control-plane only Server nodes
Both server nodes and agent nodes run workloads within the cluster. However, a special attribute called the “CriticalAddonsOnly” taint can be applied to server nodes. This taint prevents the node from scheduling workloads that are not part of the control plane. If the hardware allows, it is recommended to apply this taint to server nodes to separate their responsibilities. Doing so helps prevent misbehaving applications from negatively impacting the overall health of the cluster.
graph TD
subgraph Cluster
direction TB
ServerNodes[Server Nodes]
AgentNodes[Agent Nodes]
end
ServerNodes -->|Manage cluster and control plane| ControlPlane
ServerNodes -->|Provide redundancy| Redundancy
AgentNodes -->|Run application Pods| Pods
Pods -->|Handle workload distribution| Workloads
AgentNodes -->|Failover: Pods move if node fails| Pods
ServerNodes -->|Can run Pods unless tainted with CriticalAddonsOnly| PodExecution
Taint[CriticalAddonsOnly Taint] -->|Applied to server nodes to restrict workload| ServerNodesFor high availability, at least three nodes running the control plane are required, along with at least three nodes running workloads. These can be a combination of server and agent roles, provided that the control-plane nodes are sufficient. If a server node has the “CriticalAddonsOnly” taint applied, an additional agent node must be deployed to ensure workloads can run. For example, the cluster could consist of three untainted server nodes, or two untainted servers, one tainted server, and one agent, or three tainted servers and three agents—all while maintaining at least three control-plane nodes and three workload nodes.
The “CriticalAddonsOnly” taint can be applied to server nodes at any time after cluster installation. However, it only affects Pods scheduled in the future. Existing Pods that have already been assigned to a server node will remain there until they are recreated or rescheduled due to an external event.
kubectl taint nodes <node-name> CriticalAddonsOnly=true:NoSchedule
Where node-name is the hostname of the node for which to apply the taint. Multiple node names
may be specified in the same command. This command should only be run from one of the server nodes.
Next Steps
Continue reading the Installation Requirements.
1.3.4.2 - Requirements
SELinux
SELinux is fully supported provided it is enabled and set to “Enforcing” mode at the time of the initial cluster installation on all nodes. This is the default configuration for Red Hat Enterprise Linux and its derivatives, such as Oracle Linux and AlmaLinux. If the mode is set to “Enforcing” prior to install time, the necessary SELinux packages will be installed, and the cluster will be started with support for SELinux. For these reasons, enabling SELinux after the initial cluster installation is not supported.
Firewalld
Please see the Networking Guide for the current firewall recommendations.
Hardware
Refer to the System Requirements Guide for the current hardware, operating system, and network requirements.
Networking
A minimum of one network interface card must be present and configured as the default gateway on the node when the cluster is installed. If the node does not have an interface with the default route, a default route must be configured. Even a black-hole route via a dummy interface will suffice. The K3s software requires a default route in order to auto-detect the node’s primary IP, and for cluster routing to function properly. To add a dummy route do the following:
ip link add dummy0 type dummy
ip link set dummy0 up
ip addr add 203.0.113.254/31 dev dummy0
ip route add default via 203.0.113.255 dev dummy0 metric 1000
Special Considerations when using Multiple Network Interfaces
If there are special network considerations, such as using a non-default interface for
cluster communication, that must be configured using the INSTALL_K3S_EXEC environment
variable as below before installing the cluster or joining nodes.
As an example, consider the case where the node contains two interfaces, bond0 and
bond1, where the default route exists through bond0, but where bond1 should be used
for cluster communication. In that case, ensure that the INSTALL_K3S_EXEC environment
variable is set as follows in the environment prior to installing or joining the cluster.
Assuming that bond1 has the local IP address 10.0.0.10:
export INSTALL_K3S_EXEC="<MODE> --node-ip 10.0.0.10 --flannel-iface=bond1"
Where MODE should be one of server or agent depending on the role of the node. The
initial node used to create the cluster MUST be server, and additional nodes vary
depending on the role.
DNS and Hostname Resolution
Kubernetes clusters use internal DNS to allow services and pods to communicate using predictable hostnames. Each service is assigned a DNS name in the format:
<service>.<namespace>.svc.cluster.local
These names are automatically resolvable from within the cluster using the
coredns service, which is deployed by default with K3s. This means that any
pod or service can refer to another by its internal DNS name without needing to
know its IP address.
For DNS queries outside the cluster.local domain (for example, public
internet hostnames or your organization’s internal DNS), coredns forwards
requests to an upstream nameserver. By default, this is set to Google’s public
DNS servers (8.8.8.8 and 8.8.4.4).
However, if the primary installation node has custom nameservers configured in
/etc/resolv.conf, K3s will automatically configure coredns to use those as
the upstream resolvers instead. This allows the cluster to integrate with your
local or corporate DNS infrastructure if needed.
Note for multi-datacenter deployments: If your cluster spans multiple datacenters and each datacenter uses different DNS servers, the cluster will be configured to forward DNS requests to the servers specified in
/etc/resolv.confon the node where the installation was performed. If nodes in other datacenters cannot reach those DNS servers (for example, if the servers are only routable within one datacenter), you must use thehostAliasesmechanism (as described for air-gapped environments) to ensure proper DNS resolution for required services across all nodes.
Note for air-gapped environments: In air-gapped clusters, or any environment where no upstream DNS servers are available or configurable, external DNS queries will not resolve. In these cases, you can override DNS names for required services directly in the configuration using host overrides. This allows the cluster to function without external DNS resolution.
Example: To override hostnames in an air-gapped environment, add a
hostAliasessection to yourvalues.yamlconfiguration.
manager:
hostAliases:
- ip: "192.0.2.10"
hostnames:
- acd-manager
- acd-manager.example.local
- ip: "192.0.2.11"
hostnames:
- acd-manager-alt
- acd-manager-alt.example.local
Next Steps
Continue reading the Installation Guide.
1.3.4.3 - Quick Start Guide
Lab Install Guide
This section describes a simplified installation process for customer acceptance testing in a single-node lab environment. Unlike the production Quick Start Guide (which assumes 3 or more nodes), the Lab Install Guide is intended for customers to perform acceptance testing prior to installing a production environment.
System Requirements:
- RHEL 8 or 9 (or equivalent) with at least a minimal installation
- 8-core CPU
- 16 GB RAM
- 128 GB available disk space in the
/varpartition
Step 1: Mount the ISO
mkdir -p /mnt/esb3027
mount -o loop,ro esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Step 2: Install the Base Cluster Software
/mnt/esb3027/install
Step 3: (Air-gapped only) Mount the Extras ISO and Load Images
mkdir -p /mnt/esb3027-extras
mount -o loop,ro esb3027-acd-manager-extras-X.Y.Z.iso /mnt/esb3027-extras
/mnt/esb3027-extras/load-images
Step 4: Deploy the Cluster Helm Chart
helm install --wait --timeout 10m acd-cluster /mnt/esb3027/helm/charts/acd-cluster
Step 5: Deploy the Manager Helm Chart
helm install acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m
Step 6: Next Steps
See the Post Install Guide for post-installation steps and recommendations.
You can now access the manager and begin acceptance testing. For full configuration details, see the full Installation Guide.
Quick Start Guide
This section provides a concise, step-by-step summary for installing the ESB3027 AgileTV CDN Manager cluster in a production environment. The Quick Start Guide is intended for production deployments with three or more nodes, providing high availability and scalability. For full details, see the full Installation Guide.
Step 1: Mount the ISO
mkdir -p /mnt/esb3027
mount -o loop,ro esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Step 2: Install the Base Cluster Software
/mnt/esb3027/install
Step 3: (Air-gapped only) Mount the Extras ISO and Load Images
mkdir -p /mnt/esb3027-extras
mount -o loop,ro esb3027-acd-manager-extras-X.Y.Z.iso /mnt/esb3027-extras
/mnt/esb3027-extras/load-images
Step 4: Fetch the Node Token
cat /var/lib/rancher/k3s/server/node-token
Step 5: Join Additional Nodes
On each additional node, repeat Step 1, then run:
/mnt/esb3027/join-server https://<primary-server-ip>:6443 <node-token>
# or for agent nodes:
/mnt/esb3027/join-agent https://<primary-server-ip>:6443 <node-token>
Step 6: Deploy the Cluster Helm Chart
helm install --wait --timeout 10m acd-cluster /mnt/esb3027/helm/charts/acd-cluster
Step 7: Deploy the Manager Helm Chart
helm install acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m
Step 8: Next Steps
See the Post Install Guide for post-installation steps and recommendations.
For configuration details and troubleshooting, see the full Installation Guide.
1.3.4.4 - Installation Guide
Installing the Primary Server Node
Mount the ESB3027 ISO
Start by mounting the core ESB3027 ISO on the system. There are no limitations on the exact
mountpoint used, but for this document, we will assume /mnt/esb3027.
mkdir -p /mnt/esb3027
mount -o loop,ro esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Run the installer
Run the install command to install the base cluster software.
/mnt/esb3027/install
(Air-gapped only) Mount the “Extras” ISO and Load Container Images
In an air-gapped environment, after running the installer, the “extras” image must be mounted. This image contains publicly available container images that otherwise would be simply downloaded from the source repositories.
mkdir -p /mnt/esb3027-extras
mount -o loop,ro esb3027-acd-manager-extras-X.Y.Z.iso /mnt/esb3027-extras
The public container images for third-party products such as Kafka, Redis, Zitadel, etc., need to be loaded into the container runtime. An embedded registry mirror is used to distribute these images to other nodes within the cluster, so this only needs to be performed on one machine.
/mnt/esb3027-extras/load-images
Fetch the primary node token
In order to join additional nodes into the cluster, a unique node token must be provided. This token is automatically generated on the primary node during the installation process. Retrieve this now, and take note of it for later use.
cat /var/lib/rancher/k3s/server/node-token
Join Additional Server Nodes
From each additional server node, mount the core ISO and join the cluster using the following commands.
mkdir -p /mnt/esb3027
mount esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Obtain the node token from the primary server as you will need to include it in the following command. You will also need the URL to the primary server for which to connect.
/mnt/esb3027/join-server https://primary-server-ip:6443 abcdefg0123456...987654321
Where primary-server-ip is replaced with the IP address to which this node should connect to the
primary server, and abcdef...321 is the contents of the node-token retrieved from the primary server.
Repeat the above steps on each additional Server node in the cluster.
Join Agent Nodes
From each additional agent node, mount the core ISO and join the cluster using the following commands.
mkdir -p /mnt/esb3027
mount esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Obtain the node token from the primary server as you will need to include it in the following command. You will also need the URL to the primary server for which to connect.
/mnt/esb3027/join-agent https://primary-server-ip:6443 abcdefg0123456...987654321
Where primary-server-ip is replaced with the IP address to which this node should connect to the
primary server, and abcdef...321 is the contents of the node-token retrieved from the primary server.
Repeat the above steps on each additional Agent node in the cluster.
Verify the state of the cluster
At this point, a generic Kubernetes cluster should have multiple nodes connected and be marked Ready. Verify this is the case by running the following from any one of the Server nodes.
kubectl get nodes
Each node in the cluster should be listed in the output with the status “Ready”, and the Server nodes should have “control-plane” in the listed Roles. If this is not the case, see the Troubleshooting Guide to help diagnose the problem.
Deploy the cluster helm chart
The acd-cluster helm chart, which is included on the core ISO, contains the clustering software which
is required for self-hosted clusters, but may be optional in Cloud deployments. Currently this consists
of a PostgreSQL database server, but additional components may be added in later releases.
helm install --wait --timeout 10m acd-cluster /mnt/esb3027/helm/charts/acd-cluster
Deploying the Manager chart
The acd-manager helm chart is used to deploy the acd-manager application as well as any of the
third-party services on which the chart depends. Installing this chart requires at least a minimal
configuration to be applied. To get started, either copy the default values.yaml file from the chart
directory /mnt/esb3027/helm/charts/acd-manager/values.yaml or copy the following minimal template to a
writable location such as the user’s home directory.
global:
hosts:
manager:
- host: manager.local
routers:
- name: director-1
address: 192.0.2.1
- name: director-2
address: 192.0.2.2
zitadel:
zitadel:
configmapConfig:
ExternalDomain: manager.local
Where:
manager.localis either the external IP or resolvable DNS name used to access the manager’s cluster.- All director instances should be listed in the
global.hosts.routerssection. Thenamefield is used in URLs, and must consist of only alpha-numeric characters or ‘.’, ‘-’, or ‘_’.
Further details on the available configuration options in the default values.yaml file can be found in
the Configuration Guide.
You must set at a minimum the following properties:
| Property | Type | Description |
|---|---|---|
| global.hosts.manager | Array | List of external IP addresses or DNS hostnames for each node in the cluster |
| global.hosts.router | Array | List of name and address for each instance of ESB3024 AgileTV CDN Director |
| zitadel.zitadel.configmapConfig.ExternalDomain | String | External DNS domain name or IP address of one manager node. This must match the first entry from global.hosts.manager |
Note! The Zitadel ExternalDomain must match the hostname or IP address given in the first
global.hosts.manager entry, and MUST match the Origin used when accessing Zitadel. This is enforced by
CORS.
Hint: For non-air-gapped environments, where no DNS servers are present, a third-party service
sslip.io may be used to provide a resolvable DNS name which can be used for both the
global.hosts.manager and Zitadel ExternalDomain entries. Any IP address passed as
W.X.Y.Z.sslip.io will resolve to the IP W.X.Y.Z
Only the value used for Zitadel’s ExternalDomain may be used to access Zitadel due to CORS
restrictions. E.g. if that is set to “10.10.10.10.sslip.io”, then Zitadel must be accessed via the URL
https://10.10.10.10.sslip.io/ui/console. This must match the first entry in global.hosts.manager as
that entry will be used by internal services that need to interact with Zitadel, such as the frontend
GUI and the manager API services.
Importing TLS Certificates
By default, the manager will generate a self-signed TLS certificate for use with the cluster ingress.
In production environments, it is recommended to use a valid TLS certificate issued by a trusted Certificate Authority (CA).
To install the TLS certificate pair into the ingress controller, the certificate and key must be saved in a Kubernetes secret. The simplest way of doing this is to let Helm generate the secret by including the PEM formatted certificate and private key directly in the configuration values. Alternatively, the secret can be created manually and simply referenced by the configuration.
Option 1: Let Helm manage the secret
To have Helm automatically manage the secret based on the PEM formatted certificate and key, add a record
to ingress.secrets as described in the following snippet.
ingress:
secrets:
- name: <secret-name>
key: |-
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
certificate: |-
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
Option 2: Manually creating the secret
To manually create the secret in Kubernetes, execute the following command: This will create a secret named “secret-name”.
kubectl create secret tls secret-name --cert=tls.crt --key=tls.key
Configure the Ingress
The ingress controllers must be configured as to the name of the secret holding the certificate and key files. Additionally, the DNS hostname or IP address, covered by the certificate, which Must be used to access the ingress, must be set in the configuration.
ingress:
hostname: <dns-hostname>
tls: true
secretName: <secret-name>
zitadel:
ingress:
tls:
- hosts:
- <dns-hostname>
secretName: <secret-name>
confd:
ingress:
hostname: <dns-hostname>
tls: true
secretName: <secret-name>
mib-frontend:
ingress:
hostname: <dns-hostname>
tls: true
secretName: <secret-name>
dns-hostname- A valid DNS hostname for the cluster which is valid for the certificate. For compatibility with Zitadel and CORS restrictions, this MUST be the same DNS hostname listed as the first entry inglobal.hosts.manager.secret-name- An arbitry name used to identify the Kubernetes secret containing the TLS certificate and key. This has a maximum length limitation of 53 characters.
Loading Maxmind GeoIP databases
The Maxmind GeoIP databases are required if GeoIP lookups are to be performed by the manager. If this functionality is used, then Maxmind formatted GeoIP databases must be configured. The following databases are used by the manager.
GeoIP2-City.mmdb- The City Database.GeoLite2-ASN.mmdb- The ASN Database.GeoIP2-Anonymous-IP.mmdb- The VPN and Anonymous IP database.
A helper utility has been provided on the ISO called generate-maxmind-volume that will prompt the user
for the locations of these 3 database files, and the name of a volume, which will be created in
Kubernetes. After running this command, set the manager.maxmindDbVolume property in the configuration
to the volume name.
To run the utility, use:
/mnt/esb3027/generate-maxmind-volume
Installing the Chart
Install the acd-manager helm chart using the following command: (This assumes the configuration is in
~/values.yaml)
helm install acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m
By default, there is not expected to be much output from the helm install command itself. If you would
like to see more detailed information in real-time throughout the deployment process, you can add the
--debug flag to the command:
helm install acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m --debug
Note: The
--timeout 10mflag increases the default Helm timeout from 5 minutes to 10 minutes. This is recommended because the default may not be sufficient on slower hardware or in resource-constrained environments. You may need to adjust the timeout value further depending on your system’s performance or deployment conditions.
Monitor the chart rollout with the following command:
kubectl get pods
The output of which should look similar to the following:
NAME READY STATUS RESTARTS AGE
acd-cluster-postgresql-0 1/1 Running 0 44h
acd-manager-6c85ddd747-5j5gt 1/1 Running 0 43h
acd-manager-confd-558f49ffb5-n8dmr 1/1 Running 0 43h
acd-manager-gateway-7594479477-z4bbr 1/1 Running 0 43h
acd-manager-grafana-78c76d8c5-c2tl6 1/1 Running 0 43h
acd-manager-kafka-controller-0 2/2 Running 0 43h
acd-manager-kafka-controller-1 2/2 Running 0 43h
acd-manager-kafka-controller-2 2/2 Running 0 43h
acd-manager-metrics-aggregator-f6ff99654-tjbfs 1/1 Running 0 43h
acd-manager-mib-frontend-67678c69df-tkklr 1/1 Running 0 43h
acd-manager-prometheus-alertmanager-0 1/1 Running 0 43h
acd-manager-prometheus-server-768f5d5c-q78xb 1/1 Running 0 43h
acd-manager-redis-master-0 2/2 Running 0 43h
acd-manager-redis-replicas-0 2/2 Running 0 43h
acd-manager-selection-input-844599bc4d-x7dct 1/1 Running 0 43h
acd-manager-telegraf-585dfc5ff8-n8m5c 1/1 Running 0 43h
acd-manager-victoria-metrics-single-server-0 1/1 Running 0 43h
acd-manager-zitadel-69b6546f8f-v9lkp 1/1 Running 0 43h
acd-manager-zitadel-69b6546f8f-wwcmx 1/1 Running 0 43h
acd-manager-zitadel-init-hnr5p 0/1 Completed 0 43h
acd-manager-zitadel-setup-kjnwh 0/2 Completed 0 43h
The output contains a “READY” column, which indicates the number of ready pods on the left, and the number of requested pods on the right. Pods with status “Completed” are one time commands that have terminated successfully and can be ignored in this output. For “Running” pods, once all pods have the same number on both sides of the “READY” status the rollout is complete.
If a Pod is marked as “CrashLoopBackoff” or “Error” this means that either one of the containers in the pod has failed to deploy, or that the container has terminated in an Error state. See the Troubleshooting Guide to help diagnose the problem. The Kubernetes cluster will retry failed pod deployments several times, and the number in the “RESTARTS” column will show the number of times that has happened. If a pod restarts during the initial rollout, this may simply be that the state of the cluster was not as expected by the pod at that time, and this can be safely ignored. After the initial rollout has completed, the pods should stabilize, and multiple restarts may be an indication that something is wrong. In that case, refer to the Troubleshooting Guide for more information.
Next Steps
For post-installation steps, see the Post Install Guide.
1.3.4.5 - Upgrade Guide
Upgrade Compatibility Matrix
The following table lists each release and the minimum previous version that supports a direct upgrade. Unless otherwise noted, production releases (even minor versions: 1.0.x, 1.2.x, 1.4.x, etc.) support direct upgrade from the previous two minor versions.
| Release | Minimum Compatible Version for Upgrade | Notes |
|---|---|---|
| 1.4.1 | 1.4.0 | Direct upgrade from 1.2.1 is not supported. |
| 1.4.0 | — | No direct upgrade from previous versions; requires clean install. |
| 1.2.1 | — | No direct upgrade from previous versions; requires clean install. |
Before You Begin
Backup your configuration and data:
Before starting the upgrade, back up your current values.yaml and any persistent data (such as
database volumes or important configuration files). For instructions on how to set up and take
backups of persistent volume claims (PVCs), see the Storage Guide. This ensures
you can recover if anything unexpected occurs during the upgrade process.
About the install script:
Running the install script from the new ISO is safe for upgrades. It is designed to be idempotent
and will not overwrite your existing configuration.
Downtime and rolling restarts:
During the upgrade, the cluster may experience brief downtime or rolling restarts as pods are updated. Plan accordingly if you have production workloads.
Upgrading the Cluster
Review Configuration Before Upgrading
Before performing the upgrade, carefully review your current configuration values against the
default values.yaml file provided on the ESB3027 ISO. This ensures that any new or changed
configuration options are accounted for, and helps prevent issues caused by outdated or missing
settings. The values.yaml file can be found at:
/mnt/esb3027/helm/charts/acd-manager/values.yaml
Compare your existing configuration (typically in ~/values.yaml or your deployment’s values
file) with the ISO’s values.yaml and update your configuration as needed before running the
upgrade commands below.
Mount the ESB3027 ISO
Start by mounting the core ESB3027 ISO on the system. There are no limitations on the exact
mountpoint used, but for this document, we will assume /mnt/esb3027.
mkdir -p /mnt/esb3027
mount -o loop,ro esb3027-acd-manager-X.Y.Z.iso /mnt/esb3027
Run the installer
Run the install command to install the base cluster software.
/mnt/esb3027/install
(Air-gapped only) Mount the “Extras” ISO and Load Container Images
In an air-gapped environment, after running the installer, the “extras” image must be mounted. This image contains publicly available container images that otherwise would be simply downloaded from the source repositories.
mkdir -p /mnt/esb3027-extras
mount -o loop,ro esb3027-acd-manager-extras-X.Y.Z.iso /mnt/esb3027-extras
The public container images for third-party products such as Kafka, Redis, Zitadel, etc., need to be loaded into the container runtime. This only needs to be performed once per upgrade, on a single node. An embedded registry mirror is used to distribute these images to other nodes within the cluster.
/mnt/esb3027-extras/load-images
Upgrade the cluster helm chart
The acd-cluster helm chart, which is included on the core ISO, contains the clustering software
which is required for self-hosted clusters, but may be optional in Cloud deployments. Currently
this consists of a PostgreSQL database server, but additional components may be added in later
releases.
helm upgrade --wait --timeout 10m acd-cluster /mnt/esb3027/helm/charts/acd-cluster
Upgrade the Manager chart
Upgrade the acd-manager helm chart using the following command: (This assumes the configuration is
in ~/values.yaml)
helm upgrade acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m
By default, there is not expected to be much output from the helm upgrade command itself. If you
would like to see more detailed information in real-time throughout the deployment process, you
can add the --debug flag to the command:
helm upgrade acd-manager /mnt/esb3027/helm/charts/acd-manager --values ~/values.yaml --timeout 10m --debug
Note: The
--timeout 10mflag increases the default Helm timeout from 5 minutes to 10 minutes. This is recommended because the default may not be sufficient on slower hardware or in resource-constrained environments. You may need to adjust the timeout value further depending on your system’s performance or deployment conditions.
Monitor the chart rollout with the following command:
kubectl get pods
The output of which should look similar to the following:
NAME READY STATUS RESTARTS AGE
acd-cluster-postgresql-0 1/1 Running 0 44h
acd-manager-6c85ddd747-5j5gt 1/1 Running 0 43h
acd-manager-confd-558f49ffb5-n8dmr 1/1 Running 0 43h
acd-manager-gateway-7594479477-z4bbr 1/1 Running 0 43h
acd-manager-grafana-78c76d8c5-c2tl6 1/1 Running 0 43h
acd-manager-kafka-controller-0 2/2 Running 0 43h
acd-manager-kafka-controller-1 2/2 Running 0 43h
acd-manager-kafka-controller-2 2/2 Running 0 43h
acd-manager-metrics-aggregator-f6ff99654-tjbfs 1/1 Running 0 43h
acd-manager-mib-frontend-67678c69df-tkklr 1/1 Running 0 43h
acd-manager-prometheus-alertmanager-0 1/1 Running 0 43h
acd-manager-prometheus-server-768f5d5c-q78xb 1/1 Running 0 43h
acd-manager-redis-master-0 2/2 Running 0 43h
acd-manager-redis-replicas-0 2/2 Running 0 43h
acd-manager-selection-input-844599bc4d-x7dct 1/1 Running 0 43h
acd-manager-telegraf-585dfc5ff8-n8m5c 1/1 Running 0 43h
acd-manager-victoria-metrics-single-server-0 1/1 Running 0 43h
acd-manager-zitadel-69b6546f8f-v9lkp 1/1 Running 0 43h
acd-manager-zitadel-69b6546f8f-wwcmx 1/1 Running 0 43h
acd-manager-zitadel-init-hnr5p 0/1 Completed 0 43h
acd-manager-zitadel-setup-kjnwh 0/2 Completed 0 43h
Rollback Procedure
If you encounter issues after upgrading, you can use Helm’s rollback feature to revert the acd-cluster and acd-manager deployments to their previous working versions.
To see the revision history for a release:
helm history acd-cluster
helm history acd-manager
To rollback to the previous revision (or specify a particular revision number):
helm rollback acd-cluster <REVISION>
helm rollback acd-manager <REVISION>
Replace <REVISION> with the desired revision number, or use 1 for the initial deployment,
2 for the first upgrade, etc. If you want to rollback to the immediately previous version,
you can omit the revision number to rollback to the last one:
helm rollback acd-cluster
helm rollback acd-manager
After performing a rollback, monitor the pods to ensure the cluster returns to a healthy state:
kubectl get pods
Refer to the Troubleshooting Guide if you encounter further issues.
Complete Cluster Replacement (Wipe and Reinstall)
If you need to upgrade between versions that do not support direct upgrade (as indicated in the upgrade compatibility matrix), you can perform a complete cluster replacement. This process will completely remove the existing cluster from all nodes and allow you to install the new version as if starting from scratch.
Warning: This method will permanently delete all cluster data, configuration, and persistent volumes from every node. It is equivalent to reinstalling the operating system. There is no rollback possible. Ensure you have taken full backups of any data you wish to preserve before proceeding.
Step 1: Remove the Existing Cluster
On each node in the cluster, run the built-in k3s kill-all script to remove all cluster components:
sudo /usr/local/bin/k3s-killall.sh
sudo /usr/local/bin/k3s-uninstall.sh
Repeat this process on every node that was part of the cluster.
Step 2: Install the New Version
After all nodes have been wiped, follow the standard installation procedure to deploy the new version of the cluster. See the Installation Guide for detailed steps.
This method allows you to jump between unsupported versions without reinstalling or reconfiguring the operating system, but all cluster data and configuration will be lost.
1.3.4.6 - Post Installation Guide
After installing the cluster, there are a few steps that should be taken to complete the setup.
Create an Admin User
The ESB3027 AgileTV CDN Manager ships with a default user account, but this account is only intended as a way to log in and create an actual user. Attempting to authenticate other services such as the MIB Frontend Configuration GUI, may not work using this pre-provisioned account.
You will need the IP address or DNS name specified in the configuration as both the first manager host and the Zitadel External Domain.
global:
hosts:
manager:
- host: manager.local
Using a web browser, connect to the following URL, replacing manager.local with the IP or DNS name
from the configuration above:
https://manager.local/ui/console
You must authenticate using the default credentials:
Username: admin@agiletv.dev
Password: Password1!
It will ask you to set up Multi-Factor Authentication, however you MUST skip this step for now, as it is not currently supported everywhere in the manager’s APIs.
On the menu bar at the top of the screen, click “Users” and proceed to create a New User. Enter the required information, and for now, ensure the “Email Verified” and “Set Initial Password” boxes are checked. Zitadel will attempt to send a confirmation EMail if the “Email Verified” box is not checked, however on initial installation, the SMTP server details have not been configured.
You should now be able to authenticate to the MIB Frontend GUI at https://manager.local/gui using
the credentials for the new user.
Configure an SMTP Server
Zitadel requires an SMTP server to be configured in order to send validation emails and support
communication with users for password resets, etc. If you have an SMTP server, you can configure
it by logging back into the Zitadel Web UI at https://manager.local/ui/console, clicking on
“Default Settings” at the top of the page, and configuring the SMTP provider from the menu on the
left. After this has been performed, if a new user account is created, an E-Mail will be sent to
the configured E-Mail address with a verification link, which must be clicked before the account
will be valid.
1.3.5 - Configuration Guide
Overview
When deploying the acd-manager helm chart, a configuration file containing the chart values must
be supplied to Helm. The default values.yaml file can be found on the ISO in the chart’s directory.
Helm does not require that the complete file be supplied at install time, as any files supplied via the
--values command will be merged with the defaults from the chart. This allows the operator to maintain
a much simpler configuration file containing only the modified values. Additionally, values may be
individually overridden by passing --set key=value to the Helm command. However, this is discouraged for
all but temporary cases, as the same arguments must be specified any time the chart is updated.
The default values.yaml file is located on the ISO under the subpath /helm/charts/acd-manager/values.yaml
Since the ISO is mounted read-only, you must copy this file to a writable location to make changes. Helm
supports multiple --values arguments where all files will be merged left-to-right before being merged
with the chart defaults.
Applying the Configuration
After updating the configuration file, you must perform a helm upgrade for the changes to be propagated
to the cluster. Helm tracks the changes in each revision, and supports rolling back to previous configurations.
During the initial chart installation, the configuration values will be supplied to Helm through the helm install
command, but to update an existing installation, the following command line shall be used instead.
helm upgrade acd-manager /mnt/esb3027/helm/charts/acd-manager --values /path/to/values.yaml
Note: Both the helm install and helm upgrade commands take many of the same arguments, and a shortcut
exists helm upgrade --install which can be used in place of either, to update an existing installation, or
deploy a new installation if one did not previously exist.
If the configuration update was unsuccessful, you can roll back to a previous revision using the following
command. Keep in mind, this will not change the values.yaml file on disk, so you must revert the changes
to that file manually, or restore the file from a backup.
helm rollback acd-manager <revision_number>
You can view the current revision number of all installed charts with helm list --all
If you wish to temporarily change one or more values, for instance to increase the manager log level from “info”
to “debug”, you can do so with the --set command.
helm upgrade acd-manager /mnt/esb3027/helm/charts/acd-manager --values /path/to/values.yaml --set manager.logLevel=debug
It is also possible to split the values.yaml into multiple individual files, for instance to separate manager
and metrics values in two files using the following commands. All files will be merged left to right by Helm.
Take notice however, that doing this will require all values files to be supplied in the same order any time
a helm upgrade is performed in the future.
helm upgrade acd-manager /mnt/esb3027/helm/charts/acd-manager --values /path/to/values1.yaml --values /path/to/values2.yaml
Before applying new configuration, it is recommended to perform a dry-run to ensure that the templates
can be rendered properly. This does not guarantee that the templates will be accepted by Kubernetes, only
that the templates can be properly rendered using the supplied values. The rendered templates will be output
to the console.
helm upgrade ... --dry-run
In the event that the helm upgrade fails to produce the desired results, e.g. if the correct configuration
did not propagate to all required pods, simply performing a helm uninstall acd-manager followed by the original
helm install command will force all pods to be redeployed. This is service affecting however and should only be
performed as a last-resort as all pods will be destroyed and recreated.
Configuration Reference
In this section, we break down the configuration file and look more in-depth into the options available.
Globals
The global section, is a special-case section in Helm, intended for sharing global values between charts.
most of the configuration properties here can be ignored, as they are intended as a means of globally
providing defaults that affect nested subcharts. The only necessary field here is the hosts configuration.
global:
hosts:
manager:
- host: manager.local
routers:
- name: default
address: 127.0.0.1
edns_proxy: []
geoip: []
| key | Type | Description |
|---|---|---|
| global.hosts.manager | Array | List of external IP addresses or DNS hostnames for all nodes in the Manager cluster |
| global.hosts.routers | Array | List of ESB3024 AgileTV CDN Director instances |
| global.hosts.edns_proxy | Array | List of EDNS Proxy addresses |
| global.hosts.geoip | Array | List of GeoIP Proxy addresses |
The global.hosts.manager record contains a list of objects containing a single host field. The first
of which is used by several internal services to contact Zitadel for user authentication and authorization.
Since Zitadel, which provides these services enforces CORS protections, this must match exacly the Origin
used to access Zitadel.
The global.hosts.routers record contains a list of objects each with a name and address field. The
name field is a unique identifier used in URLs to refer to the Director instance, and the address field
is the IP address or DNS name used to communicate with the Director node. Only Director instances run outside
of this cluster need to be specified here, as instances running in Kubernetes can utilize the cluster’s auto-
discovery system.
The global.hosts.edns_proxy record contains a list of objects each with an address and port field. This
list is currently unused.
The global.hosts.geoip record contains a list of objects each with an address and port field. This list
should refer to the GeoIP Proxies used by the Frontend GUI. Currently only one GeoIP proxy is supported.
Common Parameters
This section contains common parameters that are namespaced to the acd-manager chart. These should be left at their default values under most circumstances.
| Key | Type | Description |
|---|---|---|
| kubeVersion | String | Override the Kubernetes version reported by .Capabilities |
| apiVersion | String | Override the Kubernetes API version reported by .Capabilities |
| nameOverride | String | Partially override common.names.name |
| fullnameOverride | String | Fully override common.names.name |
| namespaceOverride | String | Fully override common.names.namespace |
| commonLabels | Object | Labels to add to all deployed objects |
| commonAnnotations | Object | Annotations to add to all deployed objects |
| clusterDomain | String | Kubernetes cluster domain name |
| extraDeploy | Array | List of extra Kubernetes objects to deploy with the release |
| diagnosticMode.enabled | Boolean | Enable Diagnostic mode (All probes will be disabled and the command will be overridden) |
| diagnosticMode.command | Array | Override the command when diagnostic mode is enabled |
| diagnosticMode.args | Array | Override the command line arguments when diagnostic mode is enabled |
Manager
This section represents the configuration options for the ACD Manager’s API server.
| Key | Type | Description |
|---|---|---|
| manager.image.registry | String | The docker registry |
| manager.image.repository | String | The docker repository |
| manager.image.tag | String | Override the image tag |
| manager.image.digest | String | Override a specific image digest |
| manager.image.pullPolicy | String | The image pull policy |
| manager.image.pullSecrets | Array | A list of secret names containing credentials for the configured image registry |
| manager.image.debug | boolean | Enable debug mode for the containers |
| manager.logLevel | String | Set the log level used in the containers |
| manager.replicaCount | Number | Number of manager replicas to deploy. This value is ignored if the Horizontal Pod Autoscaler is enabled |
| manager.containerPorts.http | Number | Port number exposed by the container for HTTP traffic |
| manager.extraContainerPorts | Array | List of additional container ports to expose |
| manager.livenessProbe | Object | Configuration for the liveness probe on the manager container |
| manager.readinessProbe | Object | Configuration for the readiness probe on the manager container |
| manager.startupProbe | Object | Configuration for the startup probe on the manager container |
| manager.customLivenessProbe | Object | Override the default liveness probe |
| manager.customReadinessProbe | Object | Override the default readiness probe |
| manager.customStartupProbe | Object | Override the default startup probe |
| manager.resourcePreset | String | Set the manager resources according to one common preset |
| manager.resources | Object | Set request and limits for different resources like CPU or memory |
| manager.podSecurityContext | Object | Set the security context for the manager pods |
| manager.containerSecurityContext | Object | Set the security context for all containers inside the manager pods |
| manager.maxmindDbVolume | String | Name of a Kubernetes volume containing Maxmind GeoIP, ASN, and Anonymous IP databases |
| manager.existingConfigmap | String | Reserved for future use |
| manager.command | Array | Command executed inside the manager container |
| manager.args | Array | Arguments passed to the command |
| manager.automountServiceAccountToken | Boolean | Mount Service Account token in manager pods |
| manager.hostAliases | Array | Add additional entries to /etc/hosts in the pod |
| manager.deploymentAnnotations | Object | Annotations for the manager deployment |
| manager.podLabels | Object | Extra labels for manager pods |
| manager.podAnnotations | Object | Extra annotations for the manager pods |
| manager.podAffinityPreset | String | Allowed values soft or hard |
| manager.podAntiAffinityPreset | String | Allowed values soft or hard |
| manager.nodeAffinityPreset.type | String | Allowed values soft or `hard |
| manager.nodeAffinityPreset.key | String | Node label key to match |
| manager.nodeAffinityPreset.values | Array | List of node labels to match |
| manager.affinity | Object | Override the affinity for pod assignments |
| manager.nodeSelector | Object | Node labels for manager pod assignments |
| manager.tolerations | Array | Tolerations for manager pod assignment |
| manager.updateStrategy.type | String | Can be set to RollingUpdate or Recreate |
| manager.priorityClassName | String | Manager pods’ priorityClassName |
| manager.topologySpreadConstraints | Array | Topology Spread Constraints for manager pod assignment spread across the cluster among failure-domains |
| manager.schedulerName | String | Name of the Kubernetes scheduler for manager pods |
| manager.terminationGracePeriodSeconds | Number | Seconds manager pods need to terminate gracefully |
| manager.lifecycleHooks | Object | Lifecycle Hooks for manager containers to automate configuration before or after startup |
| manager.extraEnvVars | Array | List of extra environment variables to add to the manager containers |
| manager.extraEnvVarsCM | Array | List of Config Maps containing extra environment variables to pass to the Manager pods |
| manager.extraEnvVarsSecret | Array | List of Secrets containing extra environment variables to pass to the Manager pods |
| manager.extraVolumes | Array | Optionally specify extra list of additional volumes for the manager pods |
| manager.extraVolumeMounts | Array | Optionally specify extra list of additional volume mounts for the manager pods |
| manager.sidecars | Array | Add additional sidecar containers to the manager pods |
| manager.initContainers | Array | Add additional init containers to the manager pods |
| manager.pdb.create | Boolean | Enable / disable a Pod Disruption Budget creation |
| manager.pdb.minAvailable | Number | Minimum number/precentage of pods that should remain scheduled |
| manager.pdb.maxUnavailable | Number | Maximum number/percentage of pods that may be made unavailable |
| manager.autoscaling.vpa | Object | Vertical Pod Autoscaler Configuration. Not used for self-hosted clusters |
| manager.autoscaling.hpa | Object | Horizontal Pod Autoscaler. Automatically scale the number of replicas based on resource utilization |
Gateway
The parameters under the gateway namespace are mostly identical to those of the manager section above, but
which affect the NGinx Proxy Gateway service. The additional properites here are described in the following
table.
| Key | Type | Description |
|---|---|---|
| gateway.service.type | String | Service Type |
| gateway.service.ports.http | Number | The service port |
| gateway.service.nodePorts | Object | Allows configuring the exposed node port if the service.type is “NodePort” |
| gateway.service.clusterIP | String | Override the ClusterIP address if the service.type is “ClusterIP” |
| gateway.service.loadBalancerIP | String | Override the LoadBalancer IP address if the service.type is “LoadBalancer” |
| gateway.service.loadBalancerSourceRanges | Array | Source CIDRs for the LoadBalancer |
| gateway.service.externalTrafficPolicy | String | External Traffic Policy for the service |
| gateway.service.annotations | Object | Additional custom annotations for the manager service |
| gateway.service.extraPorts | Array | Extra ports to expose in the manager service. (Normally used with the sidecar value) |
| gateway.service.sessionAffinity | String | Control where client requests go, to the same pod or round-robin |
| gateway.service.sessionAffinityConfig | Object | Additional settings for the sessionAffinity |
Selection Input
The parameters under the selectionInput namespace are mostly identical to those of the manager section above,
but which affect the selection input consumer service. The additional properties here are described in the
following table.
| Key | Type | Description |
|---|---|---|
| selectionInput.kafkaTopic | String | Name of the selection input kafka topic |
Metrics Aggregator
The parameters under the metricsAggregator namespace are mostly identical to those of the manager section above,
but which affect the metrics aggregator service.
Traffic Exposure
These parameters determine how the various services are exposed over the network.
| Key | Type | Description |
|---|---|---|
| service.type | String | Service Type |
| service.ports.http | Number | The service port |
| service.nodePorts | Object | Allows configuring the exposed node port if the service.type is “NodePort” |
| service.clusterIP | String | Override the ClusterIP address if the service.type is “ClusterIP” |
| service.loadBalancerIP | String | Override the LoadBalancer IP address if the service.type is “LoadBalancer” |
| service.loadBalancerSourceRanges | Array | Source CIDRs for the LoadBalancer |
| service.externalTrafficPolicy | String | External Traffic Policy for the service |
| service.annotations | Object | Additional custom annotations for the manager service |
| service.extraPorts | Array | Extra ports to expose in the manager service. (Normally used with the sidecar value) |
| service.sessionAffinity | String | Control where client requests go, to the same pod or round-robin |
| service.sessionAffinityConfig | Object | Additional settings for the sessionAffinity |
| networkPolicy.enabled | Boolean | Specifies whether a NetworkPolicy should be created |
| networkPolicy.allowExternal | Boolean | Doesn’t require server labels for connections |
| networkPolicy.allowExternalEgress | Boolean | Allow the pod to access any range of port and all destinations |
| networkPolicy.allowExternalClientAccess | Boolean | Allow access from pods with client label set to “true” |
| networkPolicy.extraIngress | Array | Add extra ingress rules to the Network Policy |
| networkPolicy.extraEgress | Array | Add extra egress rules to the Network Policy |
| networkPolicy.ingressPodMatchLabels | Object | Labels to match to allow traffic from other pods. |
| networkPolicy.ingressNSMatchLabels | Object | Labels to match to allow traffic from other namespaces. |
| networkPolicy.ingressNSPodMatchLabels | Object | Pod labels to match to allow traffic from other namespaces. |
| ingress.enabled | Boolean | Enable the ingress record generation for the manager |
| ingress.pathType | String | Ingress Path Type |
| ingress.apiVersion | String | Force Ingress API version |
| ingress.hostname | String | Match HOST header for the ingress record |
| ingress.ingressClassName | String | Ingress Class that will be used to implement the Ingress |
| ingress.path | String | Default path for the Ingress record |
| ingress.annotations | Object | Additional annotations for the Ingress resource. |
| ingress.tls | Boolean | Enable TLS configuration for the host defined at ingress.hostname |
| ingress.selfSigned | Boolean | Create a TLS secret for this ingress record using self-signed certificates generated by Helm |
| ingress.extraHosts | Array | An array with additional hostnames to be covered by the Ingress record. |
| ingress.extraPaths | Array | An array of extra path entries to be covered by the Ingress record. |
| ingress.extraTls | Array | TLS configuration for additional hostnames to be covered with this Ingress record. |
| ingress.secrets | Array | Custom TLS certificates as secrets |
| ingress.extraRules | Array | Additional rules to be covered with this Ingress record. |
Persistence
The following values control how persistent storage is used by the manager. Currently these have no effect as the Manager does not use any persistent volume claims, however they are documented here as the same properties are used in several subcontainers to configure persistence.
| Key | Type | Description |
|---|---|---|
| persistence.enabled | Boolean | Enable persistence using Persistent Volume Claims |
| persistence.mountPath | String | Path where to mount the volume |
| persistence.subPath | String | The subdirectory of the volume to mount |
| persistence.storageClass | String | Storage class of backing Persistent Volume Claim |
| persistence.annotations | Object | Persistent Volume Claim annotations |
| persistence.accessModes | Array | Persistent Volume Access Modes |
| persistence.size | String | Size of the data volume |
| persistence.dataSource | Object | Custom PVC data source |
| persistence.existingClaim | String | The name of an existing PVC to use for persistence |
| persistence.selector | Object | Selector to match existing Persistent Volume for data PVC |
Other Values
The following are additional parameters for the chart.
| Key | Type | Description |
|---|---|---|
| defaultInitContainers | Object | Configuration for default init containers. |
| rbac.create | Boolean | Specifies whether Role-Based Access Control Resources should be created. |
| rbac.rules | Object | Custom RBAC rules to apply |
| serviceAccount.create | Boolean | Specifies whether a ServiceAccount should be created |
| serviceAccount.name | String | Override the ServiceAccount name. If not set, a name will be generated automatically. |
| serviceAccount.annotations | Object | Additional Service Account annotations (evaluated as a template) |
| serviceAccount.automountServiceAccountToken | Boolean | Automount the service account token for the service account. |
| metrics.enabled | Boolean | Enable the export of Prometheus metrics. Not currently implemented |
| metrics.serviceMonitor.enabled | Boolean | If true, creates a Prometheus Operator ServiceMonitor |
| metrics.serviceMonitor.namespace | String | Namespace in which Prometheus is running |
| metrics.serviceMonitor.annotations | Object | Additional custom annotations for the ServiceMonitor |
| metrics.serviceMonitor.labels | Object | Extra labels for the ServiceMonitor |
| metrics.serviceMonitor.jobLabel | String | The name of the label on the target service to use as the job name in Prometheus |
| metrics.serviceMonitor.honorLabels | Boolean | Chooses the metric’s labels on collisions with target labels |
| metrics.serviceMonitor.tlsConfig | Object | TLS configuration used for scrape endpoints used by Prometheus |
| metrics.serviceMonitor.interval | Number | Interval at which metrics should be scraped. |
| metrics.serviceMonitor.scrapeTimeout | Number | Timeout after which the scrape is ended. |
| metrics.serviceMonitor.metricRelabelings | Array | Specify additional relabeling of metrics. |
| metrics.serviceMonitor.relabelings | Array | Specify general relabeling |
| metrics.serviceMonitor.selector | Object | Prometheus instance selector labels |
Sub-components
Confd
| Key | Type | Description |
|---|---|---|
| confd.enabled | Boolean | Enable the embedded Confd instance |
| confd.service.ports.internal. | Number | Port number to use for internal communication with the Confd TCP socket |
MIB Frontend
There are many additional properties that can be configured for the MIB Frontend service which are not
specified in the configuration file. The mib-frontend helm Chart follows the same basic template
as the acd-manager chart so documenting them all here would be unnecessarily repeatative. Virtually every
property in this chart can be configured under the mib-frontend namespace and be valid.
| Key | Type | Description |
|---|---|---|
| mib-frontend.enabled | Boolean | Enable the Configuration GUI |
| mib-frontend.frontend.resourcePreset | String | Use a preset resource configuration. |
| mib-frontend.frontend.resources | Object | Use custom resource configuration. |
| mib-frontend.frontend.autoscaling.hpa | Object | Horizontal Pod Autoscaler configuration for MIB Frontend component |
ACD Metrics
There are many additional properties that can be configured for the ACD metrics service which are not
specified in the configuration file. The acd-metrics helm Chart follows the same basic template
as the acd-manager chart, as do each of its subcharts. Documenting them all here would mostly be
unnecessarily repeatative. Virtually any property in this chart can be configured under the acd-metrics
namespace and be valid. For example, setting the resource preset for grafana can be achieved by setting
acd-metrics.grafana.resourcePreset etc.
| Key | Type | Description |
|---|---|---|
| acd-metrics.enabled | Boolean | Enable the ACD Metrics components |
| acd-metrics.telegraf.enabled | Boolean | Enable the Telegraf Database component |
| acd-metrics.prometheus.enabled | Boolean | Enable the Prometheus Service Instance |
| acd-metrics.grafana.enabled | Boolean | Enable the Grafana Service Instance |
| acd-metrics.victoria-metrics-single.enabled | Boolean | Enable Victoria Metrics Service instance |
Zitadel
Zitadel does not follow the same template as many of the other services. Below is a list of Zitadel specific properties.
| Key | Type | Description |
|---|---|---|
| zitadel.enabled | Boolean | Enable the Zitadel instance |
| zitadel.replicaCount | Number | Number of replicas in the Zitadel deployment |
| zitadel.image.repository | String | The full name of the image registry and repository for the Zitadel container |
| zitadel.setupJob | Object | Configuration for the initial setup job to configure the database |
| zitadel.zitadel.masterkeySecretName | String | The name of an existing Kubernetes secret containing the Zitadel Masterkey |
| zitadel.zitadel.configmapConfig | Object | The Zitadel configuration. See Configuration Options in ZITADEL |
| zitadel.zitadel.configmapConfig.ExternalDomain | String | The external domain name or IP address to which all requests must be made. |
| zitadel.service | Ojbect | Service configuration options for Zitadel |
| zitadel.ingress | Object | Traffic exposure parameters for Zitadel |
The zitadel.zitadel.configmapConfig.ExternalDomain MUST be configured with the same
value used as the first entry in in global.hosts.manager. Cross-Origin Resource Sharing (CORS)
is enforced with Zitadel, and only this origin specified here will be allowed to be used
to access Zitadel. The first entry in the global.hosts.manager Array will be used by
internal services, and if this does not match, authentication requests will not be accepted.
For example, if the global.hosts.manager entries look like this:
global:
hosts:
manager:
- host: foo.example.com
- host: bar.example.com
The Zitadel ExternalDomain must be set to foo.example.com, and all requests to Zitadel
must use foo.example.com. e.g https://foo.example.com/ui/console. Requests made to
bar.example.com will result in HTTP 404 errors.
Redis and Kafka
Both the redis and kafka subcharts follow the same basic structure as the acd-manager
chart, and the configurable values in each are nearly identical. Documenting the configuration
of these charts here would be unnecessarily redundant. However, the operator may wish to
adjust the resource configuration for these charts at the following locations:
| Key | Type | Description |
|---|---|---|
| redis.master.resources | Object | Resource configuration for the Redis master instance |
| redis.replica.resources | Object | Resource configuration for the Redis read-only replica instances |
| redis.replica.replicaCount | Number | Number of Read-only Redis replica instances |
| kafka.controller.resources | Object | Resource configuration for the Kafka controller |
| kafka.controller.replicaCount | Number | Number of Kafka controller replica instances to deploy |
Resource Configuration
All resource configuration blocks follow the same basic schema which is defined here.
| Key | Type | Description |
|---|---|---|
| resources.limits.cpu | String | The maximum CPU which can be consumed before the Pod is terminated. |
| resources.limits.memory | String | The maximum amount of memory the pod may consume before being killed. |
| resources.limits.ephemeral-storage | String | The maximum amount of storage a pod may consume |
| resources.requests.cpu | String | The minimum available CPU cores for each Pod to be assigned to a node. |
| resources.requests.memory | String | The minimum available Free Memory on a node for a pod to be assigned. |
| resources.requests.ephemeral-storage | String | The minimum amount of storage a pod requires to be assigned to a node. |
CPU values are specified in units of 1/1000 of a CPU e.g. “1000m” represents 1 core, “250m” is 1/4 of 1 core. Memory and Storage values are specified with the SI suffix, e.g. “250Mi” is 250MB, “3Gi” is 3GB, etc.
Most services also include a resourcePreset value which is a simple String representing
some common configurations.
The presets are as follows:
| Preset | Request CPU | Request Memory | Request Storage | Limit CPU | Limit Memory | Limit Storage |
|---|---|---|---|---|---|---|
| nano | 100m | 128Mi | 50Mi | 150m | 192Mi | 2Gi |
| micro | 250m | 256Mi | 50Mi | 375m | 384Mi | 2Gi |
| small | 500m | 512Mi | 50Mi | 750m | 768Mi | 2Gi |
| medium | 500m | 1024Mi | 50Mi | 750m | 1536Mi | 2Gi |
| large | 1.0 | 2048Mi | 50Mi | 1.5 | 3072Mi | 2Gi |
| xlarge | 1.0 | 3072Mi | 50Mi | 3.0 | 6144Mi | 2Gi |
| 2xlarge | 1.0 | 3072Mi | 50Mi | 6.0 | 12288Mi | 2Gi |
When considering the resource requests vs. limits, the request values should represent the minimum resource usage necessary to run the service, while the limits represent the maximum resources each pod in the deployment will be allowed to consume. The resource request and limits are per pod, so a service using “large” presets with 3 replicas will need a minimum of 3 full cores, and 6GB of available memory to start and may consume up to a maximum of 4.5 Cores and 9GB of memory across all nodes in the cluster.
Security Contexts
Most charts used in the deployment contain configuration for both Pod and Container security contexts. Below is additional information about the parameters there-in.
| Key | Type | Description |
|---|---|---|
| podSecurityContext.enabled | Boolean | Enable the Pod Security Context |
| podSecurityContext.fsGroupChangePolicy | String | Set filesystem group change policy for the nodes |
| podSecurityContext.sysctls | Array | Set kernel settings using sysctl interface for the pods |
| podSecurityContext.supplementalGroups | Array | Set filesystem extra groups for the pods |
| podSecurityContext.fsGroup | Number | Set Filesystem Group ID for the pods |
| containerSecurityContext.enabled | Boolean | Enable the container security context |
| containerSecurityContext.seLinuxOptions | Object | Set SELinux options for each container in the Pod |
| containerSecurityContext.runAsUser | Number | Set runAsUser in the containers Security Context |
| containerSecurityContext.runAsGroup | Number | Set runAsGroup in the containers Security Context |
| containerSecurityContext.runAsNonRoot | Boolean | Set runAsNonRoot in the containers Security Context |
| containerSecurityContext.readOnlyRootFilesystem | Boolean | Set readOnlyRootFilesystem in the containers Security Context |
| containerSecurityContext.privileged | Boolean | Set privileged in the container Security Context |
| containerSecurityContext.allowPrivilegeEscalation | Boolean | Set allowPrivilegeEscalation in the container’s security context |
| containerSecurityContext.capabilities.drop | Array | List of capabilities to be dropped in the container |
| containerSecurityContext.seccompProfile.type | String | Set seccomp profile in the container |
Probe Configuration
Each Pod uses healthcheck probes to determine the readiness of the pod. Three probe types are defined. startupProbe, readinessProbe, and livenessProbe. They all contain exactly the same configuration options, the only difference between the probe types is when they are executed.
Liveness Probe: Checks if the container is running. If this probe fails, Kubernetes restarts the container, assuming it is stuck or unhealthy.
Readiness Probe: Determines if the container is ready to accept traffic. If it fails, the container is removed from the service load balancer until it becomes ready again.
Startup Probe: Used during container startup to determine if the application has started successfully. It helps to prevent the liveness probe from killing a container that is still starting up.
The following table describes each of these properties:
| Property | Description |
|---|---|
| enabled | Determines whether the probe is active (true) or disabled (false). |
| initialDelaySeconds | Time in seconds to wait after the container starts before performing the first probe. |
| periodSeconds | How often (in seconds) to perform the probe. |
| timeoutSeconds | Number of seconds to wait for a probe response before considering it a failure. |
| failureThreshold | Number of consecutive failed probes before considering the container unhealthy (for liveness) or unavailable (for readiness). |
| successThreshold | Number of consecutive successful probes required to consider the container healthy or ready (usually 1). |
| httpGet | Specifies that the probe performs an HTTP GET request to check container health. |
| httpGet.path | The URL path to request during the HTTP GET probe. |
| httpGet.port | The port number or name where the HTTP GET request is sent. |
| exec | Specifies that the probe runs the specified command inside the container and expects a successful exit code to indicate health. |
| exec.command | An array of strings representing the command to run |
Only one of httpGet or exec may be specified in a single probe. These configurations are mutually exclusive.
1.3.6 - Networking
Port Usage
The following table describes the minimal firewall setup required between each node in the cluster for the Kubernetes cluster to function properly. Unless otherwise specified, these rules must allow traffic to pass between any nodes in the cluster.
| Protocol | Port | Source | Destination | Description |
|---|---|---|---|---|
| TCP | 2379-2380 | Server | Server | Etcd Service |
| TCP | 6443 | Any | Server | K3s Supervisor and Kubernetes API Server |
| UDP | 8472 | Any | Any | Flannel VXLAN |
| TCP | 10250 | Any | Any | Kubelet Metrics |
| TCP | 5001 | Any | Server | Spegel Registry Mirror |
| TCP | 9500 | Any | Any | Longhorn Management API |
| TCP | 8500 | Any | Any | Longhorn Agent |
| Any | N/A | 10.42.0.0/16 | Any | K3s Pods |
| Any | N/A | 10.43.0.0/16 | Any | K3s Services |
| TCP | 80 | Any | Any | Optional Ingress HTTP traffic |
| TCP | 443 | Any | Any | Ingress HTTPS Traffic |
The following table describes the required ports which must be allowed through any firewalls for the manager application. Access to these ports must be allowed from any client which requires access to these services towards any node in the cluster.
| Protocol | Port | Description |
|---|---|---|
| TCP | 443 | Ingress HTTPS Traffic |
| TCP | 3000 | Grafana |
| TCP | 9095 | Kafka |
| TCP | 9093 | Alertmanager |
| TCP | 9090 | Prometheus |
| TCP | 6379 | Redis |
Note: Port 443 is duplicated in both of the above tables. Port 443 is used by the internal applications running within the cluster to access Zitadel so all nodes in the cluster must have access to that port, and it’s also used to provide ingress services from outside the cluster for multiple applications.
Firewall Rules
What follows is an example script that can be used to open the required ports using
firewalld. Adjust the commands as necessary to fit the environment.
# Allow Kubernetes cluster ports (between nodes)
firewall-cmd --permanent --add-port=2379-2380/tcp
firewall-cmd --permanent --add-port=6443/tcp
firewall-cmd --permanent --add-port=8472/udp
firewall-cmd --permanent --add-port=10250/tcp
firewall-cmd --permanent --add-port=5001/tcp
firewall-cmd --permanent --add-port=9500/tcp
firewall-cmd --permanent --add-port=8500/tcp
# Allow all traffic from specific subnets for K3s pods/services
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="10.42.0.0/16" accept'
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="10.43.0.0/16" accept'
# Allow optional ingress HTTP/HTTPS traffic
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --permanent --add-port=443/tcp
# Allow ports for the manager application (from anywhere)
firewall-cmd --permanent --add-port=443/tcp
firewall-cmd --permanent --add-port=3000/tcp
firewall-cmd --permanent --add-port=9095/tcp
firewall-cmd --permanent --add-port=9093/tcp
firewall-cmd --permanent --add-port=9090/tcp
firewall-cmd --permanent --add-port=6379/tcp
# Reload firewalld to apply changes
firewall-cmd --reload
IP Routing
Proper IP routing is critical for cluster communication. The network must allow nodes to route traffic to each other’s pod CIDRs (e.g., 10.42.0.0/16, 10.43.0.0/16) and external clients to reach ingress and services. Verify that your network infrastructure permits routing between these subnets; otherwise, nodes may not communicate properly, impacting cluster functionality.
Handling Multiple Zones with Kubernetes Interfaces
Kubernetes creates virtual network interfaces for pods within the node’s network namespace. These interfaces are
typically not associated with any specific firewalld zone by default. Firewalld applies rules to the primary
physical interface (such as eth0), not directly to the pod interfaces.
1.3.7 - Storage Guide
Overview
Longhorn is an open-source distributed block storage system designed specifically for Kubernetes. It provides persistent storage for stateful applications by creating and managing storage volumes that are replicated across multiple nodes to ensure high availability. Longhorn integrates seamlessly with Kubernetes, allowing users to dynamically provision, attach, and manage persistent disks through standard Kubernetes PersistentVolumeClaims (PVCs).
Longhorn deploys a set of controller and replica engines as containers on each node, forming a distributed storage system. When a volume is created, Longhorn replicates data across multiple nodes, ensuring durability even in the event of node failures. The system also handles snapshots, backups, and restores, offering robust data protection. Kubernetes automatically mounts these volumes into Pods, providing persistent storage for stateful applications to operate reliably.
graph TD
subgraph Cluster Nodes
Node1["Node 1"]
Node2["Node 2"]
Node3["Node 3"]
end
subgraph Longhorn Components
Controller["Longhorn Controller"]
Replica1["Replica (Node 1)"]
Replica2["Replica (Node 2)"]
Replica3["Replica (Node 3)"]
end
subgraph Storage Volume
Volume["Persistent Volume"]
end
Node1 -->|Runs| Replica1
Node2 -->|Runs| Replica2
Node3 -->|Runs| Replica3
Controller -->|Manages| Volume
Replica1 & Replica2 & Replica3 -->|Replicate Data| VolumeAccessing the configuration GUI
Longhorn provides a web-based frontend for managing storage configurations across the Kubernetes cluster. This UI allows users to configure various aspects of the storage engine, such as the number of replicas, backup settings, snapshot management, and more.
Since this frontend does not include any authentication mechanisms and improper use could lead to significant data loss, access is restricted. To securely access the UI, a manual port-forward must be established.
You can set up a temporary connection to the Longhorn frontend using the following
kubectl port-forward command:
kubectl port-forward -n longhorn-system --address 0.0.0.0 svc/longhorn-frontend 8888:80
This command forwards local port 8888 to the Longhorn frontend service in the cluster. You can then access the UI by navigating to:
http://k3s-server:8888
This connection remains active as long as the port-forward command is running. To stop it, simply press
Ctrl+C. Make sure to run this command only when needed, and avoid leaving the UI accessible without
proper authentication.
1.3.8 - Metrics and Monitoring
The ESB3027 AgileTV CDN Manager includes a built-in metrics and monitoring solution based on Telegraf, Prometheus, and Grafana. A set of default Grafana dashboards provides visibility into CDN performance, displaying host metrics such as CPU, memory, network, and disk utilization—collected from the Director and Cache nodes via Telegraf—as well as streaming metrics from each Director instance. These metrics are stored in a Time-Series Database and visualized through Grafana dashboards. Additionally, the system supports custom dashboards using Prometheus as a data source, offering flexibility for customers to monitor all aspects of the CDN according to their specific needs.
Accessing Grafana
Grafana is accessible through the standard ingress controller at the /grafana base path.
To access Grafana, open a browser and navigate to the following URL, replacing manager.local
with the DNS name or IP address of your cluster ingress:
https://manager.local/grafana
Log in using the default administrator account credentials:
Username: admin
Password: edgeware
Known Limitation: Grafana does not currently support Single-Sign-On (SSO) using Zitadel accounts.
Once logged in, use the left column to click “Dashboards” and select the dashboard you wish to view.
Custom Dashboards
The grafana instance uses persistent storage within the cluster for data storage. Any custom dashboards or modifications to existing dashboards will be saved in the persistent storage volume, and will persist across software upgrades.
Billing and Licensing
A separate VictoriaMetrics Time-Series Database is included within the metrics component of the manager. It periodically scrapes usage data from Prometheus to calculate aggregated statistics and verify license compliance. This data is retained for at least one year. Grafana can also use this database as a source to display long-term usage metrics.
1.3.9 - Operations Guide
Overview
This guide details some of the common commands that will be necessary to operate the ESB3027 AgileTV CDN Manager software. Before starting, you will need at least a basic understanding of the following command line tooling.
Getting and Describing Kubernetes Resources
The two most common commands in Kubernetes are get and describe for a specific resource
such as a Pod or Service. Using kubectl get typically lists all resources of a particular
type; for example, kubectl get pods will display all pods in the current namespace. To obtain
more detailed information about a specific resource, use kubectl describe <resource>, such as
kubectl describe pod postgresql-0 to view details about that particular pod.
When describing a pod, the output includes a recent Event history at the bottom. This can be extremely helpful for troubleshooting issues, such as why a pod failed to deploy or was restarted. However, keep in mind that this event history only reflects the most recent events from the past few hours, so it may not provide insights into problems that occurred days or weeks ago.
Obtaining Logs
Each Pod maintains its own logs for each container. To fetch the logs of a specific pod, use
kubectl logs <pod_name>. Adding the -f flag will stream the logs in follow mode, allowing
real-time monitoring. If a pod contains multiple containers, by default, only the logs from the
primary container are shown. To view logs from a different container within the same pod, use
the -c <container_name> flag.
Since each pod maintains its own logs, retrieving logs from all replicas of a Deployment or StatefulSet may be necessary to get a complete view. You can use label selectors to collect logs from all pods associated with the same application. For example, to fetch logs from all pods belonging to the “acd-manager” deployment, run:
kubectl logs -l app.kubernetes.io/name=acd-manager
To find the labels associated with a specific Deployment or ReplicaSet, describe the resource and look for the “Labels” field.
The following table describes the common labels currently used by deployments in the cluster.
Component Labels
| Label (key=value) | Description |
|---|---|
| app.kubernetes.io/component=manager | Identifies the ACD Manager service |
| app.kubernetes.io/component=confd | Identifies the confd service |
| app.kubernetes.io/component=frontend | Identifies the GUI (frontend) service |
| app.kubernetes.io/component=gateway | Identifies the API gateway service |
| app.kubernetes.io/component=grafana | Identifies the Grafana monitoring service |
| app.kubernetes.io/component=metrics-aggregator | Identifies the metrics aggregator service |
| app.kubernetes.io/component=mib-frontend | Identifies the MIB frontend service |
| app.kubernetes.io/component=server | Identifies the Prometheus server component |
| app.kubernetes.io/component=selection-input | Identifies the selection input service |
| app.kubernetes.io/component=start | Identifies the Zitadel startup/init component |
| app.kubernetes.io/component=primary | Identifies the PostgreSQL primary node |
| app.kubernetes.io/component=controller-eligible | Identifies the Kafka controller-eligible node |
| app.kubernetes.io/component=alertmanager | Identifies the Prometheus Alertmanager |
| app.kubernetes.io/component=master | Identifies the Redis master node |
| app.kubernetes.io/component=replica | Identifies the Redis replica node |
Instance, Name, and Part-of Labels
| Label (key=value) | Description |
|---|---|
| app.kubernetes.io/instance=acd-manager | Helm release instance name (acd-manager) |
| app.kubernetes.io/instance=acd-cluster | Helm release instance name (acd-cluster) |
| app.kubernetes.io/name=acd-manager | Resource name: acd-manager |
| app.kubernetes.io/name=confd | Resource name: confd |
| app.kubernetes.io/name=grafana | Resource name: grafana |
| app.kubernetes.io/name=mib-frontend | Resource name: mib-frontend |
| app.kubernetes.io/name=prometheus | Resource name: prometheus |
| app.kubernetes.io/name=telegraf | Resource name: telegraf |
| app.kubernetes.io/name=zitadel | Resource name: zitadel |
| app.kubernetes.io/name=postgresql | Resource name: postgresql |
| app.kubernetes.io/name=kafka | Resource name: kafka |
| app.kubernetes.io/name=redis | Resource name: redis |
| app.kubernetes.io/name=victoria-metrics-single | Resource name: victoria-metrics-single |
| app.kubernetes.io/part-of=prometheus | Part of the Prometheus stack |
| app.kubernetes.io/part-of=kafka | Part of the Kafka stack |
Restarting a Pod
Since Kubernetes maintains a fixed number of replicas for each Deployment or ReplicaSet, deleting a
pod will cause Kubernetes to immediately recreate it, effectively restarting the pod. For example,
to restart the pod acd-manager-6c85ddd747-5j5gt, run:
kubectl delete pod acd-manager-6c85ddd747-5j5gt
Kubernetes will automatically detach that pod from any associated Service, preventing new connections from reaching it. It then spawns a new instance, which goes through startup, liveness, and readiness probes. Once the new pod passes the readiness probes and is marked as ready, the Service will start forwarding new traffic to it.
If multiple replicas are running, traffic will be distributed among the existing pods while the new pod is initializing, ensuring a seamless, zero-downtime operation.
Stopping and Starting a Deployment
Unlike traditional services, Kubernetes does not have a concept of stopping a service directly. Instead, you can temporarily scale a Deployment to zero replicas, which has the same effect.
For example, to stop the acd-manager Deployment, run:
kubectl scale deployment acd-manager --replicas=0
To restart it later, scale the deployment back to its original number of replicas, e.g.,
kubectl scale deployment acd-manager --replicas=1
If you want to perform a hard restart of all pods within a deployment, you can delete all pods with a specific label, and Kubernetes will automatically recreate them. For example, to restart all pods with the component label “manager,” use:
kubectl delete pod -l app.kubernetes.io/component=manager
This command causes Kubernetes to delete all matching pods, which are then recreated, effectively restarting the service without changing the deployment configuration.
If you want to perform a graceful restart of all pods within a deployment or statefulset, you can use the
rollout restart command to do so.
kubectl rollout restart deployment acd-manager
Or for a statefulset such as kafka.
kubectl rollout restart statefulset acd-manager-kafka-controller
Running command inside a pod
Sometimes it is necessary to run a command inside an existing Pod such as obtaining a bash shell.
Using the kubectl exec -it <podname> -- <command> can be used to do just that. Assuming we need to
run the confcli tool inside the confd pod acd-manager-confd-558f49ffb5-n8dmr that can be accomplished
using the following command:
kubectl exec -it acd-manager-confd-558f49ffb5-n8dmr -- /usr/bin/python3.11 /usr/local/bin/confcli
Note: The confd container does not have a shell, so specifying the python interpreter is necessary on this image.
Monitoring resource usage
Kubernetes includes an internal metrics API which can give some insight into the resource usage of the Pods and of the Nodes.
To list the current usage of the Pods in the cluster issue the following:
kubectl top pods
This will give output similar to the following:
NAME CPU(cores) MEMORY(bytes)
acd-cluster-postgresql-0 3m 44Mi
acd-manager-6c85ddd747-rdlg6 4m 15Mi
acd-manager-confd-558f49ffb5-n8dmr 1m 47Mi
acd-manager-gateway-7594479477-z4bbr 0m 10Mi
acd-manager-grafana-78c76d8c5-c2tl6 18m 144Mi
acd-manager-kafka-controller-0 19m 763Mi
acd-manager-kafka-controller-1 19m 967Mi
acd-manager-kafka-controller-2 25m 1127Mi
acd-manager-metrics-aggregator-f6ff99654-tjbfs 4m 2Mi
acd-manager-mib-frontend-67678c69df-tkklr 1m 26Mi
acd-manager-prometheus-alertmanager-0 2m 25Mi
acd-manager-prometheus-server-768f5d5c-q78xb 5m 53Mi
acd-manager-redis-master-0 12m 18Mi
acd-manager-redis-replicas-0 15m 14Mi
acd-manager-selection-input-844599bc4d-x7dct 3m 3Mi
acd-manager-telegraf-585dfc5ff8-n8m5c 1m 27Mi
acd-manager-victoria-metrics-single-server-0 2m 10Mi
acd-manager-zitadel-69b6546f8f-v9lkp 1m 76Mi
acd-manager-zitadel-69b6546f8f-wwcmx 1m 72Mi
Querying the metrics API for the nodes gives the aggregated totals for each node:
kubectl top nodes
Yields output similar to the following:
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
k3d-local-agent-0 118m 0% 1698Mi 21%
k3d-local-agent-1 120m 0% 661Mi 8%
k3d-local-agent-2 84m 0% 1054Mi 13%
k3d-local-server-0 115m 0% 1959Mi 25%
Taking a node out of service
To temporarily take a node out of service for maintenance, you can do so with minimal downtime, provided there are enough resources on other nodes in the cluster to handle the pods from the target node.
Step 1: Cordon the node.
This prevents new pods from being scheduled on the node:
kubectl cordon <node-name>
Step 2: Drain the node.
This moves existing pods off the node, respecting DaemonSets and local data:
kubectl drain <node-name> --ignore-daemonsets --delete-local-data
- The
--ignore-daemonsetsflag skips DaemonSet-managed pods, which are typically managed separately. - The
--delete-local-dataflag removes any local ephemeral data stored on the node.
Once drained, the node is effectively out of service.
To bring the node back into service:
Uncordon the node with:
kubectl uncordon <node-name>
This allows Kubernetes to schedule new pods on the node. It won’t automatically move existing pods back; you may need to manually restart or reschedule pods if desired. Since the node now has more available resources, Kubernetes will attempt to schedule new pods there to balance the load across the cluster.
Backup and restore of persistent volumes
The Longhorn storage driver, which provides the persistent storage used in the cluster, (See the Storage Guide for more details) provides built-in mechanisms for backup, restore, and snapshotting volumes. This can be performed entirely from within the Longhorn WebUI. See the relevant section of the Storage Guide for details on accessing that UI, since it requires setting up a port forward, which is described there.
See the relevant Longhorn Documentation for how to configure Longhorn and to manage Snapshotting and Backup and Restore.
1.3.10 - Releases
1.3.10.1 - Release esb3027-1.4.1
Build date
2025-11-25
Release status
Type: production
Included components
- ACD Configuration GUI 3.2.10
Compatibility
This release has been tested with the following product versions:
- AgileTV CDN Director, ESB3024-1.22.0
- AgileTV CDN Director, ESB3024-1.20.1 (without GUI)
Breaking changes from previous release
None
Change log
- NEW: Enable the horizontal pod autoscaler by default [ESB3027-354]
- FIXED: Authentication failure when using local DNS records [ESB3027-299]
- FIXED: PostgreSQL container image missing from installer [ESB3027-312]
- FIXED: Kafka messages are retained longer than configured [ESB3027-315]
- FIXED: Busybox container image missing from installer [ESB3027-317]
- FIXED: Prometheus scrape configuration uses wrong target URLs [ESB3027-324]
- FIXED: Grafana datasource connection invalid [ESB3027-325]
- FIXED: Incorrect Grafana dashboard used as Home [ESB3027-346]
- FIXED: Grafana exposes user credentials over plain HTTP [ESB3027-347]
- FIXED: Grafana pods crash and restart after a few minutes [ESB3027-353]
- FIXED: Default kafka volume is too small [ESB3027-357]
Deprecated functionality
None
System requirements
Known limitations
This release requires a clean install. Upgrade from version 1.4.0 is not possible. Installation of the software is only supported using a self-hosted configuration.
1.3.10.2 - Release esb3027-1.4.0
Build date
2025-10-23
Release status
Type: production
Included components
- ACD Configuration GUI 2.3.9
Compatibility
This release has been tested with the following product versions:
- AgileTV CDN Director, ESB3024-1.22.0
Breaking changes from previous release
A full installation is required for this version
If the field confd.confd.image.tag is set in the present configuration file it must be removed or updated before upgrading
Change log
- NEW: Monitoring and Metrics support [ESB3027-17]
- NEW: Support for horizontal scaling [ESB3027-63]
- NEW: Deploy GUI container with Manager [ESB3027-67]
- NEW: Support Kafka redundancy [ESB3027-125]
- NEW: Support for Redis high availability [ESB3027-126]
- NEW: Add Prometheus Container [ESB3027-130]
- NEW: Add Grafana Container [ESB3027-131]
- NEW: External DNS Name configuration should be global [ESB3027-180]
- NEW: Deploy hardware metrics services acd-metrics-aggregator and acd-telegraf-metrics-database in k8s cluster [ESB3027-189]
- NEW: REST API Performance Improvements [ESB3027-208]
- NEW: “Star”/Make a Grafana dashboard the home page [ESB3027-243]
- NEW: Support for remote TCP connections for confd subscribers [ESB3027-244]
- NEW: Persist long term usage data [ESB3027-248]
- NEW: New billing dashboard [ESB3027-249]
- NEW: [ANSSI-BP-028] System Settings - Network Configuration and Firewalls [ESB3027-258]
- NEW: [ANSSI-BP-028] System Settings - SELinux [ESB3027-260]
- NEW: Support deploying GUI independently from manager [ESB3027-278]
- NEW: Automatically generate Zitadel secret [ESB3027-280]
- NEW: Deprecate the generate-ssl-secret command [ESB3027-281]
- NEW: Deprecate the generate-zitadel-mastekey command [ESB3027-285]
- FIXED: Access to services restricted with SELinux in Enforcing mode [ESB3027-32]
- FIXED: Authentication token payload contains invalid user details [ESB3027-47]
- FIXED: Unexpected 200 OK response to non-existent confd endpoint [ESB3027-154]
- FIXED: Multiple restarts encountered for selection-input service on startup [ESB3027-155]
- FIXED: Installer script requires case-sensitive hostnames [ESB3027-158]
- FIXED: Installer script does not support configuring additional options [ESB3027-214]
- FIXED: Selection input API accepts keys containing non-urlsafe characters [ESB3027-216]
- FIXED: Installation fails on minimal RHEL installation [ESB3027-287]
- FIXED: Kafka consumer configuration warning logged on startup [ESB3027-294]
Deprecated functionality
None
System requirements
Known limitations
Installation of the software is only supported using a self-hosted configuration.
1.3.10.3 - Release esb3027-1.2.1
Build date
2025-05-22
Release status
Type: production
Compatibility
This release is compatible with the following product versions:
- AgileTV CDN Director, ESB3024-1.20.1
Breaking changes from previous release
None
Change log
- FIXED: Installer changes ownership of /var, /etc/ and /usr [ESB3027-146]
- FIXED: K3s installer should not be left on root filesystem [ESB3027-149]
Deprecated functionality
None
System requirements
- A minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
Installation of the software is only supported using a self-hosted configuration.
1.3.10.4 - Release esb3027-1.2.0
Build date
2025-05-14
Release status
Type: production
Compatibility
This release is compatible with the following product versions:
- AgileTV CDN Director, ESB3024-1.20.1
Breaking changes from previous release
None
Change log
- NEW: Remove
.shextension from all scripts on the ISO [ESB3027-102] - NEW: The script
load-certificates.shshould be calledgenerate-ssl-secret[ESB3027-104] - NEW: Add support for High Availability [ESB3027-108]
- NEW: Enable the K3s Registry Mirror [ESB3027-110]
- NEW: Support for Air-Gapped installations [ESB3027-111]
- NEW: Basic hardware monitoring support for nodes in K8s Cluster [ESB3027-122]
- NEW: Separate docker containers from ISO [ESB3027-124]
- FIXED: GUI is unable to make DELETE request on api/v1/selection_input/modules/blocked_referrers [ESB3027-112]
Deprecated functionality
None
System requirements
- A minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
Installation of the software is only supported using a self-hosted configuration.
1.3.10.5 - Release esb3027-1.0.0
Build date
2025-04-17
Release status
Type: production
Compatibility
This release is compatible with the following product versions:
- AgileTV CDN Director, ESB3024-1.20.0
Breaking changes from previous release
None
Change log
This is the first production release
Deprecations from previous release
None
System requirements
- A minimum CPU architecture level of x86-64-v2 due to inclusion of Oracle Linux 9 inside the container. While all modern CPUs support this archetecture level, virtual hypervisors may default to a CPU type that has more compatibility with older processors. If this minimum CPU architecture level is not attained the containers may refuse to start. See Operating System Compatibility and Building Red Hat Enterprise Linux 9 for the x86-64-v2 Microarchitecture Level for more information.
Known limitations
Installation of the software is only supported using a self-hosted, single-node configuration.
1.3.11 - API Guides
1.3.11.1 - Healthcheck API
This API provides endpoints to verify the liveness and readiness of the service.
Liveness Check
Endpoint:GET /api/v1/health/alive
Purpose:
Ensures that the service is running and accepting connections. This check does not verify
dependencies or internal health, only that the service process is alive and listening.
Response:
- Success (200 OK):
{
"status": "ok"
}
- Failure (503 Service Unavailable):
Indicates the service is not alive, possibly due to a critical failure.
Example Request
GET /api/v1/health/alive HTTP/1.1
Host: your-host
Accept: */*
Example Response
HTTP/1.1 200 OK
Content-Type: application/json
{
"status": "ok"
}
Readiness Check
Endpoint:GET /api/v1/health/ready
Purpose:
Verifies if the service is ready to handle requests, including whether all dependencies (such as
databases or external services) are operational.
Response:
- Success (200 OK):
{
"status": "ok"
}
- Failure (503 Service Unavailable):
Indicates the service or its dependencies are not yet ready.
Example Request
GET /api/v1/health/ready HTTP/1.1
Host: your-host
Accept: */*
Example Response
HTTP/1.1 200 OK
Content-Type: application/json
{
"status": "ok"
}
Notes
- These endpoints are typically used by load balancers, orchestrators like Kubernetes, or monitoring systems to assess service health.
- The liveness endpoint confirms the process is running; the readiness endpoint confirms the service and its dependencies are fully operational and ready to serve traffic.
1.3.11.2 - Authentication API
The manager offers a simplified authentication and authorization API that integrates with the Zitadel IAM system. This flow is a streamlined custom OAuth2-inspired process:
Session Establishment:
Users authenticate by sending their credentials to the Login endpoint, which returns a session ID and session token.Token Exchange:
The session token is exchanged for a short-lived, signed JWT access token via the Token Grant flow. This access token can be used to authorize API requests, and its scopes determine what resources and actions are permitted. The token should be protected, as it grants the bearer the rights specified by its scopes as long as it is valid.
Login
Send user credentials to initiate a session:
POST /api/v1/auth/login HTTP/1.1
Accept: application/json, */*;q=0.5
Content-Type: application/json
Host: localhost:4464
{
"email": "test@example.com",
"password": "test"
}
Response:
{
"expires_at": "2025-01-29T15:49:47.062354+00:00",
"session_id": "304646367786041347",
"session_token": "12II6yYYfN8UJ5ij-bac6IRRXX6t9qG_Flrlow_fukXKqvo9HFDVZ7a76Exj7Gn-uVRx04_reCaXew",
"verified_at": "2025-01-28T15:49:47.054169+00:00"
}
Logout
To terminate a session, send:
POST /api/v1/auth/logout HTTP/1.1
Accept: application/json
Content-Type: application/json
Host: localhost:4464
{
"session_id": "304646367786041347",
"session_token": "12II6yYYfN8UJ5ij-bac6IRRXX6t9qG_Flrlow_fukXKqvo9HFDVZ7a76Exj7Gn-uVRx04_reCaXew"
}
Response:
{
"status": "Ok"
}
Token Grant
After establishing a session, exchange the session token for a short-lived access token:
POST /api/v1/auth/token HTTP/1.1
Accept: application/json
Content-Type: application/json
Host: localhost:4464
{
"grant_type": "session",
"scope": "foo bar baz",
"session_id": "304646818908602371",
"session_token": "wfCelUhfSb4DKJbLCwg9dr59rTeaC13LF2TXH1tMqXz68ojL8LE9M-dCcwsKgrwjcXkjj9y49wWvdQ"
}
Note: The scope parameter is a space-delimited string defining the permissions requested. The
API responds with an access token, which is a JWT that contains embedded scopes and other claims,
and must be kept secret.
Response example:
{
"access_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJFUzI1NiIsImp3ayI6eyJ1c2UiOiJzaWciLCJhbGciOiJFUzI1NiIsImtpZCI6ImFjZC1tYW5hZ2VyLWVzMjU2LWtleSIsImt0eSI6IkVDIiwiY3J2IjoiUC0yNTYiLCJ4IjoiWWxpYVVoSXpnaTk1SjV4NXdaU0tGRUhyWldFUTdwZDZUR2JrTEN6MGxLcyIsInkiOiJDcWNWY1MzQ1pFMjB2enZiWFdxRERRby00UXEzYnFfLUlPZWNPMlZudkFzIn0sImtpZCI6ImFjZC1tYW5hZ2VyLWVzMjU2LWtleSJ9.eyJleHAiOjE3MzgwODAwMjIsImlhdCI6MTczODA3OTcyMiwibmJmIjoxNzM4MDc5NzIyLCJzdWIiOiJ0ZXN0QGV4YW1wbGUuY29tIiwiZ2l2ZW5fbmFtZSI6IiIsImZhbWlseV9uYW1lIjoiVGVzdCBVc2VyIiwiZW1haWwiOiJ0ZXN0QGV4YW1wbGUuY29tIiwic2NvcGUiOiJmb28gYmFyIGJheiJ9.uRmmszZfkrbJpQxIRpxmHf4gL6omvsOQHeuQYd00Bj8PNwQejNA2ZJO3Q_PsE0qb1IrMX5bsCC_k9lWUFMNQ1w",
"expires_in": 300,
"scope": "foo bar baz",
"token_type": "bearer"
}
The access token can then be included in API requests via the Authorization header as Bearer <token>.
1.3.11.3 - Router API
The /api/v1/routing/validate endpoint evaluates routing rules for a specified IP
address. If the IP is blocked according to the configured rules, the endpoint
responds with a 401 Unauthorized.
Limitations
- Supported Classifier Types: Only classifiers of type GeoIP, Anonymous IP, and IPRange are supported. Other classifiers require additional information which is not available to the Manager, so they are assumed not to match.
- Policy Behavior: Since the exact path taken through the rules during the initial
request is unknown, a “default allow” policy is in effect. This means that unless
an IP explicitly matches a rule that denies it, the response will be
200 OK, indicating the IP is allowed.
Request
Method:GET /api/v1/routing/validate?ip=<IP_ADDRESS>
Headers:
Accept: */* (or as needed)
Example:
GET /api/v1/routing/validate?ip=1.1.1.1 HTTP/1.1
Accept: */*
Host: localhost
User-Agent: HTTPie/3.2.4
Response
- Blocked IP:
Returns401 Unauthorizedif the IP matches a block rule.
HTTP/1.1 401 Unauthorized
- Allowed IP:
Returns200 OKif the IP does not match a block rule (or if no matching rule is found due to the “default allow” policy).
HTTP/1.1 200 OK
Default-Allow Policy
The routing validation API uses a default-allow policy: if a request does not match any rule, it is allowed. This approach is intentional and designed to prevent valid sessions from being accidentally dropped if your configuration uses advanced features or rule types that are not fully supported by the Manager. Since the Manager only supports a subset of all possible classifier types and rule logic, it cannot always determine the exact path a request would take through the full configuration. By defaulting to allow, the system avoids inadvertently blocking legitimate traffic due to unsupported or unrecognized configuration elements.
To ensure sensitive or restricted IPs are blocked, you must add explicit deny
rules at the top of your ruleset. Rules are evaluated in order, and the first match
applies.
Best Practice: Place your most specific
denyrules first, followed by generalallowrules. This ensures that deny conditions are always checked before any allow conditions.
Example Ruleset (confd/confcli syntax)
{
"rules": [
{
"name": "deny-restricted",
"type": "deny",
"condition": "in_session_group('Restricted')",
"onMiss": "allow-general"
},
{
"name": "allow-general",
"type": "allow",
"condition": "always()",
"onMatch": "main-host"
}
]
}
- The first rule denies requests from the
Restrictedsession group. - The second rule allows all other requests.
Note: With a default-allow policy, any request not explicitly denied will be permitted. Always review your ruleset to ensure that deny rules are comprehensive and prioritized.
1.3.11.4 - Selection Input API
This API allows you to store arbitrary JSON data in synchronization across all Director instances via Kafka. It is based on the Selection Input API provided by the Director. You can create, delete, and fetch selection input entries at arbitrary paths.
Known Limitations
- Parent Path Access: Accessing a parent path (e.g.,
/foo) will not return all nested structures under that path. - Field Access Limitation: It is not possible to query nested fields directly. For example, if
/foo/barcontains{"baz": {"bam": "boom"}}, querying/foo/bar/baz/bamwill not return"boom". You can only query/foo/bar/bazto retrieve{"bam": "boom"}.
API Usage
Create New Keys
Create multiple entries under a specified path by POSTing a JSON object where each key-value pair corresponds to a key and its associated data.
Request:
POST /api/v1/selection_input/<path>
Body Example:
{
"key1": {...},
"key2": {...}
}
Example:
POST to /api/v1/selection_input/modules/keys with the above body creates:
/modules/keys/key1with value{...}/modules/keys/key2with value{...}
Delete a Key
Remove a specific key at a given path.
Request:
DELETE /api/v1/selection_input/<path>/<key>
Example:
To delete key2 under /modules/keys:
DELETE /api/v1/selection_input/modules/keys/key2
Fetch a Key
Retrieve the data stored under a specific key.
Request:
GET /api/v1/selection_input/<path>/<key>
Example:
To fetch key1 under /modules/keys:
GET /api/v1/selection_input/modules/keys/key1
Response:
{
"key1": {...}
}
Fetch All Keys Under a Path
Retrieve all selection input data stored under a parent path.
Request:
GET /api/v1/selection_input/<path>
Example:
To get all keys under /modules/keys:
GET /api/v1/selection_input/modules/keys
Response:
{
"key1": {...},
"key2": {...}
}
Filtering, Sorting, and Limiting Results
You can refine the list of keys returned by adding query parameters:
search=<string>: Filter results to include only keys matching the search string.sort=<asc|desc>: Sort keys in ascending or descending order before filtering.limit=<number>: Limit the number of results returned (positive integer).
Note:
- Sorting occurs prior to filtering and limiting.
- The order of query parameters does not affect the request.
Example:
GET /api/v1/selection_input/modules/keys?search=foo&sort=asc&limit=10
1.3.11.5 - Operator UI API
This API provides endpoints to retrieve and manage blocked tokens, user agents, and referrers used within the Operator UI.
Endpoints
Retrieve List of Blocked Tokens
GET /api/v1/operator_ui/modules/blocked_tokens/
Fetches a list of blocked tokens, supporting optional filtering, sorting, and limiting.
Query Parameters:
search(optional): Filter tokens matching the search term.limit(optional): Limit number of results.sort(optional): Sort order,"asc"or"desc"(default:"asc").
Responses:
200 OKwith JSON array of blocked tokens.404 Not Foundif no tokens found.500 Internal Server Erroron failure.
Retrieve a Specific Blocked Token
GET /api/v1/operator_ui/modules/blocked_tokens/{token}
Fetches details of a specific blocked token.
Path Parameter:
token: The token string to retrieve.
Responses:
200 OKwith JSON object of the token.404 Not Foundif token does not exist.500 Internal Server Erroron failure.
Retrieve List of Blocked User Agents
GET /api/v1/operator_ui/modules/blocked_user_agents/
Fetches a list of blocked user agents, with optional sorting and limiting.
Query Parameters:
limit(optional): Limit number of results.sort(optional):"asc"or"desc"(default:"asc").
Responses:
200 OKwith JSON array of user agents.404 Not Foundif none found.500 Internal Server Erroron failure.
Retrieve a Specific Blocked User Agent
GET /api/v1/operator_ui/modules/blocked_user_agents/{user_agent}
Retrieves details of a specific blocked user agent.
Path Parameter:
user_agent: URL-safe Base64 encoded string (without padding). Decode before use; if decoding fails, the server returns400 Bad Request.
Responses:
200 OKwith JSON object of the user agent.404 Not Foundif not found.500 Internal Server Erroron failure.
Retrieve List of Blocked Referrers
GET /api/v1/operator_ui/modules/blocked_referrers/
Fetches a list of blocked referrers, with optional sorting and limiting.
Query Parameters:
limit(optional): Limit number of results.sort(optional):"asc"or"desc"(default:"asc").
Responses:
200 OKwith JSON array of referrers.404 Not Foundif none found.500 Internal Server Erroron failure.
Retrieve a Specific Blocked Referrer
GET /api/v1/operator_ui/modules/blocked_referrers/{referrer}
Retrieves details of a specific blocked referrer.
Path Parameter:
referrer: URL-safe Base64 encoded string (without padding). Decode before use; if decoding fails, return400 Bad Request. The response includes the decoded referrer.
Responses:
200 OKwith JSON object containing the referrer.404 Not Foundif not found.500 Internal Server Erroron failure.
Additional Notes
- For User Agents and Referrers, the path parameters are URL-safe Base64 encoded (per RFC 4648,
using
-and_instead of+and/) with padding (=) removed. Clients should remove padding when constructing requests and restore it before decoding. - All endpoints returning specific items will respond with
404 Not Foundif the item does not exist. - Errors during processing will return
500 Internal Server Errorwith an error message.
1.3.12 - Use Cases
1.3.12.1 - Custom Deployments
In some environments, it may not be necessary to run all components of the ESB3027 AgileTV CDN Manager—such as when certain features are not used, or when components like the MIB Frontend Configuration GUI are hosted separately, for example, in a public cloud environment. The examples in this guide illustrate scenarios and the configuration properties needed to achieve specific configurations.
Manager Without Metrics and Monitoring Support
If metrics and monitoring are not required—perhaps because an existing monitoring solution is in place—it is possible to disable the deployment of Telegraf, Prometheus, Grafana, and VictoriaMetrics. You can choose to skip the entire metrics suite or disable individual components as needed.
Keep in mind, that disabling certain components may require adjustments elsewhere in the configuration. For example, disabling Prometheus will necessitate modifications to Grafana and VictoriaMetrics configurations, since they depend on Prometheus being available.
To disable all metrics components, set:
acd-metrics.enabled: false
Applying this configuration will prevent the deployment of the entire metrics suite. To disable
individual components within the metrics framework, set their respective enabled flags to false.
For example, to disable only Grafana but keep other metrics components active:
acd-metrics.grafana.enabled: false
Manager Without the MIB Frontend Configuration GUI
If the MIB-Frontend GUI will not be used to configure the ESB3024 AgileTV CDN Director instances, this component can be disabled by setting:
mib-frontend.enabled: false
This is also useful if the frontend is hosted in a separate cluster—such as in a public cloud like AWS —or if the manager is deployed within a customer’s network without the frontend.
1.3.13 - Common Issues
Installation
AttachVolume.Attach failed for volume…
When describing a pod that fails to deploy, the message “AttachVolume.Attach failed for volume … is not ready for workloads” may appear in the event log.
This means that the Persistent Volume Claim was created but unable to be successfully mounted in the pod. This is typically caused by a network issue, as Longhorn requires both iSCSI and NFS to work.
Also ensure that Longhorn is healthy and that the correct storage class is configured for your Persistent Volume Claims.
Check the firewall to ensure that the proper ports have been opened. See the Networking Guide for details.
1.3.14 - Troubleshooting Guide
This guide helps diagnose common issues with the acd-manager deployment and its associated pods.
1. Check Pod Status
Verify all pods are running:
kubectl get pods
Expected:
- Most pods should be in
Runningstate withREADYas1/1or2/2. - Pods marked as
0/1or0/2are not fully ready, indicating potential issues.
2. Investigate Unready or Failed Pods
Example:
kubectl describe pod acd-manager-6c85ddd747-rdlg6
- Look for events such as
CrashLoopBackOff,ImagePullBackOff, orErrImagePull. - Check container statuses for error messages.
3. Check Pod Logs
Fetch logs for troubleshooting:
kubectl logs acd-manager-6c85ddd747-rdlg6
- For pods with multiple containers:
kubectl logs acd-manager-<pod_name> -c <container_name>
- Focus on recent errors or exceptions.
4. Verify Connectivity and Dependencies
- PostgreSQL: Confirm the
acd-cluster-postgresql-0pod is healthy and accepting connections. - Kafka: Check
kafka-controllerpods are running and not experiencing issues. - Redis: Ensure Redis master and replicas are healthy.
- Grafana, Prometheus, VictoriaMetrics: Confirm these services are operational.
5. Check Resource Usage
High CPU or memory can cause pods to crash or become unresponsive:
kubectl top pods
Actions:
- Scale resources if needed.
- Review resource quotas and limits.
6. Check Events in Namespace
kubectl get events --sort-by='.lastTimestamp'
- Look for warnings or errors related to pod scheduling, network issues, or resource constraints.
7. Restart Problematic Pods
Sometimes, restarting pods can resolve transient issues:
kubectl delete pod <pod_name>
Kubernetes will automatically recreate the pod.
8. Verify Configurations and Secrets
- Check ConfigMaps and Secrets for correctness:
kubectl get configmaps
kubectl get secrets
- Confirm environment variables and mounted volumes are correctly configured.
9. Check Cluster Network
- Ensure network policies or firewalls are not blocking communication between pods and external services.
10. Additional Tips
- Upgrade or Rollback: If recent changes caused issues, consider rolling back or upgrading the deployment.
- Monitoring: Use Grafana and VictoriaMetrics dashboards for real-time insights.
- Documentation: Consult application-specific logs and documentation for known issues.
Summary Table
| Issue Type | Common Checks | Commands |
|---|---|---|
| Pod Not Ready | Describe pod, check logs | kubectl describe pod, kubectl logs |
| Connectivity | Verify service endpoints | kubectl get svc, curl from within pods |
| Resource Limits | Monitor resource usage | kubectl top pods |
| Events & Errors | Check cluster events | kubectl get events |
| Configuration | Validate configs and secrets | kubectl get configmaps, kubectl get secrets |
If issues persist, consider scaling down and up components or consulting logs and metrics for deeper analysis.
1.3.15 - Glossary
- Access Token
- A credential used to authenticate and authorize access to resources or APIs on behalf of a user, usually issued by an authorization server as part of an OAuth 2.0 flow. It contains the necessary information to verify the user’s identity and define the permissions granted to the token holder.
- Bearer Token
- A type of access token that allows the holder to access
protected resources without needing to provide additional
credentials. It’s typically included in the HTTP Authorization
header as
Authorization: Bearer <token>, and grants access to any resource that recognizes the token. - Chart
- A Helm Chart is a collection of files that describe a related set of Kubernetes resources required to deploy an application, tool, or service. It provides a structured way to package, configure, and manage Kubernetes applications.
- Cluster
- A group of interconnected computers or nodes that work together as a single system to provide high availability, scalability and redundancy for applications or services. In Kubernetes, a cluster usually consists of one primary node, and multiple worker or agent nodes.
- Confd
- An AgileTV backend service that hosts the service configuration. Comes with an API, a CLI and a GUI.
- ConfigMap (Kubernetes)
- A Kubernetes resource used to store non-sensitive configuration data in key-value pairs, allowing applications to access configuration settings without hardcoding them into the container images.
- Containerization
- The practice of packaging applications and their dependencies into lightweight portable containers that can run consistently across different computing environments.
- Deployment (Kubernetes)
- A resource object that provides declarative updates to applications by managing the creation and scaling of a set of Pods.
- Director
- The AgileTV Delivery OTT router and related services.
- ESB
- A software bundle that can be separately installed and upgraded, and is released as one entity with one change log. Each ESB is identified with a number. Over time, features and functions within an ESB can change.
- Helm
- A package manager for Kubernetes that simplifies the development and management of applications by using pre-configured templates called charts. It enables users to define, install, and upgrade complex applications on Kubernetes.
- Ingress
- A Kubernetes resource that manages external access to services within a cluster, typically HTTP. It provides routing rules to manage traffic to various services based on hostnames and paths.
- K3s
- A lightweight Kubernetes cluster developed by Rancher Labs. This is a complete Kubernetes system deployed as a single portable binary.
- K8s
- A common abbreviation for Kubernetes.
- Kafka
- Apache Kafka is an open-source distributed event streaming platform designed for building real-time data pipelines and streaming applications. It enables the publication, subscription, storage, and processing of streams of records in a fault-tolerant and scalable manner.
- Kubectl
- The command-line tool for interacting with Kubernetes clusters, allowing users to deploy applications, manage cluster resources, and inspect logs or configurations.
- Kubernetes
- An open-source container orchestration platform designed to automate scaling, and management of containerized applications. It enables developers and operations teams to manage complex applications consistently across various environments.
- LoadBalancer
- A networking tool that distributes network traffic across multiple servers or Pods to ensure no single server becomes overwhelmed, improving reliability and performance.
- Manager
- The AgileTV Management Software and related services.
- Namespace
- A mechanism for isolating resources within a Kubernetes cluster, allowing multiple teams or applications to coexist without conflict by providing a scope for names.
- OAuth2
- An open standard for authorization that allows third-party applications to gain limited access to a user’s resources on a server without exposing the user’s credentials.
- Pod
- The smallest deployable unit in Kubernetes that encapsulates one or more containers, sharing the same network and storage resources. It serves as a logical host for tightly coupled applications, allowing them to communicate and function effectively within a cluster.
- Router
- Unless otherwise specified, an HTTP router that manages an OTT session using HTTP redirect. There are also ways to use DNS instead of HTTP.
- Secret (Kubernetes)
- A resource used to store sensitive information, such as passwords, API keys, or tokens in a secure manner. Secrets are encoded in base64 and can be made available to Pods as environment variables or mounted as files, ensuring that sensitive data is not exposed in the application code or configuration files.
- Service (Kubernetes)
- An abstraction that defines a logical set of Pods and a policy to access them, enabling stable networking and load balancing to ensure reliable communication among application components.
- Session Token
- A session token is a temporary, unique identifier generated by a server and issued to a user upon successful authentication.
- Stateful Set (Kubernetes)
- A Kubernetes deployment which guarantees ordering and uniqueness of Pods, typically used for applications that require stable network identities and persistent storage such as with databases.
- Topic (Kafka)
- A category or feed name to which records (messages) are published. Messages flow through a topic in the order in which they are produced, and multiple consumers can subscribe to the stream to process the records in real time.
- Volume (Kubernetes)
- A persistent storage resource in Kubernetes that allows data to be stored and preserved beyond the lifecycle of individual Pods, facilitating data sharing and durability.
- Zitadel
- An open-source identity and access management (IAM) platform designed to handle user authentication and authorization for applications. It provides features like single-sign-on (SSO), multi-factor authentication (MFA), and support for various authentication protocols.
1.4 - AgileTV Cache (esb2001,esb3004)
Information about the AgileTV Cache Orbit version is available in
EDGS-103 Orbit TV Server User Guide1 and information about the
AgileTV Cache SW Streamer version is available in EDGS-171 SW Streamer User Guide1.
1.5 - BGP Sniffer (esb3013)
Information about the AgileTV BGP Sniffer is available in
EDGS-214 ESB3013 User Guide1.
1.6 - AgileTV Convoy Manager (classic) (esb3006)
Information about the classic Orbit CDN Management System (aka Convoy)
is available in EDGS-069 Convoy Management Software User Guide1.
1.7 - Orbit CDN Request Router (esb3008)
Information about the convoy based Orbit Request Router
is available in EDGS-197 ESB3008 HTTP Request Router - User Guide1.
2 - Introduction
AgileTV CDN Solutions is a software suite for CDNs (Content Delivery Networks). The services built around the software come into play when a user starts to view video content on a video streaming portal. The focus is on the server side of the delivery. The portal and players or set-to-boxes are not part of AgileTV CDN Solutions, although they are part of the AgileTV product portfolio as a whole. Likewise, video stream repackaging and DRM are not part of AgileTV CDN Solutions (see AgileTV Origin & Media Server).
The software can be used to build a complete private CDN and/or to select between CDNs. A typical deployment is a nation-wide TV streaming service operated by a telecom operator or a broadcaster.
At the core of the system sits the AgileTV CDN Director which will process an incoming client request and make an optimized decision from where to serve the user. The CDN Director will classify each playback request according to a variety of configured parameters such as device type, geographic region or content class. Based on the classification together with the current state of the network, its streaming capacity and public offload CDNs status, the best streaming location is determined. If desired, business rules for when to use public CDNs can be applied.
The software suite includes the AgileTV Cache that is installed on servers placed in data centers that will guarantee an efficient and robust distribution of the content. Depending on the core network architecture, a centralized or decentralized approach is best. AgileTV can help find a good system solution.
Behind the client facing interfaces, there are backend services to monitor and measure the system. This information can be used to troubleshoot network problems, analyze viewing patterns or to plan upgrades of capacity.
Returning to the CDN Director, it is built around a very flexible routing rule evaluation engine that can route between and within CDNs. The rule evaluation engine weighs together multiple sources of information to optimize system behavior. Apart from the request classification of device type, content class etc, there are also several integration APIs that can be used to extend the product and solve problems that are particular to a specific customer. One of those integration APIs is the Selection Input API which can take any external information such as streaming bitrate of public CDNs, load balancing settings from a GUI slide bar or status from network probes and include it in the routing decision rules. Another is the Subnet API that can efficiently handle thousands of subnets and map each one to a high-level group membership (typically a region) and route based on that. There is also a metrics API to monitor the service. It integrates out-of-the-box with Prometheus and Grafana.
All APIs are documented under the API overview.
In addition to the flexibility provided by the APIs, there is also a possibility to extend functionality via plugins (using Lua). This can be used to support the decoding and encoding of security tokens (digital signatures of the URLs) or advanced routing rules that are not available out-of-the-box.
A modern TV CDN is considered as critical infrastructure and has very high requirements on uptime and robustness. This is in obtained via multiple independent and stand-alone instances of each service (although particular use cases might require sharing data via a redundant database). The software services run on RHEL8 or RHEL9 Linux or compatible distributions such as Oraclelinux.
Note: Not all products or components that are part of AgileTV CDN Solutions are documented here. Please contact our Sales for a complete overview.
3 - Solutions
3.1 - Cache hardware metrics: monitoring and routing
Observability and monitoring is important in a CDN. To facilitate this, we use the open source application Telegraf as an agent on the caches to collect metrics, such as CPU usage, memory usage, and network interface statistics.
These metrics can be exported to two services installed alongside the Director:
acd-metrics-aggregator: aggregates cache metrics from the CDN and exports them to the Director’s selection input API.acd-telegraf-metrics-database: stores a smaller amount of time-series cache metrics produced by Telegraf metrics agents and allows the metrics to be scraped by a Prometheus instance, enabling alarms and visualization of the metrics in Grafana.
Telegraf Metrics Agent
All deployments of ESB2001 Orbit TV Server (from version 3.6.2) and ESB3004 SW Streamer (from version 1.36.2) come bundled with an instance of Telegraf running as a metrics agent. If you are using other caches in your CDN, it is possible to install and configure Telegraf manually, if licensing allows and the caches are accessible.
Configuring Telegraf is done using the confcli tool. Before configuration,
ensure that the service telegraf-configd is active by running
systemctl status telegraf-configd
systemctl restart telegraf-configd # if the service is not active
If telegraf-configd fails to start, check the log file /var/log/telegraf-configd.log
for errors.
Configuration
Once the configuration daemon is running, Telegraf can be configured using
confcli:
$ confcli integration.acd.telegraf
{
"telegraf": {
"aggregators": [],
"databases": [],
"enable": true,
"enable_tls_verification": true,
"hostname": "",
"interfaces": [],
"pushInterval": 5,
"secrets": {
"enable": false,
"key": "metrics_auth_token",
"secretStoreID": "telegraf_configd_secretstore"
}
}
}
The configuration fields are:
aggregators: a list of URLs toacd-metrics-aggregatorinstances to which the metrics will be exported.databases: a list of URLs toacd-telegraf-metrics-databaseinstances to which the metrics will be exported.enable: whether the Telegraf instance is enabled or not.enable_tls_verification: whether to verify the TLS certificate of the target when exporting metrics.hostname: the hostname of the cache. This is used as a tag in the metrics. If not set, the hostname of the machine is used.interfaces: a list of network interfaces to collect metrics from. Supports wildcards, e.g.eths*.pushInterval: the interval in seconds for pushing metrics to targets.secrets: configuration for using a secret token to authenticate with the targets.secrets.enable: sets the headerAuthorization: Token secret_valuewhen exporting metrics to the targets.secrets.key: the key/name of the secret. Defaults tometrics_auth_token.secrets.secretStoreID: the ID of the secret store to use. Defaults totelegraf_configd_secretstore.
Targets
acd-metrics-aggregator
acd-metrics-aggregator is a service that aggregates cache metrics in the CDN and
exports them to the Director’s selection input API.
The service is installed alongside the Director.
The service is started by default after installation. You can check the status of the service by running
systemctl status acd-metrics-aggregator
systemctl restart acd-metrics-aggregator # if the service is not active
The logs are accessed by running
journalctl -u acd-metrics-aggregator
The configuration file for the aggregator is located at
/opt/edgeware/acd/metrics/aggregator-conf.json. The default configuration
created during installation will export metrics to the local Director’s
selection input API:
{
"tls_cert": "",
"tls_key": "",
"metrics_listen_port": 8087,
"interval": 5,
"log_level": "INFO",
"targets": [
{
"url": "https://127.0.0.1:5001/v1/timestamped_selection_input",
"http_headers": {
"x-api-key": "8a3094e875b841d480482cfd82e3e313"
}
}
],
"secrets": {
"enable": false,
"key": "metrics_auth_token"
}
}
The configuration fields are:
tls_cert: the path to the TLS certificate file ifacd-metrics-aggregatorshould use TLS.tls_key: the path to the TLS key file ifacd-metrics-aggregatorshould use TLS.- Note that the service is run as a container with the directory
/opt/edgeware/acd/sslmounted as a volume with the same path in the container. The certificate and key files should be placed in this directory.
- Note that the service is run as a container with the directory
metrics_listen_port: the port on which the service listens for metrics.interval: the interval in seconds for pushing metrics to the targets.log_level: the log level for the aggregator. Can beDEBUG,INFOorWARNING.targets: a list of targets to which the metrics will be exported.url: the URL of the target.http_headers: HTTP headers to send with the request.x-api-key: the API key for the Director’s REST API. Populated by default.
secrets: configuration for using secret token to authenticate incoming metrics requests.enable: requires the headerAuthorization: Token secret_valuewhen receiving metrics.key: the key/name of the secret. Defaults tometrics_auth_token.
acd-telegraf-metrics-database
acd-telegraf-metrics-database is a service that stores cache metrics in a time
series database to be scraped by a Prometheus instance, allowing for alarms and
vizualization of the metrics in Grafana. The service is installed alongside the
Director.
This service is running Telegraf in a container, receiving metrics from the Telegraf metrics agents. Note that this service is not a full-fledged time series database, like InfluxDB, but a smaller database that stores a limited amount of data. The service acts like a middle man between the Telegraf metrics agents and the scraping Prometheus instance.
The service is started by default after installation. You can check the status of the service by running
systemctl status acd-telegraf-metrics-database
systemctl restart acd-telegraf-metrics-database # if the service is not active
The logs are accessed by running
journalctl -u acd-telegraf-metrics-database
The configuration file for the database is located at
/opt/edgeware/acd/metrics/telegraf-metrics-database.conf:
# Global tags can be specified here in key="value" format.
[global_tags]
# Example configuration for aggregator
[agent]
interval = "5s" # Data collection interval
round_interval = true # Round collection interval to 'interval'
metric_batch_size = 1000 # Max metrics sent in one batch
metric_buffer_limit = 10000 # Max metrics stored when outputs are unavailable
collection_jitter = "0s" # Collection jitter to stagger collection times
flush_interval = "5s" # Metrics output interval
flush_jitter = "0s" # Output jitter to stagger output times
precision = "" # Timestamp precision in output
debug = false # Enable more log info for debugging
quiet = false # Enable less log info
logfile = "" # Log file path, empty means log to stderr
hostname = "" # Host identifier, empty means use os.Hostname()
omit_hostname = false # Include hostname in output
# Listen for Telegraf metrics agents
[[inputs.influxdb_v2_listener]]
service_address = ":8086"
# tls_cert = ""
# tls_key = ""
# token = "@{secretstore:metrics_auth_token}" # Uncomment this line to use token authentication
# Expose port for prometheus to scrape all metrics from
[[outputs.prometheus_client]]
listen = ":12001"
# Secretstore configuration
[[secretstores.docker]]
id = "secretstore"
See https://docs.influxdata.com/telegraf/v1/plugins/ for full plugin directory and plugin documentation. The important fields are:
inputs.influxdb_v2_listener: plugin that listens for incoming metrics from cache agents.service_address: the address and port to listen on.tls_cert: the path to the TLS certificate file if TLS should be used.tls_key: the path to the TLS key file if TLS should be used.- Note that the service is run as a container with the directory
/opt/edgeware/acd/sslmounted as a volume with the same path in the container. The certificate and key files should be placed in this directory.
- Note that the service is run as a container with the directory
token: the token to use for authentication. This field is commented out by default. Uncomment this line to use token authentication.
outputs.prometheus_client: opens a port for Prometheus to scrape metrics from.listen: the port to listen on.
secretstores.docker: plugin for using Podman secrets to authenticate incoming metrics.id: the ID of the secret store to use. Used in thetokenfield for theinputs.influxdb_v2_listenerplugin.
Using Secrets for Request Authorization
Secrets can be used to authenticate incoming metrics requests to
acd-metrics-aggregator and acd-telegraf-metrics-database by requiring the
header Authorization: Token secret_value when receiving metrics. The Telegraf
metrics agent can be configured to attach this header when exporting metrics to
acd-metrics-aggregator and acd-telegraf-metrics-database.
Cache Metrics Agent
The secret configuration on the Telegraf metrics agent can be seen by running
$ confcli integration.acd.telegraf.secrets
{
"secrets": {
"enable": false,
"key": "metrics_auth_token",
"secretStoreID": "telegraf_configd_secretstore"
}
}
To set the secret value with the key/name metrics_auth_token using the secret
store telegraf_configd_secretstore, run
$ telegraf secrets set telegraf_configd_secretstore metrics_auth_token
Enter secret value:
This will prompt you to enter the secret value. Once the secret value is set, the Telegraf metrics agent can use the secret to authenticate with the targets by running
$ confcli integration.acd.telegraf.secrets.enable true
integration.acd.telegraf.secrets.enable = True
This will set the header Authorization: Token secret_value when exporting
metrics to the configured targets.
Note that if you change the secret value, you need to restart the Telegraf metrics agent by either updating the configuration, e.g. disabling the service and enabling it again, or by running
systemctl restart telegraf
acd-metrics-aggregator and acd-telegraf-metrics-database
Both acd-metrics-aggregator and acd-telegraf-metrics-database use secrets
supplied by Podman to enable request authorization. During installation, a
placeholder secret is created with the name metrics_auth_token in Podman. This
secret is loaded into the respective containers when starting the services.
To securely set the secret value, the following commands will prompt you to
enter the secret value and store it in a temporary environment variable. The
secret value is then piped to podman to store the secret value. Lastly,
the environment variable is unset to ensure that the secret value is removed
from the environment:
read -sp "Enter secret value: " SECRET_VALUE
printf "$SECRET_VALUE" | podman secret create --replace metrics_auth_token -
unset SECRET_VALUE
This will set the secret value to secret-value.
Enabling Request Authorization
To use the secret for request authorization in acd-metrics-aggregator, modify
the secrets field in configuration file
/opt/edgeware/acd/metrics/aggregator-conf.json to:
{
"secrets": {
"enable": true,
"key": "metrics_auth_token"
}
}
Then restart the service:
systemctl restart acd-metrics-aggregator
To use the secret for request authorization in acd-telegraf-metrics-database,
modify the configuration file to use the secret by uncommenting the token
field in the inputs.influxdb_v2_listener plugin:
[[inputs.influxdb_v2_listener]]
service_address = ":8086"
token = "@{secretstore:metrics_auth_token}"
Make sure the secret store ID and secret key in the token field match the
values in the secretstores.docker section of the configuration file.
Then restart the service:
systemctl restart acd-telegraf-metrics-database
All incoming metrics requests to acd-metrics-aggregator and
acd-telegraf-metrics-database will now require the header
Authorization: Token secret_value, otherwise the request will be rejected.
Example
A Telegraf metrics agent can be configured to export metrics to a Director that
is installed on the host director-1 like this.
Assuming that acd-metrics-aggregator is listening on port 8087 and
acd-telegraf-metrics-database is listening on port 8086, the following
configuration will track the CPU usage, memory usage, and network interface
statistics for interfaces eths0 and eths1:
$ confcli integration.acd.telegraf.
{
"telegraf": {
"aggregators": [
"http://director-1:8087/metrics"
],
"databases": [
"http://director-1:8086"
],
"enable": true,
"enable_tls_verification": true,
"hostname": "cache-1",
"interfaces": [
"eths0",
"eths1"
],
"pushInterval": 5,
"secrets": {
"enable": false,
"key": "metrics_auth_token",
"secretStoreID": "telegraf_configd_secretstore"
}
}
}
Note that each entry in aggregators requires the path /metrics to be
appended to the URL. The entries in databases do not require any path to be
appended to the URL.
Once the configuration is set, the cache metrics agent will start exporting
metrics to the instances of acd-metrics-aggregator and
acd-telegraf-metrics-database running on director-1.
acd-metrics-aggregator will aggregate the metrics and export them to the
Director’s selection input API. The metrics can be viewed by running
curl -k https://director-1:5001/v1/selection_input -H "x-api-key: <your-api-key>"
{
"cache-1": {
"hardware_metrics": {
"/media": {
"free": 2247610073088,
"total": 2261300281344,
"used": 13690208256,
"used_percent": 0.6054131054131053
},
"/non-volatile": {
"free": 1722658816,
"total": 1934635008,
"used": 95219712,
"used_percent": 5.237957901662393
},
"/var/log": {
"free": 487481344,
"total": 536870912,
"used": 49389568,
"used_percent": 9.19952392578125
},
"cpu_load1": 0.07,
"cpu_load15": 0,
"cpu_load5": 0.03,
"ehsd_online": 1,
"mem_available": 7252512768,
"mem_available_percent": 88.21865022898756,
"mem_total": 8221065216,
"mem_used": 818151424,
"n_cpus": 4
},
"per_interface_metrics": {
"eths0": {
"bytes_recv": 155734911,
"bytes_recv_rate": 1552,
"bytes_sent": 2967510,
"bytes_sent_rate": 1378,
"drop_in": 843508,
"drop_in_rate": 7,
"drop_out": 0,
"drop_out_rate": 0,
"err_in": 0,
"err_in_rate": 0,
"err_out": 0,
"err_out_rate": 0,
"interface_up": true,
"link": 1,
"megabits_recv": 1245.879288,
"megabits_recv_rate": 0.012416,
"megabits_sent": 23.74008,
"megabits_sent_rate": 0.011024,
"speed": 10000,
"speed_rate": 0
},
"eths1": {
"bytes_recv": 66197103,
"bytes_recv_rate": 256.5,
"bytes_sent": 612,
"bytes_sent_rate": 0,
"drop_in": 3399,
"drop_in_rate": 0,
"drop_out": 0,
"drop_out_rate": 0,
"err_in": 0,
"err_in_rate": 0,
"err_out": 0,
"err_out_rate": 0,
"interface_up": true,
"link": 1,
"megabits_recv": 529.576824,
"megabits_recv_rate": 0.002052,
"megabits_sent": 0.004896,
"megabits_sent_rate": 0,
"speed": 10000,
"speed_rate": 0
}
}
}
}
acd-telegraf-metrics-database will store the metrics in a time series database
to be scraped by a Prometheus instance. The metrics can be scraped manually by
running
curl -k http://director-1:12001/metrics
# HELP disk_used_percent Telegraf collected metric
# TYPE disk_used_percent untyped
disk_used_percent{device="dm-0",fstype="xfs",host="cache-1",label="vg_main-lv_root",metric_owner="telegraf-configd",mode="rw",path="/"} 12.752679256881688
# HELP ehsd_ehsd_online Telegraf collected metric
# TYPE ehsd_ehsd_online untyped
ehsd_ehsd_online{host="cache-1",metric_owner="telegraf-configd"} 1
# HELP net_megabits_sent_rate Telegraf collected metric
# TYPE net_megabits_sent_rate untyped
net_megabits_sent_rate{host="cache-1",interface="eth0",metric_owner="telegraf-configd"} 0.002174
...
Using Hardware Metrics in Routing
When the hardware metrics have been succesfully injected into the selection input API, the data is ready to be used for routing decisions. In addition to creating routing conditions, hardware metrics are particularly suited to host health checks.
Host Health Checks
When the hardware metrics have been succesfully injected into the selection input API, the data is ready to make routing decisions with. In addition to creating routing conditions, hardware metrics are particularly suited to host health checks.
Host health checks are Lua functions that determine whether or not a host is ready to take on more clients. To configure host health checks, see configuring CDNs and hosts. See Built-in Lua functions for documentation on how to use the built-in health functions. Note that these health check functions can also be used for making routing conditions in the routing tree.
Routing Based on Cache Metrics
Instead of using health check functions to incorporate hardware metrics into the routing decisions, regular routing conditions can be used.
As an example, using the health check function cpu_load_ok() in routing can be
configured as follows:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: firstMatch
Adding a 'firstMatch' element
rule : {
name (default: ): dont_overload_cache
type (default: firstMatch):
targets : [
target : {
onMatch (default: ): default_host
condition (default: always()): cpu_load_ok()
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): offload_host
condition (default: always()):
}
Add another 'target' element to array 'targets'? [y/N]: n
]
}
Add another 'rule' element to array 'rules'? [y/N]: n
]
Generated config:
{
"rules": [
{
"name": "dont-overload-cache",
"type": "firstMatch",
"targets": [
{
"onMatch": "default_host",
"condition": "cpu_load_ok()"
},
{
"onMatch": "offload_host",
"condition": "always()"
}
]
}
]
}
Merge and apply the config? [y/n]: y
3.2 - Private CDN Offload Routing with DNS
This shows a setup to do DNS based routing and 3rd party CDN offload from a private main CDN. The following components are used in the setup:
- A private CDN with Convoy (ESB3006), Request Router (ESB3008) and SW Streamers (ESB3004)
- ESB3024 Router to offload traffic to an external CDN
- CoreDNS to support DNS based routing using ESB3024
The following figure shows an overview of the different components and how they interact.

A client retrieves a DNS name from it’s content portal. The DNS name is then resolved by CoreDNS that asks the router for a suitable host. The router either returns a host from ESB3008 Request Router or a configured offload host.
The following sequence diagram illustrates the flow.

Follow the links below to configure different use cases of this setup.
3.3 - Token blocking
A common attempt of CDN piracy is to share unique session tokens between multiple users. If your tokens do not encode device identifiers it might be possible for attackers to share a token between multiple devices.
This is a common problem in the industry, and one solution is to block tokens after they have been used. This can be accomplished by storing the used tokens in a central database and checking against that database before allowing a new session to be created.
How it works
AgileTV CDN Director can be configured to produce and consume messages to and from a Kafka broker/cluster, preferably the Kafka cluster deployed by the AgileTV CDN Manager. Utilizing Kafka, the Director can produce Kafka messages containing the used tokens which other Director instances can consume and store locally in selection input.
Configuration
Kafka
The Manager deploys a Kafka cluster that can be used to store used tokens. The
Kafka cluster has a default topic called selection_input that can be used to
store selection input data. This can be verified by running the following command
on the Manager host and checking that the topic selection_input is listed:
kubectl exec acd-manager-kafka-controller-0 -- kafka-topics.sh --bootstrap-server localhost:9092 --list
__consumer_offsets
selection_input
Note that the used tokens can be stored under any Kafka topic, but for this
example we will use the default selection_input topic. If you want to use a
different topic, refer to the Kafka documentation
for more information on how to create a new topic. Note that other services
deployed by the Manager may also use the selection_input topic, so be
careful when using a different topic.
Connecting to the Kafka cluster
All instances of the Director must be configured to connect to the same Kafka
cluster. Assuming that an instance of the Manager is running on the host
manager-host, the Kafka cluster can be accessed through port 9095. The
following configuration will make the Director connect to the Kafka cluster
served by the Manager:
confcli integration.kafka.bootstrapServers
{
"bootstrapServers": [
"manager-host:9095"
]
}
Data streams
To consume and produce messages to and from the Kafka cluster, data streams
are used. Assuming that the Kafka topic selection_input is used to store the used
tokens, the following configuration will make the Director consume messages from
the selection_input topic and store them as selection input data:
confcli services.routing.dataStreams
{
"dataStreams": {
"incoming": [
{
"name": "incomingSelectionInput",
"source": "kafka",
"target": "selectionInput",
"kafkaTopics": [
"selection_input"
]
},
],
"outgoing": [
{
"name": "outgoingSelectionInput",
"type": "kafka",
"kafkaTopic": "selection_input"
}
]
}
}
The incoming section specifies that the Director will consume messages from
the selection_input topic and store them as selection input data. Messages are
consumed periodically and no more configuration is needed.
The outgoing section specifies that the Director will produce messages to the
selection_input topic. The kafkaTopic option specifies the name of the topic
to produce messages to. However, to actually produce messages, we need to
employ a Lua function.
Lua function
The Lua function blocked_tokens.add produces messages
to the Kafka topic. This message will be consumed by other Director instances
configured to consume messages from the selection_input topic and be stored as
selection input data.
During routing we also need to check if the token attached to the request is
blocked and deny the request accordingly. This can be done using the Lua function
blocked_tokens.is_blocked.
These two functions can be utilized in a custom Lua function to check if the token is blocked and produce a message to the Kafka topic if it is not.
Consider a scenario where the token is included in the query string of a request.
The Lua function below checks if the token exists in the query string, retrieves
it, and determines whether it is blocked using blocked_tokens.is_blocked. If
the token is not blocked, it is added to the outgoing data stream with a
time-to-live (TTL) of 1 hour (3600 seconds) using blocked_tokens.add. However,
if the token is blocked, the function returns 1, signaling that the token is
blocked and the request should be blocked.
function is_token_used()
-- This function checks if the token is present in the query string
-- and if it is blocked. If the token is missing or blocked, the function
-- returns 1. If the token has not been blocked, the function returns 0.
-- Verify if the token is present in the query string
local token = request_query_params.token
if token == nil then
-- Token is not present, return 1
return 1
end
-- Check if the token is blocked
if not blocked_tokens.is_blocked(token) then
-- Token is not blocked, add the blocked token to the outgoing data
-- stream with a TTL of 1 hour (3600 seconds)
local ttl_s = 3600
blocked_tokens.add('outgoingSelectionInput', token, ttl_s)
return 0
else
-- Token is blocked, return 1
return 1
end
end
Save this function in a file called is_token_used.lua and upload it to the
Director using the Lua API.
When the function has been uploaded to the Director, it can be used in a deny
rule block to fully handle all token blocking:
confcli services.routing.rules
{
"rules": [
{
"name": "checkTokenRule",
"type": "deny",
"condition": "is_token_used()",
"onMiss": "someOtherRule"
}
]
}
This rule will call the function is_token_used() for every request. If the
token is missing or blocked, the function will return 1 and the request will be
denied. If the token is not blocked, the function will add the token to the
outgoing data stream to block it for future use and return 0, allowing the
request to continue to the next rule in the chain, which is someOtherRule in
this case.
3.4 - Monitor ACD with Prometheus, Grafana and Alert Manager
ACD can be monitored with standard monitoring solutions. This allows you to adapt the monitoring to your needs. The following shows a setup with the following components
- Prometheus as metrics database
- Grafana to create Dashboards
- Alert Manager to create alarms from Prometheus alerts

Prometheus and Grafana can also be installed with ESB3024 Router installer in which case Grafana is also pre-populated with standard routing dashboards as well as the router troubleshooting Dashboards.
4 - Use Cases
4.1 - Route on GeoIP/ASN
This page describes how to write configuration for GeoIP and ASN-based routing. For configuration in general, see Configuration.
To be able to do geographic based routing, the Director needs geographic location databases. See Geographic Databases for more information.
For more details on session groups and classifiers, see Session Groups and Classification.
ASN
Routing on ASN is done through a combination of session group classifiers and Lua script weight functions. We need to create ASN classifier(s) and then associate them with a session group:
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: geoip
Adding a 'geoip' element
classifier : {
name (default: ): allowed_asn_classifier
type (default: geoip): ⏎
inverted (default: False): ⏎
continent (default: ): ⏎
country (default: ): ⏎
cities : [
city (default: ): ⏎
Add another 'city' element to array 'cities'? [y/N]: ⏎
]
asn (default: ): Agile*ISP
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "allowed_asn_classifier",
"type": "geoip",
"inverted": false,
"continent": "",
"country": "",
"cities": [],
"asn": "Agile*ISP"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): allowed_asn
classifiers : [
classifier (default: ): allowed_asn_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "allowed_asn",
"classifiers": [
"allowed_asn_classifier"
]
}
]
}
Merge and apply the config? [y/n]: y{
"session_groups": [
{
"id": 1,
"name": "allowed_asn",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_asn_classifier",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"asn": "Agile*ISP"
}
}
]
]
}
]
}The asn value is a string, matching an ISP name or similar. It supports
wildcard matching using asterisks and is case insensitive.
Note that each ASN classifier has to be in its own list. This is because classifiers within the same inner list all have to match for the entire list to be true, and that is impossible for classifiers that match against different ASNs. When the classifiers are in their own lists, it’s enough that one of them matches for the outer classifier list to also match.
Simple Example
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): asn_split_node
type (default: split): ⏎
rule (default: ): return in_session_group("allowed_asn")
onMatch (default: ): allowed-asn-host
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "asn_split_node",
"type": "split",
"condition": "in_session_group('allowed_asn')",
"onMatch": "allowed-asn-host",
"onMiss": "offload-host"
}
]
}
Merge and apply the config? [y/n]: y{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"session_groups": [
{
"id": 1,
"name": "allowed_asn",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_asn_classifier_agile",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"asn": "Agile*ISP"
}
}
],
[
{
"id": 1,
"inverted": false,
"name": "allowed_asn_classifier_edgeware",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"asn": "Edgeware *"
}
}
]
]
}
],
"cdns": [
{
"id": "basic-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "default-host",
"cdn_id": "basic-cdn",
"address_family": "ipv4",
"host": "cdn-host.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"address_family": "ipv4",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "default-node",
"host-id": "default-host",
"weight_function": "return in_session_group('allowed_asn')"
},
{
"id": "offload-node",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
}
}Geographical Location
Routing on geographical location is done in a similar fashion. Once again, we create location classifier(s) and associate them with a session group:
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: geoip
Adding a 'geoip' element
classifier : {
name (default: ): allowed_location
type (default: geoip): ⏎
inverted (default: False): ⏎
continent (default: ): ⏎
country (default: ): ⏎
cities : [
city (default: ): stockholm
Add another 'city' element to array 'cities'? [y/N]: ⏎
]
asn (default: ): ⏎
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "allowed_location",
"type": "geoip",
"inverted": false,
"continent": "",
"country": "",
"cities": [
"stockholm"
],
"asn": ""
}
]
}
Merge and apply the config? [y/n]: y "session_groups": [
{
"id": 1,
"name": "allowed_location",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_location_classifier",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"continent": "",
"country": "",
"region": "",
"cities": ["stockholm"]
}
}
]
]
}
]At least one of the optional fields continent, country, region and
cities are required. The classifier matches a request when all specified
fields do (for the cities list, one matching member is sufficient). All
values support wildcard matching using asterisks and are case insensitive.
Note that each location classifier has to be in its own list. This is because classifiers within the same inner list all have to match for the entire list to be true, and that is impossible for classifiers that match against different locations. When the classifiers are in their own lists, it’s enough that one of them matches for the outer classifier list to also match.
Simple Example
confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): geographic_location_split_node
type (default: split): ⏎
rule (default: ): return in_session_group("allowed_location")
onMatch (default: ): allowed-location-host
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "geographic_location_split_node",
"type": "split",
"condition": "in_session_group('allowed_location')",
"onMatch": "allowed-location-host",
"onMiss": "offload-host"
}
]
}
Merge and apply the config? [y/n]: y{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"session_groups": [
{
"id": 1,
"name": "allowed_location",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_location_classifier_sweden",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"country": "Sweden"
}
}
],
[
{
"id": 1,
"inverted": false,
"name": "allowed_location_classifier_oslo",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"country": "Norway",
"cities": ["Oslo"]
}
}
]
]
}
],
"cdns": [
{
"id": "basic-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "default-host",
"cdn_id": "basic-cdn",
"address_family": "ipv4",
"host": "cdn-host.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"address_family": "ipv4",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "default-node",
"host_id": "default-host",
"weight_function": "return in_session_group('allowed_location')"
}
{
"id": "offload-node",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
}
}4.2 - Route on Subnet
This page describes how to write configuration for subnet-based routing. For configuration in general, see Configuration.
For details on the subnets API, see Subnets API.
Subnet-based routing can be done either by using session groups and classifiers or by using the subnets API, allowing large amounts of named subnets.
Session Group Classifiers
Routing on subnets can be done through a combination of session group classifiers and Lua script weight functions. Configuring session groups and classifiers based on subnets and using them in routing may look like:
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: ipranges
Adding a 'ipranges' element
classifier : {
name (default: ): ip_ranges_classifier
type (default: ipranges): ⏎
inverted (default: False): ⏎
ipranges : [
iprange (default: ): 10.0.0.0/8
Add another 'iprange' element to array 'ipranges'? [y/N]: y
iprange (default: ): 192.168.0.0/16
Add another 'iprange' element to array 'ipranges'? [y/N]: y
iprange (default: ): 2001:0db8:85a3::/128
Add another 'iprange' element to array 'ipranges'? [y/N]: ⏎
]
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "ip_ranges_classifier",
"type": "ipranges",
"inverted": false,
"ipranges": [
"10.0.0.0/8",
"192.168.0.0/16",
"2001:0db8:85a3::/128"
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): allowed_subnets
classifiers : [
classifier (default: ): ip_ranges_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "allowed_subnets",
"classifiers": [
"ip_ranges_classifier"
]
}
]
}
Merge and apply the config? [y/n]: y{
"session_groups": [
{
"id": 1,
"name": "allowed_subnets",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_subnet_classifier",
"rule": {
"rule_type": "ip_ranges_rule",
"source": "session/client_ip",
"ip_ranges": ["10.0.0.0/8", "192.168.0.0/16", "2001:0db8:85a3::/128"]
}
}
]
]
}
]
}The field ip_ranges is a list of CIDR-notation strings, supporting both IPv4
and IPv6 format. Incoming requests have their IP tested against the listed
ranges. The classifier evaluates as true if any of the ranges in the
classifier’s list matches the IP address of the request.
These session groups can then be used in routing as follows:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): subnet_split_node
type (default: split): ⏎
rule (default: ): return in_session_group('allowed_subnets')
onMatch (default: ): allowed-host
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "subnet_split_node",
"type": "split",
"condition": "in_session_group('allowed_subnets')",
"onMatch": "allowed-host",
"onMiss": "offload-host"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.entrypoint subnet_split_node
services.routing.entrypoint = 'subnet_split_node'{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"cdns": [
{
"id": "allowed-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "allowed-host",
"cdn_id": "allowed-cdn",
"host": "allowed-host.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "allowed-node",
"host_id": "allowed-host",
"weight_function": "return in_session_group('allowed_subnets')"
},
{
"id": "offload-node",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
},
"session_groups": [
{
"id": 1,
"name": "allowed_subnets",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "allowed_subnet_classifier",
"rule": {
"rule_type": "ip_ranges_rule",
"source": "session/client_ip",
"ip_ranges": ["10.0.0.0/8", "192.168.0.0/16", "2001:0db8:85a3::/128"]
}
}
]
]
}
]
}Named Subnets
Named subnets are injected into the router in the form of JSON payloads to the Subnets API. Once the subnet data has been fed to the router, Lua functions can access the subnet name associated with an incoming request and use the result when it performs routing.
Note that confcli cannot be used to inject named subnets into the router.
Assume we have injected the following subnet configuration into the router:
{
"10.0.0.0/8": "test_net_4",
"192.168.0.0/16": "test_net_4",
"2001:0db8:85a3::/128": "test_net_6"
}
A router configuration using this subnet configuration can then be constructed as:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: split
Adding a 'split' element
rule : {
name (default: ): subnet_split_node
type (default: split): ⏎
rule (default: ): in_subnet('test_net_4')
onMatch (default: ): allowed-host-4
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "subnet_split_node",
"type": "split",
"condition": "in_subnet('test_net_4')",
"onMatch": "allowed-host-4",
"onMiss": "offload-host"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.entrypoint subnet_split_node
services.routing.entrypoint = 'subnet_split_node'{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"cdns": [
{
"id": "allowed-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "allowed-host-4",
"cdn_id": "allowed-cdn",
"address_family": "ipv4",
"host": "allowed-host4.example"
},
{
"id": "allowed-host-6",
"cdn_id": "allowed-cdn",
"address_family": "ipv6",
"host": "allowed-host6.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"address_family": "ipv4",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "allowed-node-4",
"host_id": "allowed-host-4",
"weight_function": "return in_subnet('test_net_4')"
},
{
"id": "allowed-node-6",
"host_id": "allowed-host-6",
"weight_function": "return in_subnet('test_net_6')"
},
{
"id": "offload-node",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
}
}Note the absence of session groups in this configuration, instead relying solely on the named subnet API to making routing decisions based on subnets.
4.3 - Route on Content Type
This page describes how to write configuration for content-based routing. For configuration in general, see Configuration.
Two ways to route on content type will be demonstrated: content path based
and hostname based using session groups and classifiers. For more details on
session groups and classifiers, see
Session Groups and Classification.
Content Path
Routing on content path is done through a combination of session group
classifiers and Lua script weight functions. Two suitable classifiers for
content path matching are string_match_rule and regex_rule.
The pattern is a string matching the path segment of a request URL, including
the file name. When selecting the string_match_rule type, use asterisks for
wildcard matching. When selecting the regex_rule follow the C++11 std::regex
ECMAScript
syntax to make valid patterns. Make sure to write patterns that match the
entire path segment, not just part of it.
Note that each content classifier normally has to be in its own list. This is because classifiers within the same inner list all have to match for the entire list to be true, and that is impossible for classifiers that match against different content paths. When the classifiers are in their own lists, it’s enough that one of them matches for the outer classifier list to also match.
Simple Example
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlPath
Adding a 'contentUrlPath' element
classifier : {
name (default: ): live_content_classifier
type (default: contentUrlPath): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *live_tv*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: y
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlPath
Adding a 'contentUrlPath' element
classifier : {
name (default: ): news_content_classifier
type (default: contentUrlPath): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): regex
pattern (default: ): /([^/]+/)?news_reports_\\d+/.*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: y
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlPath
Adding a 'contentUrlPath' element
classifier : {
name (default: ): hls_content_classifier
type (default: contentUrlPath): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *.m3u8
}
Add another 'classifier' element to array 'classifiers'? [y/N]: n
]
Generated config:
{
"classifiers": [
{
"name": "live_content_classifier",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*live_tv*"
},
{
"name": "news_content_classifier",
"type": "contentUrlPath",
"inverted": false,
"patternType": "regex",
"pattern": "/([^/]+/)?news_reports_\\\\d+/.*"
},
{
"name": "hls_content_classifier",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*.m3u8"
}
]
}
Merge and apply the config? [y/n]: y
confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): live_content
classifiers : [
classifier (default: ): live_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: y
sessionGroup : {
name (default: ): news_content
classifiers : [
classifier (default: ): news_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: y
sessionGroup : {
name (default: ): hls_content
classifiers : [
classifier (default: ): hls_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "live_content",
"classifiers": [
"live_content_classifier"
]
},
{
"name": "news_content",
"classifiers": [
"news_content_classifier"
]
},
{
"name": "hls_content",
"classifiers": [
"hls_content_classifier"
]
}
]
}
Merge and apply the config? [y/n]: y{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"session_groups": [
{
"id": 1,
"name": "live_content",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "live_content_classifier",
"rule": {
"rule_type": "string_match_rule",
"source": "session/content_url_path",
"pattern": "*live_tv*"
}
}
]
],
[
[
{
"id": 2,
"inverted": false,
"name": "news_content_classifier",
"rule": {
"rule_type": "regex_rule",
"source": "session/content_url_path",
"pattern": "/([^/]+/)?news_reports_\\d+/.*"
}
}
]
]
},
{
"id": 2,
"name": "hls_content",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "hls_content_classifier",
"rule": {
"rule_type": "string_match_rule",
"source": "session/content_url_path",
"pattern": "*.m3u8"
}
}
]
]
}
],
"cdns": [
{
"id": "live-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "vod-hls-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "vod-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "live-host",
"cdn_id": "live-cdn",
"address_family": "ipv4",
"host": "live-host.example"
},
{
"id": "vod-hls-host",
"cdn_id": "vod-hls-cdn",
"address_family": "ipv4",
"host": "vod-hls-host.example"
},
{
"id": "vod-host",
"cdn_id": "vod-cdn",
"address_family": "ipv4",
"host": "vod-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "live-node",
"host_id": "live-host",
"weight_function": "return session_groups.live_content and 1 or 0"
},
{
"id": "vod-hls-node",
"host_id": "vod-hls-host",
"weight_function": "return session_groups.hls_content and 1 or 0"
},
{
"id": "vod-node",
"host_id": "vod-host",
"weight_function": "return 1"
}
]
}
}Hostname
In cases where there are separate domain or subdomain names for different content types, it’s simple to make classifiers that filter on those names.
The pattern is a string matching the hostname segment of a request URL,
including the file name. When selecting the string_match_rule type, use
asterisks for wildcard matching. When selecting the regex_rule follow the
C++11 std::regex
ECMAScript
syntax to make valid patterns. Make sure to write patterns that match the
entire hostname segment, not just part of it.
Note that each hostname classifier has to be in its own list. This is because classifiers within the same inner list all have to match for the entire list to be true, and that is impossible for classifiers that match against different hostnames. When the classifiers are in their own lists, it’s enough that one of them matches for the outer classifier list to also match.
Simple Example
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: hostName
Adding a 'hostName' element
classifier : {
name (default: ): live_content_classifier
type (default: hostName): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): live.example.com
}
Add another 'classifier' element to array 'classifiers'? [y/N]: y
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: hostName
Adding a 'hostName' element
classifier : {
name (default: ): news_content_classifier
type (default: hostName): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): regex
pattern (default: ): /([^\\.]+/)\\.news_reports_\\d+/\\.example\\.com
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "live_content_classifier",
"type": "hostName",
"inverted": false,
"patternType": "stringMatch",
"pattern": "live.example.com"
},
{
"name": "news_content_classifier",
"type": "hostName",
"inverted": false,
"patternType": "regex",
"pattern": "/([^\\\\.]+/)\\\\.news_reports_\\\\d+/\\\\.example\\\\.com"
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): live_content
classifiers : [
classifier (default: ): live_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: y
sessionGroup : {
name (default: ): news_content
classifiers : [
classifier (default: ): news_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: y
sessionGroup : {
name (default: ): hls_content
classifiers : [
classifier (default: ): hls_content_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "live_content",
"classifiers": [
"live_content_classifier"
]
},
{
"name": "news_content",
"classifiers": [
"news_content_classifier"
]
},
{
"name": "hls_content",
"classifiers": [
"hls_content_classifier"
]
}
]
}{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"session_groups": [
{
"id": 1,
"name": "live_content",
"classifiers": [
[
{
"id": 1,
"inverted": false,
"name": "live_content_classifier",
"rule": {
"rule_type": "string_match_rule",
"source": "session/hostname",
"pattern": "live.example.com"
}
}
],
[
{
"id": 2,
"inverted": false,
"name": "news_content_classifier",
"rule": {
"rule_type": "regex_rule",
"source": "session/hostname",
"pattern": "/([^\\.]+/)\\.news_reports_\\d+/\\.example\\.com"
}
}
]
]
}
],
"cdns": [
{
"id": "live-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "vod-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "live-host",
"cdn_id": "live-cdn",
"address_family": "ipv4",
"host": "live-host.example"
},
{
"id": "vod-host",
"cdn_id": "vod-cdn",
"address_family": "ipv4",
"host": "vod-host.example"
}
],
"routing": {
"id": "routing_table",
"member_order": "sequential",
"members": [
{
"id": "live-node",
"host_id": "live-host",
"weight_function": "return session_groups.live_content and 1 or 0"
},
{
"id": "vod-node",
"host_id": "vod-host",
"weight_function": "return 1"
}
]
}
}Using the Session Groups in Confcli
The constructed session groups can be used in routing by creating a rule that references them:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: firstMatch
Adding a 'firstMatch' element
rule : {
name (default: ): classifier_routing_rule
type (default: firstMatch): ⏎
targets : [
target : {
onMatch (default: ): live-host
rule (default: ): in_all_session_groups('live_content', 'news_content')
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): vod-hls-host
rule (default: ): in_session_group('hls_content')
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): offload-host
rule (default: ): always()
}
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "classifier_routing_rule",
"type": "firstMatch",
"targets": [
{
"onMatch": "live-host",
"condition": "in_all_session_groups('live_content', 'news_content')"
},
{
"onMatch": "vod-hls-host",
"condition": "in_session_group('hls_content')"
},
{
"onMatch": "offload-host",
"condition": "always()"
}
],
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.entrypoint classifier_routing_rule
services.routing.entrypoint = classifier_routing_rule
4.4 - Route on Content Popularity
This page describes how to write configuration for content popularity routing. For configuration in general, see Configuration.
For more details on content popularity tuning and routing, see
Content Popularity
The router tracks content popularity which can be utilized for routing.
Using the configuration tool confcli, creating a content popularity based
routing configuration for hierarchical and multi-edge scenarios will be
demonstrated.
Hierarchical
Consider a CDN setup with edge streamers that has cached popular content and a central streamer where all content is available. You can decide where to route clients based on the requested content’s popularity.
Assuming that appropriate streamer hosts have already been configured, configuration will look like:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: contentPopularity
Adding a 'contentPopularity' element
rule : {
name (default: ): contentPopularityHierarchy
type (default: contentPopularity): ⏎
popularityThreshold (default: 10): 2000
onPopular (default: ): edgeStreamer
onUnpopular (default: ): centralStreamer
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "contentPopularityHierarchy",
"type": "contentPopularity",
"popularityThreshold": 2000.0,
"onPopular": "edgeStreamer",
"onUnpopular": "offloadStreamer"
}
]
}
Merge and apply the config? [y/n]: y
where name is the name of the rule, isPopular is the rule to route to if
the content is popular, otherwise the rule isUnpopular is routed to. Lastly,
popularityThreshold is the threshold for which content is considered popular.
Configuring popularityThreshold = 2001 means that the top 2000 most popular
assets will be routed to edgeStreamer.
The rule contentPopularityHierarchy can then be used to construct your routing
tree.
Multi-Edge
Consider a CDN setup with three edge streamers, edge1, edge2 and
edge3, configured to cache very popular content, mildly popular content
and unpopular content respectively. Assuming that appropriate streamer
hosts have already been configured, the following configuration can be used for
correctly routing a request in this scenario:
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: contentPopularity
Adding a 'contentPopularity' element
rule : {
name (default: ): mildlyAndUnpopular
type (default: contentPopularity): ⏎
popularityThreshold (default: 10): 2001
onPopular (default: ): edge2
onUnpopular (default: ): edge3
}
Add another 'rule' element to array 'rules'? [y/N]: y
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: contentPopularity
Adding a 'contentPopularity' element
rule : {
name (default: ): multiLevelPopularity
type (default: contentPopularity): ⏎
popularityThreshold (default: 10): 101
onPopular (default: ): edge1
onUnpopular (default: ): mildyAndUnpopular
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "mildlyAndUnpopular",
"type": "contentPopularity",
"popularityThreshold": 2001.0,
"onPopular": "edge2",
"onUnpopular": "edge3"
},
{
"name": "multiLevelPopularity",
"type": "contentPopularity",
"popularityThreshold": 101.0,
"onPopular": "edge1",
"onUnpopular": "mildyAndUnpopular"
}
]
}
Merge and apply the config? [y/n]: y
By configuring a rule to route to multiLevelPopularity,
this configuration will route requests for the top 100 most popular content
to edge1, popularity ranking 101-2000 to edge2 and popularity
ranking > 2000 to edge3. Since the contentPopularity rule offers a binary
routing choice of either isPopular or isUnpopular, multiple
contentPopularity rules can be utilized to construct multi-leveled content
popularity based routing configurations.
Application
To use any of these two configurations in your installation, you’ll need to
configure either a rule or the entrypoint to route to either
multiLevelPopularity or contentPopularityHierarchy.
4.5 - Route on Selection Input
This page describes how to write configuration for routing on bandwidth usage or number of ongoing sessions in AgileTV CDN:s by using the selection input API. For configuration in general, see Configuration.
For more details on the selection input API, see Selection Input.
Selection Input
The selection input API allows you to inject custom data, that can be used during routing, into the router. For this use case, we will use CDN bandwidth and the number of ongoing sessions to demonstrate the capabilities of the selection input API.
Imagine that we have a monitor constantly polling the bandwidth and ongoing sessions of hosts in a CDN. These values are injected into the selection input API as JSON packets:
{
"edge-host-available-bps": 1000000000,
"edge-host-ongoing-sessions": 300
}
These keys will end up in the router Lua context as “selection inputs”, arbitrary values or JSON objects that can be used to calculate routing weights.
The selection input variable edge-host-available-bps will be available
through either selection_input.edge-host-available-bps or
si('edge-host-available-bps'). The function si(si_var)
fetches the selection input value if it exists, otherwise it returns 0.
However, when comparing selection input variables with numbers, there are a
number of built-in Lua functions that will simplify things, such as gt() and
lt(). For a complete list and more details on these functions, see
Built-in Functions.
Simple Example
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: firstMatch
Adding a 'firstMatch' element
rule : {
name (default: ): selection-input-routing
type (default: firstMatch): ⏎
targets : [
target : {
onMatch (default: ): edge-host
rule (default: ): lt('edge_host_ongoing_sessions', 1000)
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): edge-host
rule (default: ): gt('edge_host_available_bps', 5000000)
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): offload-host
rule (default: ): always()
}
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "selection-input-routing",
"type": "firstMatch",
"targets": [
{
"onMatch": "edge-host",
"condition": "lt('edge_host_ongoing_sessions', 1000)"
},
{
"onMatch": "edge-host",
"condition": "gt('edge_host_available_bps', 5000000)"
},
{
"onMatch": "offload-host",
"condition": "always()"
}
]
}
]
}
Merge and apply the config? [y/n]: y
$ confcli services.routing.entrypoint selection-input-routing
services.routing.entrypoint = 'selection-input-routing'{
"content_server": {
"http_enable": true,
"http_port": 80,
"https_enable": true,
"https_port": 443
},
"cdns": [
{
"id": "edge-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "edge-host",
"cdn_id": "edge-cdn",
"host": "edge-host.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing-table",
"member_order": "sequential",
"members": [
{
"id": "edge-host-sessions-available",
"host_id": "edge-host",
"weight_function": "return (lt('edge_host_ongoing_sessions', 1000) ~= 0) and 1 or 0"
},
{
"id": "edge-host-bandwith-available",
"host_id": "edge-host",
"weight_function": "return (gt('edge_host_available_bps', 5000000) ~= 0) and 1 or 0"
},
{
"id": "offload",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
}
}4.6 - Adapt to multi-CDN
This page describes how to write configuration for setups that require the URL sent back to the client to be rewritten based on routing results, for example by adding a token to the path or as a query string parameter. For configuration in general, see Configuration.
In order to change the redirect location URL, we need to add a response translation function to the confd configuration. By default, all translation functions are empty:
$ confcli services.routing.translationFunctions
{
"translationFunctions": {
"request": "",
"response": ""
}
}
For full documentation of the response translation function, please see Lua Hooks.
Simple Example
Translation functions tend to become large, which makes it hard to write
them inside a single string. Instead, the function can be written in a separate
.lua script file that is uploaded to the router and referenced from the
confd configuration.
The following example will take this approach, adding a script called
"rewrite.lua" to the configured custom Lua folder /tmp/custom_lua on
the router. For more information see the Configuration JSON Overview.
Lua Script
The following script assumes the existence of the function parse_url that
returns an object with URL segments that can be altered and then combined into
a URL string using the tostring(obj) function again.
Beware that the router does not validate the URL in the Location header, it is up to the Lua script writer to ensure that only URLs are returned.
function response_rewrite(Headers)
-- The live server has the token as part of the path, added first before the
-- path from the request.
local location = parse_url(response_headers.location)
if location.host == "live-host.example" then
location.path = "/live-prefix" .. location.path
return HTTPResponse(
{
Headers = {
{"location", tostring(location)}
}
}
)
end
-- The VOD server expects the token as a query string rather than as part
-- of the path segment.
-- Since VOD can be used for offload, check that session_groups.is_vod
-- is set as well.
if location.host == "vod-host.example" and session_groups.is_vod then
location.query["token"] = md5sum(secret_key .. request.path)
return HTTPResponse(
{
Headers = {
{"location", tostring(location)}
}
}
)
end
-- If the request was neither in the is_live session group, nor contained
-- the path element "vod", we return a nil object to indicate that we don't
-- want to change anything in the response.
return nil
end
Configuration
To configure a response translation function using with the custom Lua function
response_rewrite() using confcli, run the command:
$ confcli services.routing.translationFunctions.response 'return response_rewrite()'
services.routing.translationFunctions.response = 'return response_rewrite()'
An example confd configuration utilizing this translation function based on
session groups would look like this:
$ confcli services.routing
{
"translationFunctions": {
"request": "",
"response": "return response_rewrite()"
},
"sessionGroups": [
{
"name": "is_live",
"classifiers": [
"is_live_classifier"
]
},
{
"name": "is_vod",
"classifiers": [
"is_vod_classifier"
]
}
],
"classifiers": [
{
"name": "is_live_classifier",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*/live/*"
},
{
"name": "is_vod_classifier",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*/vod/*"
}
],
"hostGroups": [
{
"name": "live-cdn",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "live-host",
"hostname": "live-host.example",
"ipv6_address": ""
}
]
},
{
"name": "vod-cdn",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "vod-host",
"hostname": "vod-host.example",
"ipv6_address": ""
}
]
}
],
"rules": [
{
"name": "multiCdnExample",
"type": "firstMatch",
"targets": [
{
"condition": "in_session_group('is_live')",
"onMatch": "live-host"
},
{
"condition": "in_session_group('is_vod')",
"onMatch": "vod-host"
},
// Use the vod-host as offload for any content, but don't set any
// token for requests not classified as vod.
{
"condition": "always()",
"onMatch": "vod-host"
}
]
}
],
"entrypoint": "multiCdnExample",
"applyConfig": true
}
4.7 - How to use ACD router for EDNS routing
This page describes how to write configuration for EDNS routing. For configuration in general, see Configuration.
EDNS Routing
In your CDN architecture, you might utilize EDNS routing to redirect clients. Whether it’s your own CDN or a third party CDN, the ESB3024 Router supports creating EDNS requests and sending them to any DNS server.
Configuration
To configure EDNS routing, you first need to create a DNS type host.
Using confcli:
[user@acd-router ~]# confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: dns
Adding a 'dns' element
hostGroup : {
name (default: ): edns-cdn
type (default: dns): ⏎
hosts : [
host : {
name (default: ): edns-host
hostname (default: ): ednshost.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "edns-cdn",
"type": "dns",
"hosts": [
{
"name": "edns-host",
"hostname": "ednshost.com",
"ipv6_address": ""
}
]
}
]
}
Merge and apply the config? [y/n]: y
Note that the hostname is the name of the DNS server that will receive
the EDNS request. You can now use the DNS host when creating the routing tree,
e.g. in a random type rule:
[user@router ~]# confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: random
Adding a 'random' element
rule : {
name (default: ): random-rule
type (default: random): ⏎
targets : [
target (default: ): edns-host
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "random-rule",
"type": "random",
"targets": [
"edns-host"
]
}
]
}
Merge and apply the config? [y/n]: y
[user@router ~]# confcli services.routing.entrypoint random-rule
services.routing.entrypoint = 'random-rule'
Or simply use it as the entrypoint:
confcli services.routing.entrypoint edns-host
4.8 - How to use ESB3024 Router with Orbit Request Router
This page describes how to write configuration for using ESB3024 Router in conjunction with ESB3008 Request Router. It can request a host from an ESB3008 Request Router and forward the response to the client, perform load balancing between several Request Routers and handle fallback to an external CDN in case no Request Routers are able to service the request.
Simple Example
# The tuning parameter `target.requestAttempts` controls the number of attempts
# made to find a host. In this example we want to fallback to the external CDN
# in case both Request Routers are down, so we set it to at least 3.
$ confcli services.routing.tuning.target.requestAttempts 3
services.routing.tuning.target.requestAttempts = 3
# Create a classifier to filter incoming requests from Sweden.
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: geoip
Adding a 'geoip' element
classifier : {
name (default: ): sweden_classifier
type (default: geoip): ⏎
inverted (default: False): ⏎
continent (default: ): ⏎
country (default: ): sweden
cities : [
city (default: ): ⏎
Add another 'city' element to array 'cities'? [y/N]: ⏎
]
asn (default: ): ⏎
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "sweden_classifier",
"type": "geoip",
"inverted": false,
"continent": "",
"country": "sweden",
"cities": [
""
],
"asn": ""
}
]
}
Merge and apply the config? [y/n]: y
# Create a session group for the non-Swedish requests, to use in routing rules
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): sweden
classifiers : [
classifier (default: ): sweden_classifier
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "sweden",
"classifiers": [
"sweden_classifier"
]
}
]
}
Merge and apply the config? [y/n]: y
# The internal CDN uses Orbit Request Routers that return a redirect
# location. The router takes the content from the client request,
# and makes its own request to the Request Router using that same
# content. The returned location is then forwarded to the client.
#
# In case the Request Router responds with an error code, or times out,
# the router will continue traversing the routing tree until a
# successful route is found or the entire tree has been evaluated.
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: redirecting
Adding a 'redirecting' element
hostGroup : {
name (default: ): internal-cdn
type (default: redirecting): ⏎
httpPort (default: 80): ⏎
httpsPort (default: 443): ⏎
headersToForward <A list of HTTP headers to forward to the CDN. (default: [])>: [
headersToForward (default: ): ⏎
Add another 'headersToForward' element to array 'headersToForward'? [y/N]: ⏎
]
allowAnyRedirectType (default: False): ⏎
hosts : [
host : {
name (default: ): internal-host-1
hostname (default: ): internal-host-1.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: y
host : {
name (default: ): internal-host-2
hostname (default: ): internal-host-2.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "internal-cdn",
"type": "redirecting",
"httpPort": 80,
"httpsPort": 443,
"headersToForward": [],
"allowAnyRedirectType": false,
"hosts": [
{
"name": "internal-host-1",
"hostname": "internal-host-1.example.com",
"ipv6_address": ""
},
{
"name": "internal-host-2",
"hostname": "internal-host-2.example.com",
"ipv6_address": ""
}
]
}
]
}
Merge and apply the config? [y/n]: y
# The offload CDN is non-redirecting, meaning that router does not
# make any request to its associated hosts to ask for a redirect location
# to forward to the clients, instead it simply returns a location using
# one of the CDN's hosts substituted for the router's host in the
# client request possibly with some kind of respsonse translation to add
# e.g. tokens or path prefixes.
$ confcli services.routing.hostGroups -w
Running wizard for resource 'hostGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
hostGroups : [
hostGroup can be one of
1: dns
2: host
3: redirecting
Choose element index or name: host
Adding a 'host' element
hostGroup : {
name (default: ): offload-cdn
type (default: host): ⏎
httpPort (default: 80): ⏎
httpsPort (default: 443): ⏎
hosts : [
host : {
name (default: ): offload-host
hostname (default: ): offload-host.example.com
ipv6_address (default: ): ⏎
}
Add another 'host' element to array 'hosts'? [y/N]: ⏎
]
}
Add another 'hostGroup' element to array 'hostGroups'? [y/N]: ⏎
]
Generated config:
{
"hostGroups": [
{
"name": "offload-cdn",
"type": "host",
"httpPort": 80,
"httpsPort": 443,
"hosts": [
{
"name": "offload-host",
"hostname": "offload-host.example.com",
"ipv6_address": ""
}
]
}
]
}
Merge and apply the config? [y/n]: y
# Begin with adding a load balancing route rule between the two internal
# hosts. Let's make internal-host-2 have twice the capacity of
# internal-host-1 by using a weighted rule.
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: weighted
Adding a 'weighted' element
rule : {
name (default: ): balancer
type (default: weighted): ⏎
targets : [
target : {
target (default: ): internal-host-1
weight (default: 100): 1,
rule (default: always()): always()
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
target (default: ): internal-host-2
weight (default: 100): 2,
rule (default: always()): always()
}
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "balancer",
"type": "weighted",
"targets": [
{
"target": "internal-host-1",
"weight": "1",
"rule:": "always()"
},
{
"target": "internal-host-2",
"weight": "2",
"rule:": "always()"
}
]
}
]
}
Merge and apply the config? [y/n]: y
# Make an offload rule to route any traffic not in Sweden to the
# offload CDN.
$ confcli services.routing.rules -w
Running wizard for resource 'rules'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
rules : [
rule can be one of
1: allow
2: consistentHashing
3: contentPopularity
4: deny
5: firstMatch
6: random
7: rawGroup
8: rawHost
9: split
10: weighted
Choose element index or name: firstMatch
Adding a 'firstMatch' element
rule : {
name (default: ): offload
type (default: firstMatch): ⏎
targets : [
target : {
onMatch (default: ): offload-host
rule (default: ): not in_session_group('sweden')
}
Add another 'target' element to array 'targets'? [y/N]: y
target : {
onMatch (default: ): balancer
rule (default: ): in_session_group('sweden')
}
Add another 'target' element to array 'targets'? [y/N]: ⏎
]
onMiss (default: ): offload-host
}
Add another 'rule' element to array 'rules'? [y/N]: ⏎
]
Generated config:
{
"rules": [
{
"name": "offload",
"type": "firstMatch",
"targets": [
{
"onMatch": "offload-host",
"condition": "not in_session_group('sweden')"
},
{
"onMatch": "balancer",
"condition": "in_session_group('sweden')"
}
],
"onMiss": "offload-host"
}
]
}
Merge and apply the config? [y/n]: y{
"tuning": {
// "target_request_attempts" controls the number of attempts to find a host.
// In this example we want to fallback to the external CDN in case both
// Request Routers are down, so we set it to 3.
"target_request_attempts": 3
},
"session_groups": [
{
"id": 1,
"name": "not_sweden",
"classifiers": [
[
{
"id": 1,
"inverted": true,
"name": "not_sweden_classifier",
"rule": {
"rule_type": "geoip_rule",
"source": "session/client_ip",
"country": "Sweden"
}
}
]
]
}
],
"cdns": [
{
"id": "internal-cdn",
"http_port": 80,
"https_port": 443,
// The internal CDN uses Orbit Request Routers that return a redirect
// location. The router takes the content from the client request,
// and makes its own request to the Request Router using that same
// content. The returned location is then forwarded to the client.
//
// In case the Request Router responds with an error code, or times out,
// the router will continue traversing the routing tree until a
// successful route is found or the entire tree has been evaluated.
"redirecting": true,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
},
{
"id": "offload-cdn",
"http_port": 80,
"https_port": 443,
// The offload CDN is non-redirecting, meaning that router does not
// make any request to its associated hosts to ask for a redirect location
// to forward to the clients, instead it simply returns a location using
// one of the CDN's hosts substituted for the router's host in the
// client request possibly with some kind of respsonse translation to add
// e.g. tokens or path prefixes.
"redirecting": false,
"manifest_availability_check": {
"enabled": false,
"session_group_ids": []
}
}
],
"hosts": [
{
"id": "internal-host-1",
"cdn_id": "internal-cdn",
"address_family": "ipv4",
"host": "internal-host-1.example"
},
{
"id": "internal-host-2",
"cdn_id": "internal-cdn",
"address_family": "ipv4",
"host": "internal-host-2.example"
},
{
"id": "offload-host",
"cdn_id": "offload-cdn",
"address_family": "ipv4",
"host": "offload-host.example"
}
],
"routing": {
"id": "routing_table",
// "sequential" - Go through the rules at this level one by one, and pick
// the first that returns a positive weight.
"member_order": "sequential",
"members": [
{
"id": "reject-node",
"host_id": "offload-host",
// Send filtered-out clients to an offload host.
"weight_function": "return session_groups.not_sweden and 1 or 0"
},
{
"id": "internal_routing",
// Return 1 to make sure this tree is evaluated at all.
"weight_function": "return 1"
// "weighted" - Evaluate all the rules at this level, and pick one of
// them randomly based on their respective weights.
//
// In this example host 1 has half the capacity of host 2, so we just
// randomly route twice as many clients to host 2.
"member_order": "weighted",
"members": [
{
"id": "internal-node-1",
"host_id": "internal-host-1",
// Half the weight of the other host -> half as likely to be picked.
"weight_function": "return 1"
},
{
"id": "internal-node-2",
"host_id": "internal-host-2",
// Twice the weight of the other -> twice as likely to be picked.
"weight_function": "return 2"
}
]
},
{
// Add a non-redirecting offload host as the last target in case all the
// internal redirecting hosts are unavailable or respond with some kind
// of error code.
"id": "offload-node",
"host_id": "offload-host",
"weight_function": "return 1"
}
]
}
}4.9 - How to use ESB3024 Router with CoreDNS
CoreDNS can be configured to work as a DNS server in front of ESB3024 Router. In this mode of operation the client DNS request is terminated by CoreDNS which requests an optimal streaming location from the router.
Contact AgileTV for detailed information on how to set this up, if you don’t already have an AgileTV CDN Solutions Support account please contact us here.
4.10 - How to use the Director as a replacement for Orbit Request Router
This guide outlines how to replicate Convoy’s ESB3008 HTTP Request Router using the Director. This is accomplished using the Convoy Bridge, which is an integration service designed to allow the router and an existing Convoy installation to work together seamlessly.
Following the steps outlined below enables the replacement of existing ESB3008 HTTP Request Router instances with the Director. As of the current documentation, the Director is not a direct substitute for the ESB3008 HTTP Request Router. However, most of the functionality is available, and in the majority of cases, the Director can be used without any loss of functionality.
The purpose of this guide is to detail the process of transitioning from an existing Convoy installation, which includes one or more instances of ESB3008 HTTP Request Router, to a configuration utilizing the Director. This transition allows the existing Convoy installation to continue its role in CDN provisioning, content management, and analytics. Simultaneously, the router assumes responsibility for managing HTTP(S) redirects directly from clients to selected streamers.
One functional difference between ESB3008 HTTP Request Router and the Director is
in communication with the streamer to determine specific interface assignments.
ESB3008 uses a proprietary protocol to communicate with the streamer to help determine
the best interface for the client. For the Director, in order to work with both
streamers and third-party CDNs, the use of the proprietary protocol is not supported,
and the router’s rule engine must be used to accomplish the same result. It is for
this reason that it is recommended to configure each streaming interface as a distinct
host entry in the router’s configuration. This allows the router to address each
interface separately.
Prerequisites
This guide assumes both an existing Convoy installation and a partiality configured
instance of the Director. The router should have all the necessary routing configuration
in place for hostGroups, sessionGroups and routing rules to direct traffic
to the streaming interfaces of the streamers. It is also assumed that the proper
firewall rules are allowing the required traffic between the router, the Convoy
Bridge integration and the Convoy management nodes.
The minimum compatible version of Convoy which can be used with the analytics synchronization feature is Convoy 3.0.0. Previous versions may be used only if Convoy is not being used for analytics.
Firewall Configuration
Proper firewall configuration is required to allow both the router and Convoy to communicate through bidirectional connections established from the Convoy Bridge integration. The Convoy Bridge does not need to be enabled for each router instance, one instance of the Convoy Bridge can synchronize multiple instances of the router simultaneously. Only the router nodes with the Convoy Bridge enabled will need access through the firewall to establish outgoing connections to the Convoy management nodes, or whichever nodes are running MariaDB and Kafka. Additionally, if multiple router instances are to be synchronized by a single Convoy Bridge instance, the firewall must allow the Convoy Bridge to establish connections to each router instance on port 5001.
The following table outlines the necessary connections to be allowed through the firewall.
| Source | Destination | Port | Description |
|---|---|---|---|
| Convoy Bridge | Convoy Management | 3306/TCP | Account Configuration |
| Convoy Bridge | Convoy Management | 9092/TCP | Analytics Data |
| Convoy Bridge | The router | 5001/TCP | Rest API |
Response Translation Functions
In order to have the router generate a redirect URL which is compatible with the
format generated by the ESB3008 HTTP Request Router, a response translation function
must be used to modify the redirect URL before it is returned to the client. A built-in
function convoy_compatibility_response is available to be
used for this purpose. This function appends both the session-id and storage-prefix
based on the account and distribution information in Convoy.
On the Director, set the response translation function as follows:
> confcli services.routing.translationFunctions.response "return convoy_compatibility_response(Headers, '')"
This function depends on the account synchronization feature of the Convoy bridge to
determine the correct storage prefix based on the incoming Host header value. It works
by using the Host header to lookup the storage prefix from the account configuration,
and then modifying the redirect URL to prepend /session/<session-id>/<prefix>. The
streamer can then use this information for both origin selection and session tracking.
Enabling the Convoy Bridge
Before using the Convoy Bridge integration, a valid configuration must first be applied.
All configuration for the Convoy Bridge is available in confd under the key
integration.convoy.bridge. The configuration is divided into three main sections:
The account synchronization feature, the convoy analytics integration, and a list of
additional router instances to synchronize.
By default, the Convoy Bridge will include the current local router instance in the synchronization process. The connection details are hard-wired into the container at startup, and do not need to be specified in the configuration. Because one Convoy Bridge can serve multiple instances of the router, it is not necessary to configure the Convoy Bridge on each node separately. However, if multiple Convoy Bridge instances are used, it is recommended to configure them so that one router is served by multiple instances of the Convoy Bridge. This provides high-availability in a production environment.
As an example, if there are 4 router instances, A, B, C, and D, and 4 Convoy Bridge instances, configuring them such that Bridge 1 synchronizes A & B, 2, synchronizes B & C, 3, synchronizes C & D and 4 synchronizes D & A will provide fault tolerance in the event that one bridge is unavailable.
The account synchronization feature of the Convoy Bridge watches the MariaDB database on the
Convoy management node for changes to the account and distribution configuration, and if
the configuration differs from what is currently known to the router the configuration
will be updated. This feature is required by both the router for use with the
convoy_compatibility_response response translation function, and within the Convoy
Bridge integration for setting the correct account, storage, and distribution fields
with the analytics integration feature.
The analytics integration feature monitors monitors the router’s Event API for
newly established sessions, and produces session-record messages over the Kafka
message broker for use by Convoy. This feature requires that Convoy is both licensed
and configured for use with the analytics feature. The integration works by establishing
a persistent connection to each router, and listening for new session events. Due to the
protocol in use by the Event API to send the events, only one instance of the Convoy
Bridge will have the ability to receive each event, and only that instance will produce
the session-record to the Kafka message brokers.
Synchrnoizing multiple routers with the same instance of the Convoy Bridge is performed
by configuring the otherRouters section of the Convoy Bridge configuration. In addition
to the local router, each otherRouter entry will have the same account and distribution
information updated simultaneously, and will be used as an event source for the analytics
integration. The otherRouters entries require the URL to the router’s Rest API, an
optional API key, and a flag to indicate if SSL certificate validation should be enforced.
Enable the account synchronization feature by running the following command:
> confcli integration.convoy.bridge.accounts -w
Running wizard for resource 'accounts'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
accounts : {
enabled (default: False): true
dbUrl (default: mysql://user:pass@localhost:3306): mysql://convoy:password@convoy-mgmt1:3306
cmsUrl (default: http://localhost:5555): http://convoy-mgmt1:5555
pollInterval (default: 60):
}
Generated config:
{
"accounts": {
"enabled": true,
"dbUrl": "mysql://convoy:password@convoy-mgmt1:3306",
"cmsUrl": "http://convoy-mgmt1:5555",
"pollInterval": 60
}
}
Merge and apply the config? [y/n]:
This will result in the Convoy Bridge continuously polling the Convoy instance running on
convoy-mgmt1 every 60 seconds for changes to the account configuration. Only when the
account configuration differs from the current configuration on the router will it be
updated with the change.
The pollInterval parameter can be used to control how frequently the Convoy Bridge will
attempt to poll the database for changes. Setting this value too high will result in a longer delay
between changes being made in Convoy and the changes being reflected in the router. Setting this
value too low will result in unnecessary load on the Convoy database. The default value of 60 seconds
should be sufficient for most use cases.
To enable the analytics integration feature, run the following command:
> confcli integration.convoy.bridge.analytics -w
Running wizard for resource 'analytics'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
analytics : {
enabled (default: False): true
brokers : [
broker (default: ): convoy-mgmt1:9092
Add another 'broker' element to array 'brokers'? [y/N]: y
broker (default: ): convoy-mgmt2:9092
Add another 'broker' element to array 'brokers'? [y/N]: y
broker (default: ): convoy-mgmt3:9092
Add another 'broker' element to array 'brokers'? [y/N]: n
]
batchInterval (default: 10):
maxBatchSize (default: 500):
}
Generated config:
{
"analytics": {
"enabled": true,
"brokers": [
"convoy-mgmt1:9092",
"convoy-mgmt2:9092",
"convoy-mgmt3:9092"
],
"batchInterval": 10,
"maxBatchSize": 500
}
}
Merge and apply the config? [y/n]:
This will enable the analytics integration, which will produce session-record messages
to the configured Kafka brokers. The brokers configuration list is used to bootstrap the
initial set of brokers which will be contacted by the Convoy Bridge to then obtain the
current set of active brokers. It is not necessary to include all brokers here, as the
initial connection will automatically negotiate the correct broker list.
The batchInterval parameter must be set to a value much less than 60 seconds, since the
streamer will send session-sample messages to Kafka every 60 seconds, and if the
corresponding session-record message is not received within that time, the sample will
be dropped, resulting in potentially inaccurate bandwidth statistics.
> confcli integration.convoy.bridge.otherRouters -w
Running wizard for resource 'otherRouters'
<Other routers which will be kept in sync (default: [])>
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
otherRouters <Other routers which will be kept in sync (default: [])>: [
otherRouter : {
url (default: ): https://router-2:5001
apiKey (default: ): 1234
validateCerts (default: True): false
}
Add another 'otherRouter' element to array 'otherRouters'? [y/N]: y
otherRouter : {
url (default: ): https://router-3:5001
apiKey (default: ):
validateCerts (default: True):
}
Add another 'otherRouter' element to array 'otherRouters'? [y/N]: n
]
Generated config:
{
"otherRouters": [
{
"url": "https://router-2:5001",
"apiKey": "1234",
"validateCerts": false
},
{
"url": "https://router-3:5001",
"apiKey": "",
"validateCerts": true
}
]
}
Merge and apply the config? [y/n]:
4.11 - Use In-Stream Sessions
In-Stream sessions is a routing mode where the router keeps control of the session for the full session lifetime instead of only routing the session to the preferred CDN (or cache node) once. Technically it works by letting the client return to the router for manifest and segments and redirect each segment to the preferred CDN. This enables changing CDN in the middle of a session.
Configure In-Stream Sessions
In-Stream routing for all incoming requests can be enabled by running
$ confcli services.routing.translationFunctions.session "return set_session_type('instream')"
services.routing.translationFunctions.session = "return set_session_type('instream')"
See Session Translation Function for more details on controlling session types.
The following example illustrate the request flow for in-stream session
$ curl -i http://test-acd-router/content/playlist.m3u8
HTTP/1.1 302 Found
Access-Control-Allow-Origin: *
Content-Length: 0
Location: http://test-acd-router/__s/test-acd-router-a4fd86-0000004f_WyIvY2RuL3BsYXlsaXN0Lm0zdTgiLDAsImRldmNkbjEiLCJkZXZjZG4xLnN0cmVhbXBpbG90LnR2Iiw4MCwiL2Nkbi9wbGF5bGlzdC5tM3U4IiwwLDE2ODAyNjQwOTNd_c1e3fc663a47156e0894b30eddf995bb/content/playlist.m3u8
X-Service-Identity:
$ curl -i http://test-acd-router/__s/test-acd-router-a4fd86-0000004f_WyIvY2RuL3BsYXlsaXN0Lm0zdTgiLDAsImRldmNkbjEiLCJkZXZjZG4xLnN0cmVhbXBpbG90LnR2Iiw4MCwiL2Nkbi9wbGF5bGlzdC5tM3U4IiwwLDE2ODAyNjQwOTNd_c1e3fc663a47156e0894b30eddf995bb/content/playlist.m3u8
HTTP/1.1 200 OK
Accept-Ranges: bytes
Access-Control-Allow-Headers: DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range
Access-Control-Allow-Methods: GET, POST, OPTIONS
Access-Control-Allow-Origin: *
Access-Control-Expose-Headers: Content-Length,Content-Range
Connection: keep-alive
Content-Length: 306
Content-Type: application/vnd.apple.mpegurl
Date: Fri, 31 Mar 2023 10:18:42 GMT
ETag: "5d711f08-132"
Last-Modified: Thu, 05 Sep 2019 14:43:20 GMT
Server: nginx/1.14.0 (Ubuntu)
X-Service-Identity:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-STREAM-INF:BANDWIDTH=500000,RESOLUTION=320x180
abr_500k.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1000000,RESOLUTION=640x360
abr_1000k.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1700000,RESOLUTION=1280x720
abr_1700k.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=3300000,RESOLUTION=1280x720
abr_3300k.m3u8
$ curl -i http://test-acd-router/__s/test-acd-router-a4fd86-0000004f_WyIvY2RuL3BsYXlsaXN0Lm0zdTgiLDAsImRldmNkbjEiLCJkZXZjZG4xLnN0cmVhbXBpbG90LnR2Iiw4MCwiL2Nkbi9wbGF5bGlzdC5tM3U4IiwwLDE2ODAyNjQwOTNd_c1e3fc663a47156e0894b30eddf995bb/content/abr_500k.m3u8
HTTP/1.1 200 OK
Accept-Ranges: bytes
Access-Control-Allow-Headers: DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range
Access-Control-Allow-Methods: GET, POST, OPTIONS
Access-Control-Allow-Origin: *
Access-Control-Expose-Headers: Content-Length,Content-Range
Connection: keep-alive
Content-Length: 276
Content-Type: application/vnd.apple.mpegurl
Date: Fri, 31 Mar 2023 12:02:04 GMT
ETag: "6426cbbc-114"
Last-Modified: Fri, 31 Mar 2023 12:02:04 GMT
Server: nginx/1.14.0 (Ubuntu)
X-Service-Identity:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:1
#EXT-X-MEDIA-SEQUENCE:112583846
#EXTINF:0.834444,
abr_500k112583846.ts
#EXTINF:0.834444,
abr_500k112583847.ts
#EXTINF:0.834444,
abr_500k112583848.ts
#EXTINF:0.834444,
abr_500k112583849.ts
#EXTINF:0.834444,
abr_500k112583850.ts
$ curl -i http://test-acd-router/__s/test-acd-router-a4fd86-0000004f_WyIvY2RuL3BsYXlsaXN0Lm0zdTgiLDAsImRldmNkbjEiLCJkZXZjZG4xLnN0cmVhbXBpbG90LnR2Iiw4MCwiL2Nkbi9wbGF5bGlzdC5tM3U4IiwwLDE2ODAyNjQwOTNd_c1e3fc663a47156e0894b30eddf995bb/content/abr_500k112583846.ts
HTTP/1.1 302 Found
Access-Control-Allow-Origin: *
Content-Length: 0
Location: http://testcdn.tv/abr_500k112583846.ts
X-Service-Identity:
A Note on Confcli
Begin with configuring routing, classification and session groups in confcli, for example based on content types.
# Create a classifier for live sessions
$ confcli services.routing.classifiers -w
Running wizard for resource 'classifiers'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
classifiers : [
classifier can be one of
1: anonymousIp
2: asnIds
3: contentUrlPath
4: contentUrlQueryParameters
5: geoip
6: hostName
7: ipranges
8: random
9: regexMatcher
10: requestHeader
11: stringMatcher
12: subnet
13: userAgent
Choose element index or name: contentUrlPath
Adding a 'contentUrlPath' element
classifier : {
name (default: ): live
type (default: contentUrlPath): ⏎
inverted (default: False): ⏎
patternType (default: stringMatch): ⏎
pattern (default: ): *live*
}
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
Generated config:
{
"classifiers": [
{
"name": "live",
"type": "contentUrlPath",
"inverted": false,
"patternType": "stringMatch",
"pattern": "*live*"
}
]
}
Merge and apply the config? [y/n]: y
# Create a session group called "live" using the classifier
$ confcli services.routing.sessionGroups -w
Running wizard for resource 'sessionGroups'
Hint: Hitting return will set a value to its default.
Enter '?' to receive the help string
sessionGroups : [
sessionGroup : {
name (default: ): live
classifiers : [
classifier (default: ): live
Add another 'classifier' element to array 'classifiers'? [y/N]: ⏎
]
}
Add another 'sessionGroup' element to array 'sessionGroups'? [y/N]: ⏎
]
Generated config:
{
"sessionGroups": [
{
"name": "live",
"classifiers": [
"live"
]
}
]
}
Merge and apply the config? [y/n]: y
# Make all sessions belonging to the session group "live" In-Stream sessions
$ confcli services.routing.translationFunctions.session "return set_session_type_if_in_group('instream', 'live')"
services.routing.translationFunctions.session = "return set_session_type_if_in_group('instream', 'live')"
Monitoring
If Grafana is installed together with the ESB-3024 installer, the number of started In-Stream sessions as well as currently active In-Stream sessions can be seen in a Dashboard.
Notes on Performance
Be aware that In-Stream sessions puts additional load on the request router since all clients continuously comes back to the router to fetch new manifests and to get segment redirects. The necessary router capacity therefore scaled both with number of started sessions and the average session length.
5 - Ready for Production?
5.1 - Setup for Redundancy
The Agile Director is designed to support the coexistence of multiple independent instances, facilitating either high-availability and/or horizontal scaling based on specific use cases and requirements. Each instance of the Director operates as a complete isolated entity, offering multiple solutions for redundancy. The choice between these solutions depends on the particular use case and requirements of the deployment.
A few select use-cases and example deployments are described in the sections that follow. Note however that this list is not exhaustive, and other approaches not listed here may be more applicable to a specific use-case.
Third-Party Load Balancer
In this first scenario, multiple instances of the router are positioned behind an off-the-shelf load balancer. This could range from a simple
Nginx
proxy to a more sophisticated commercial load balancer, depending on the user’s specific needs and requirements.
DNS Round Robin
A straightforward alternative to deploying multiple instances of the router behind a load balancer is to employ round-robin DNS. In this approach, each router instance is associated with a distinct A record in DNS, all sharing the same domain name. Clients querying this DNS server receive multiple entries in response. Typically, clients utilize a round-robin algorithm to resolve the IP address of the router, although some clients might randomly select an address from the available servers.
While this method effectively distributes the load across multiple instances, it has a few drawbacks. First, clients are not guaranteed to use any specific algorithm for selecting the IP address. Second, due to DNS caching in the network and on the client’s device, modifications to the DNS record (e.g., taking a node out of service or adding additional nodes) will experience higher latency compared to some other techniques. Third, there is a dependency on the client being able to recognize this DNS server as authoritative. And fourth, this approach does not provide any means of high-availability. If a node is offline, requests to that node will fail.
VRRP
If horizontal scaling is not required, employing a shared Virtual IP Address
through the VRRP protocol may suffice. This can be easily configured on one or
more instances of the router by installing and setting up keepalived. While the
specific details of keepalived are beyond the scope of this document, it can
establish a Primary/Backup node configuration, where heartbeat packets and
server priority determine each node’s role. Using VRRP, a Virtual IP address
always points to the current primary node, and in the event of a primary node
failure, the remaining nodes elect a new primary node based on the predetermined
priority.
This solution has some drawbacks compared to others; the VIP may only be assigned to a single node at a time, rendering horizontal scaling impossible using this solution alone. Another drawback is that if the primary node fails, there will be a brief period, usually around one second, before the failure is detected and the VIP is reassigned.
This solution can be more effectively utilized as part of a larger combined solution in which several groups of nodes are employed. In each group, there is a Primary and Backup, and selection between the groups is handled via one of the other scaling solutions.
An Example Combined Approach Scenario
The following represents an example scenario where eight independent router nodes are utilized employing all three of the above approaches.
The scenario consists of four pairs of nodes, with each pair using VRRP to designate one node as Master and one as a Backup. In front of two pairs of pairs would sit two load balancers, each configured with the VIP address of each pair below. The two load balancers would then be placed into Round Robin DNS with the same FQDN.
Incoming requests would resolve the DNS record, yielding two servers. They would then send requests to each in turn. The load balancer at the end of those IP addresses would then select among the two VIP addresses below, and the request would be routed to the current Primary node in the group.
In this scenario, if any one of the primary nodes becomes offline, the VRRP protocol will move the VIP to the backup node. While that process is ongoing, the load balancer will detect that the VIP is unreachable, routing all traffic in the meantime to the VIP of the second pair. The DNS round-robin would be used to evenly distribute the traffic between the two load balancers.
5.2 - HTTPS Certificates
Configuration of ESB3024 AgileTV CDN Director is done through a REST API over HTTPS. While the router installer generates a self-signed certificate in order to enable the interface at all, this is not considered safe and secure so a properly generated certificate should be used instead.
For SSL to work, the router needs to have both an x509 certificate and a key in ASCII armored PEM format:
-----BEGIN PRIVATE KEY-----
[...]
-----END PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
[...]
-----END CERTIFICATE-----
The files can be either separate .crt and .key files or a combined .pem
file.
Simply copy the file(s) generated by your CA service, into the
/opt/edgeware/acd/ssl folder on the host machine and they will automatically
be used by the Director. Several key/crt pairs can be placed in the folder in
order to support more than one domain name.
Wildcard certificates are supported, so a single certificate can be used for multiple subdomains.
Grafana
Adding HTTPS protection to Grafana is simple. The following ESB3024 Router-specific instructions are based on the official Grafana documentation.
First copy the .crt and .key files to the Grafana container. This will copy
the files into /opt/edgeware/acd/grafana/etc/ but going through podman like
this will ensure the correct ownership of the files so the Grafana process can
properly use them:
podman cp <certificate> grafana:/etc/grafana/
podman cp <key> grafana:/etc/grafana/
Then edit /opt/edgeware/acd/grafana/etc/grafana.ini to enable SSL. Find the
[server] section and set the following values, string values should have no
quotation marks:
protocoltohttpscert_fileto/etc/grafana/<certificate>cert_keyto/etc/grafana/<key>
If any of the specified values have a semicolon (;) before the name, remove
that character or the setting won’t take.
Finally restart the Grafana container:
systemctl restart acd-grafana
Now load up the Grafana web interface at https://<router hostname>:3000 and
verify that SSL is active.